本文主要是介绍GoogleNet神经网络介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
GoogleNet,也称为GoogLeNet,是谷歌工程师设计的一种深度神经网络结构,它在2014年的ImageNet图像识别挑战赛中取得了冠军。该神经网络的设计特点主要体现在其深度和宽度上,通过引入名为Inception的核心子网络结构,使得网络能够在多个尺度上提取特征,从而增强了其预测能力。
AlexNet与VGG都只有一个输出层
GoogleNet有三个输出层(其中两个为辅助分类器)
二、inception结构
初始结构
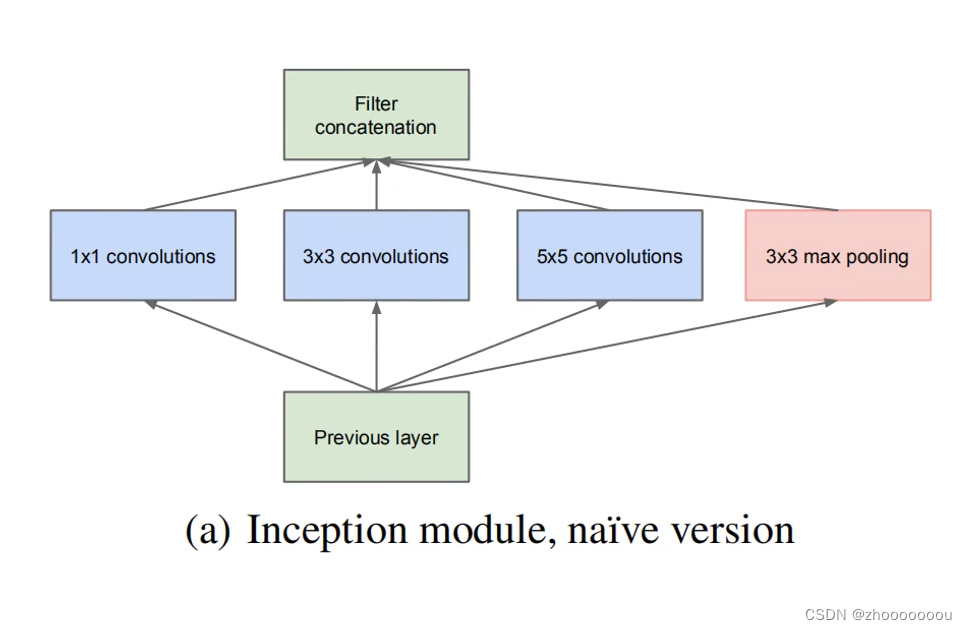
之前的网络,比如AlexNet和VGG都是串行结构:将卷积层、最大池化下采样和全连接层连接起来。
