本文主要是介绍【御控物联】 IOT异构数据JSON转化(场景案例一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 在线转换工具
- 技术资料
前言
随着物联网、大数据、智能制造技术的不断发展,越来越多的企业正在进行工厂的智能化转型升级。转型升级第一步往往是设备的智能化改造,助力设备数据快速上云,实现设备数据共享和场景互联。然而,在生产过程中会通过多种数据采集方式产生大量的数据,由于设备的供应商不同,不同的智能设备可能包括不同的数据类型、格式和通信协议等问题,导致智能工厂中设备之间难以互联互通。
1. 多源异构数据来源
工厂中的多源异构数据来自制造资源生产过程中产生的数据,其主要分为两个方面,分别是设备在生产过程中产生的数据和其他制造资源通过数据采集系统产生的数据。
工厂中设备通过加装传感器具备对自身的状态数据感知能力,如数控设备,可以通过内置传感器获取刀具信息、加工信息、故障信息等,并能够对外提供相关数据,实现信息的交互。
然而,不同厂家设备遵循各自的数据标准和通信标准,缺乏统一的标准,使得工厂对多种数据类型和通信协议下的多源异构数据的采集、解码(对外转发数据泛化处理)、编码(内部数据标准化处理)变得十分困难。
2. 多源异构数据感知现状
在复杂的生产环境下,智能工厂边缘侧面临着多源异构数据感知的问题。多源异构数据感知指的是从不同类型的设备或数据采集系统中收集数据,并整合数据。其难点在于多源异构数据的获取和数据的统一化表示。因此,多源异构数据的感知需要通过多种通信协议访问设备或数据采集系统获取数据,并通过标准的数据格式进行表达。
数据感知过程分为两个阶段,分别是数据采集和数据整合。
数据采集阶段将智能工厂边缘侧制造资源通过多种通信协议建立数据连接,在这方面,边缘网关、数据中间件都能够很好的完成数据采集。
数据整合负责将边缘网关、数据中间件上传的数据进行解码(数据格式标准化),然后,再根据不同的数据格式需求进行编码(泛化),实现与工厂业务系统(MES、WMS、等)、物联网平台(阿里、华为、百度、等)的数据对接。在这方面大部分平台通过集成JS(JavaScript)、Lua等脚本解析器,技术人员编写代码实现数据格式转化,不利于业务人员使用。