但inception结构所使用的是并行结构:在上一层输出之后,将得到的特征矩阵同时输入到4个分支中进行处理,处理之后,将我们所得到的四个分支的特征矩阵按深度进行拼接得到输出特征矩阵 。
第一个分支是 1x1 大小的卷积核
第二个分支是 3x3 大小的卷积核
第三个分支是 5x5 大小的卷积核
第四个分支是 3x3 大小的池化核的最大池化下采样
通过这四个分支,得到不同尺度的特征矩阵。
ps:每个分支所得的特征矩阵高和宽必须相同,否则无法沿深度方向进行拼接。
降维的inception结构
图中三个黄色方框的 1x1 卷积核起到降维的作用。
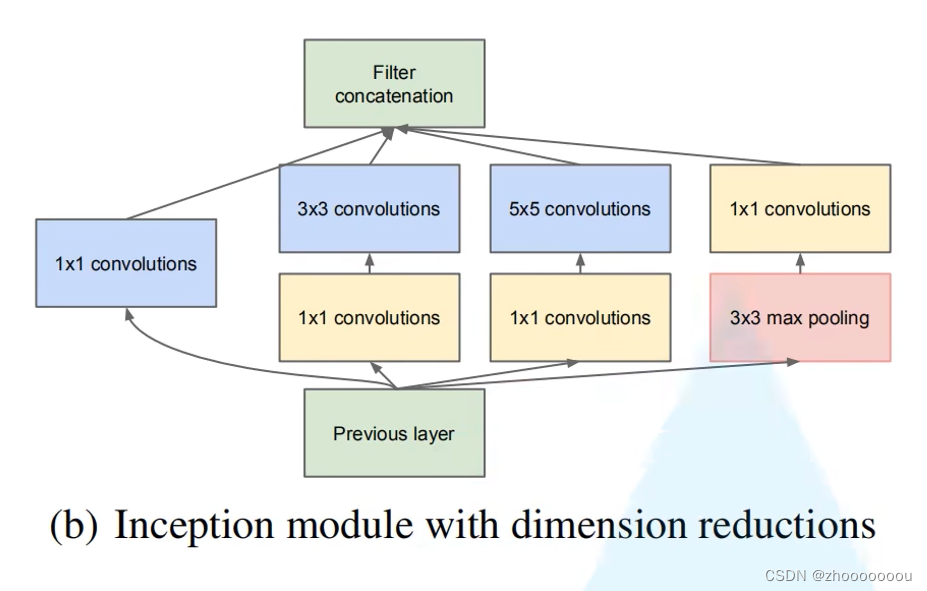
具体的降维原理
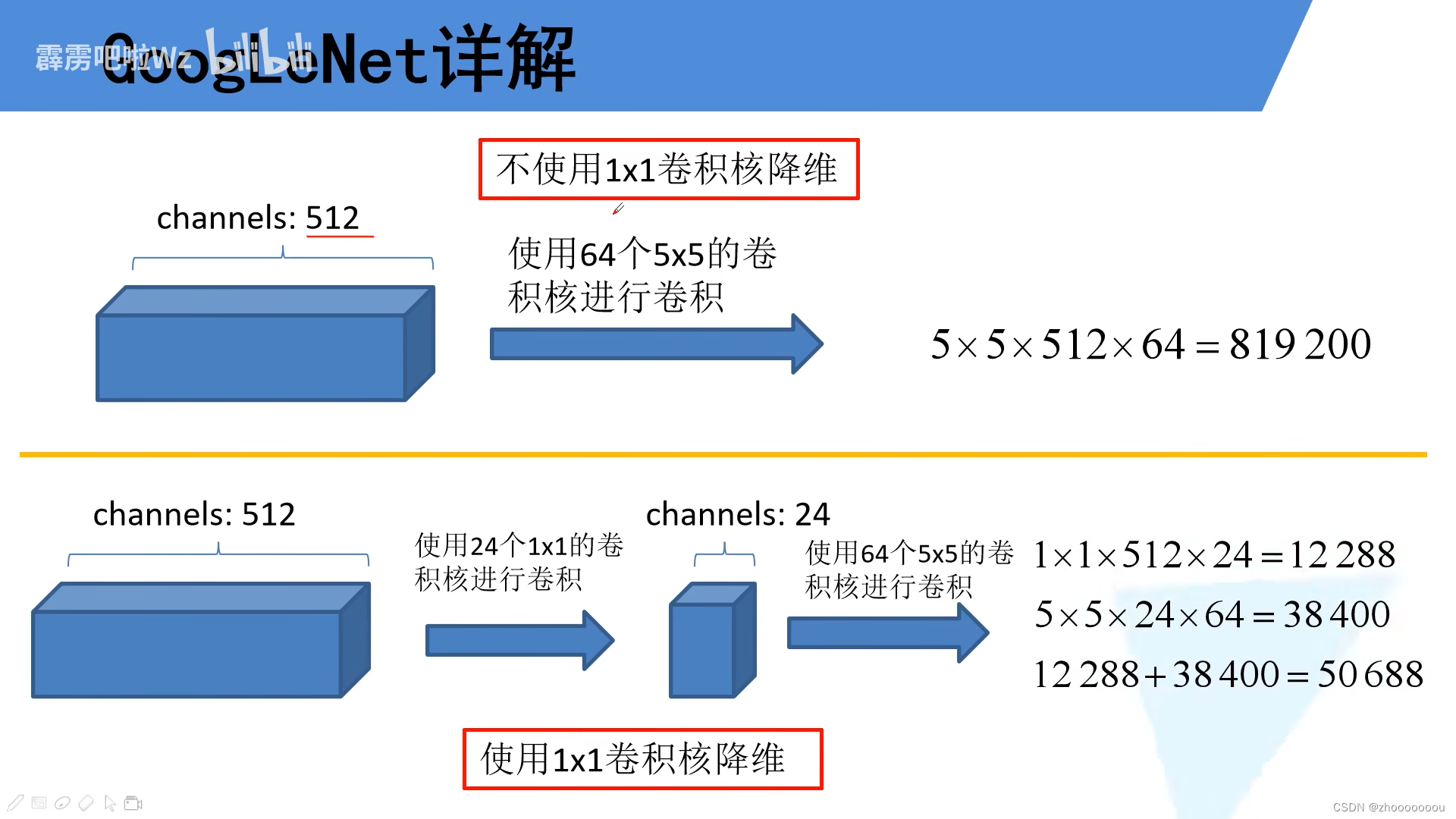
1、初始通道为512,使用64个 5x5 的卷积核进行卷积。
所需要参数计算公式:卷积核尺寸 x 输入特征矩阵的深度 x 卷积核的个数
第一种情况所需要的参数是 819200,非常大的一个数值。
2、初始通道为512,使用24个 1x1 的卷积核进行卷积,再使用64个 5x5 的卷积核进行卷积。
先使用24个 1x1 的卷积核进行卷积对输入特征矩阵进行降维,因为特征矩阵的深度是由卷积核的个数决定的, 所以会将512深度变为24深度,再进行计算所需要的参数个数。
将两部分使用卷积核的需要参数相加,即为全部所需要的参数,一共50688。
很明显,通过使用 1x1 的卷积核进行降维之后,所需要的参数大大减少。
降维的目的就是为了减少输入特征矩阵的深度,从而减少卷积参数,减少计算量。
三、辅助分类器
具体实现
1、池化层
第一层是一个平均池化下采样:池化核 5x5, 步距为3,
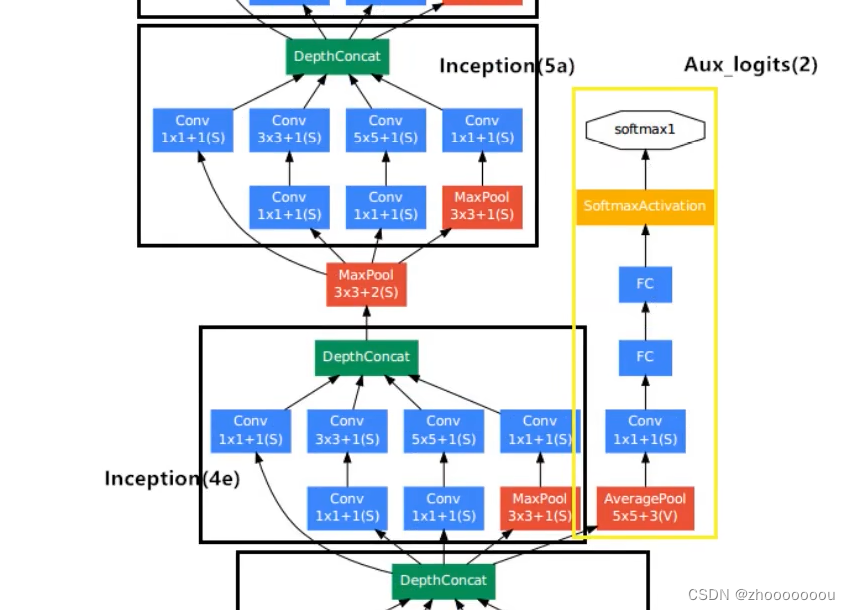