3. 多源异构数据交互格式现状
通过数采单元获取的设备数据上传至物联平台或业务系统常采用二进制、XML、JSON方式进行传输。
二进制是一种轻量化的数据交互格式,结构简洁,占用网络带宽小,传输效率高,但是不够直观。
XML(Extensible Markup Language,扩展标记语言)是一种“重量级”的数据交换格式,XML格式统一、语法要求严格,标准化程度和可读性都非常高,但占用存储空间大,网络传输慢。
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,结构简洁,解析起来更快,占用的存储空间少,网络传输也较快,是常用的数据交互格式。
本文针对JSON格式的异构数据转化提出了一种面向业务人员转化工具,通过此工具可实现各类JSON数据格式互转,包括数据源键(Key)->目标键(Key) 、数据源键(Key)->目标值(Value) 、数据源值(Value)->目标键(Key)、数据源值(Value)->目标值(Value)。
4. 应用案例
本文结合实际实际案例对JSON数据转化进行讲解。
4.1接入配置
通过御控网关采用MODBUS协议实现PLC数据采集,然后将数据上传至华为云IOT平台,实现数据存储和监控,逻辑图如下:
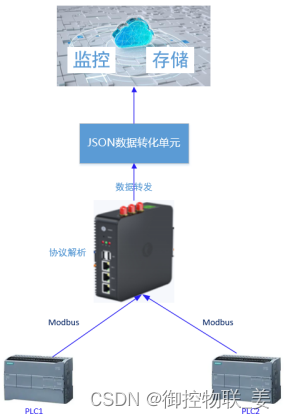
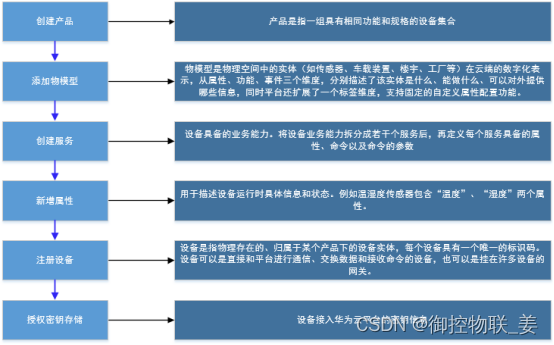
华为云平台:创建产品->维护物模型(服务+属性)->注册设备->保存MQTT接入密钥
御控网关:创建PLC设备监控点表(属性)->配置JSON格式转化->配置MQTT转发信息->华为云IOT平台监控。
御控网关根据PLC设备检测点表维护点表信息,包含名称、数据类型、点位标识、采集方式、采集周期等。

御控网关通过界面维护与华为IOT云平台进行MQTT连接的信息,包括IP、端口、用户名、密码等信息。
御控网关支持数据编码和数据解码两种功能,其中数据编码可以实现将网关封装的标准JSON数据通过映射关系,将转化后的数据发送给华为云平台;数据解码可以将华为云下发的控制指令通过反向映射将JSON数据转化成网关内置标准的JSON。
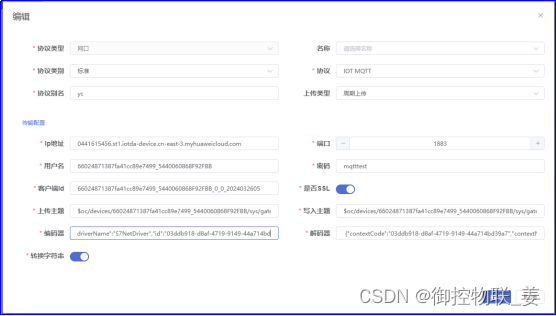
4.2数据转化
其中御控网关采集PLC点表上传的数据格式为:

华为云平台接受的数据格式为:

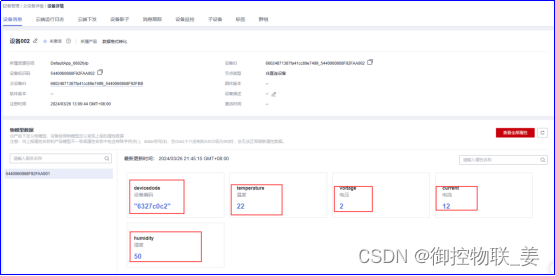
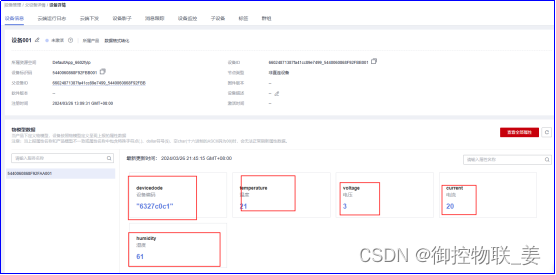
通过JSON数据转化中间件将御控网关上传的“设备编码”、“设备属性值”分别通过数据源键(Key)->目标值(Value)、数据源值(Value)->目标值(Value)两种映射关系实现了数据转化,转化结果如下:
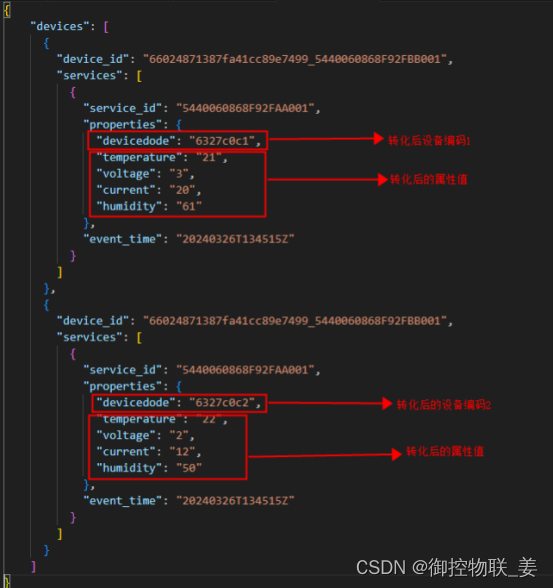
进入华为云平台查看设备实时监控数据,内容如下:
结语
通过JSON数据格式转化工具可方便业务人员快速搭建各业务场景的数据映射,特别适用于物联网网关将数据上传至智能工厂各个业务系统,也支持智能工厂业务系统之间进行数据格式互转的场景,减少业务定制,降低开发成本。
为了更直观体现JSON数据格式转化的功能,特此针对以上场景做了以下DEMO展示。
在线转换工具
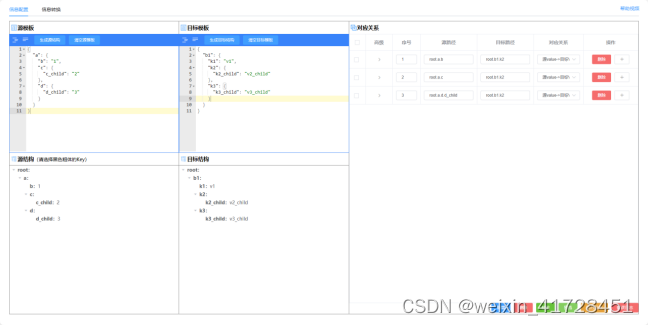
为了让使用者更加方便的配置出映射关系,为此开发了一套在线转换工具,可在工具中通过拖拽即可配置想要的结构转换关系,并可对转换关系所能实现的效果实时进行预览更改。
工具地址:数据转换工具
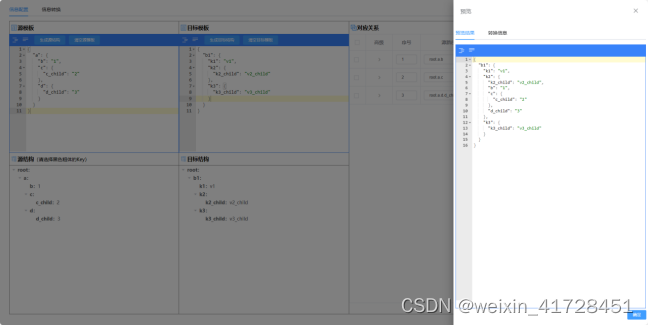
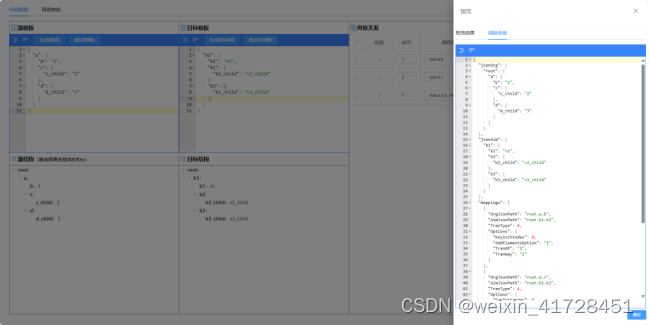
技术资料
- Github:edq-ebara/data-transformation-javascript: 数据转化(javascript) (github.com)
- 技术探讨QQ群:775932762
- 工具连接:数据转换工具
- 御控官网:https://www.yu-con.com/
这篇关于【御控物联】 IOT异构数据JSON转化(场景案例一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