第一个辅助分类器来自于 inception(4a) 的输出 14 x 14 x 512,第二个辅助分类器来自于 inception(4d) 的输出 14 x 14 x 528。
根据矩阵尺寸大小计算公式 out = (14 - 5 + 0) / 3 + 1,
所以第一个辅助分类器的输出为 4 x 4 x 512
第二个辅助分类器的输出为 4 x 4 x 528。(池化不改变特征矩阵的深度)
2、卷积降维
采用128个卷积核大小为 1x1 的卷积层进行卷积处理,目的是为了降低维度,并且使用了relu激活函数。
3、全连接层
采用节点为1024的全连接层,使用relu激活函数。
全连接层与全连接层之间使用dropout函数,以 70% 的比例随机失活神经元。(百分比可根据具体情况更改比例)
4、输出
输出层的节点个数对应数据集的类别个数, 再通过softmax激活函数得到概率分布。
图示说明
第一个辅助分类器来自于 inception(4a)
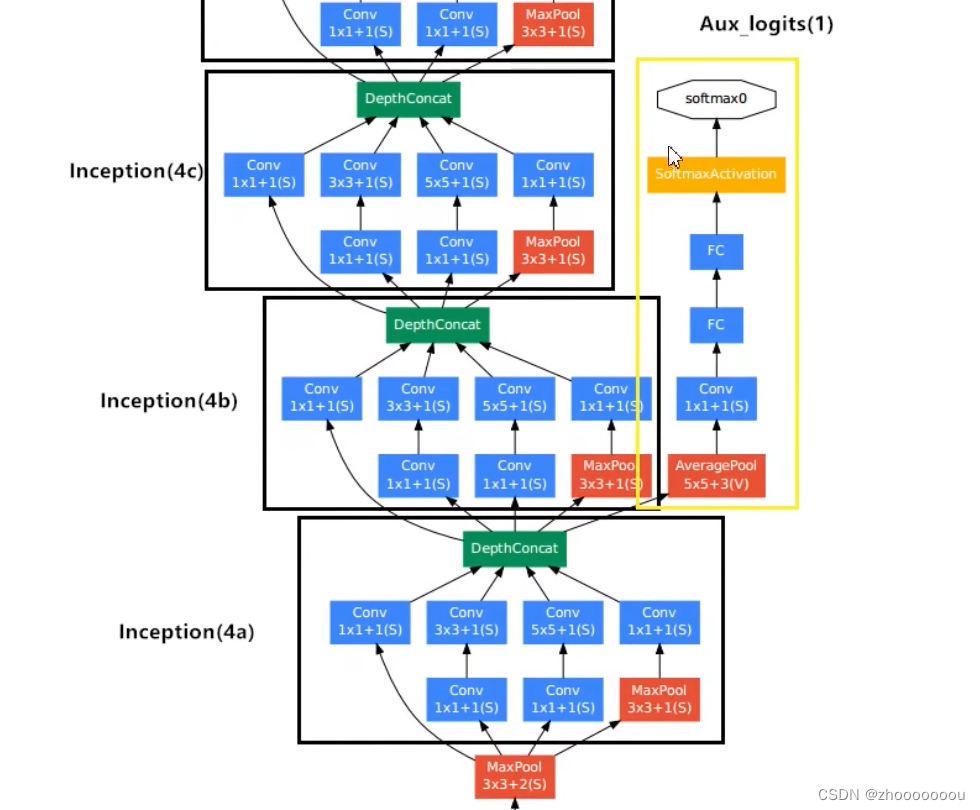
第二个辅助分类器来自于 inception(4d)
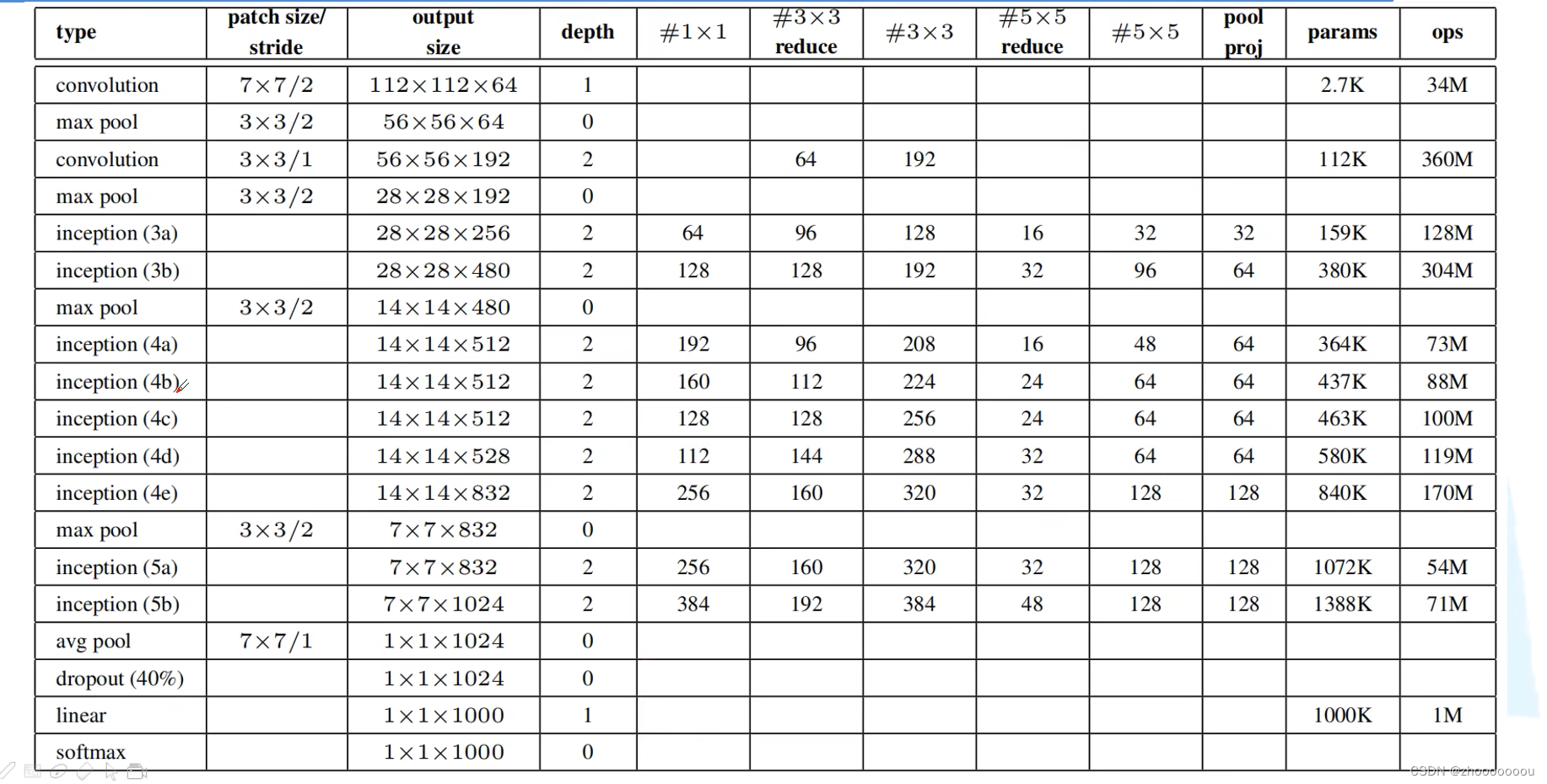
四、参数表格
第一列:一系列层的名称
第二列:卷积核或者是池化核的参数大小
第三列:经过计算后的输出的特征矩阵的大小
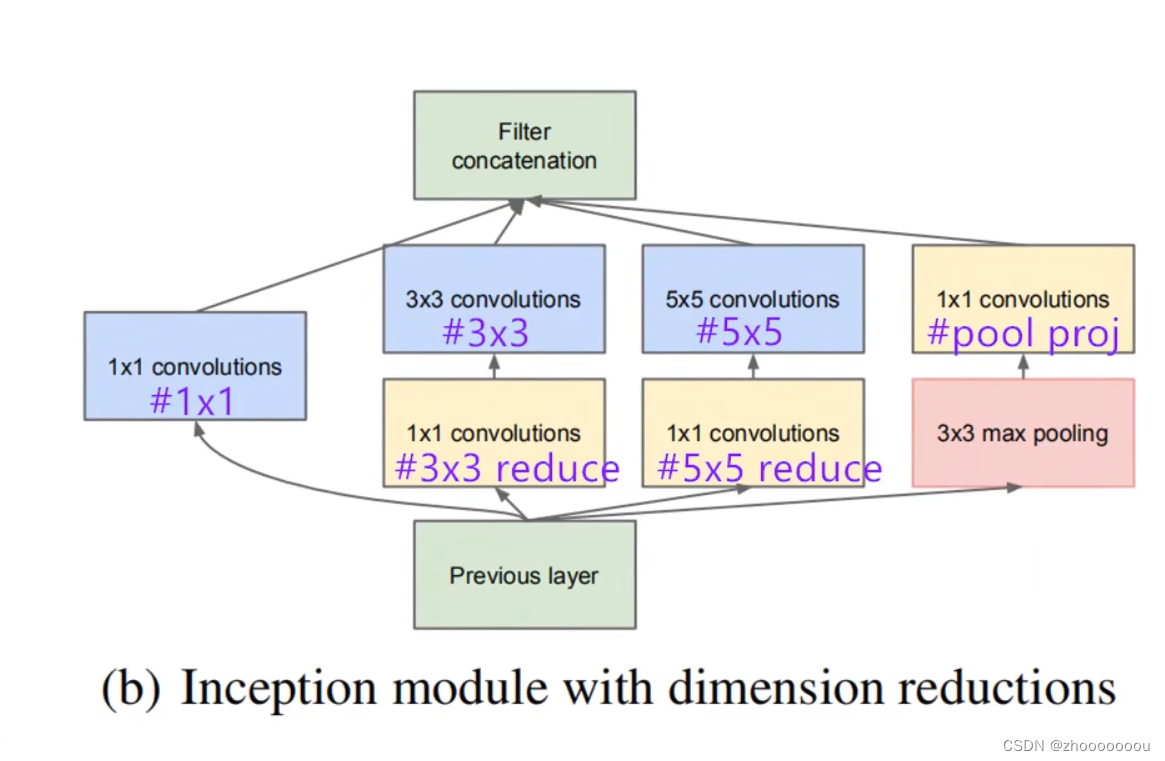
辅助分类器中的参数
# 1 x 1 :辅助分类器中1 x 1 卷积核的个数
# 3 x 3 reduce :在 3 x 3卷积前 1x1 卷积降维处理的个数
# 3 x 3 :辅助分类器中3 x 3 卷积核的个数
# 5 x 5 reduce :在 5 x 5卷积前 1x1 卷积降维处理的个数
# 5 x 5 : 辅助分类器中5 x 5 卷积核的个数
# pool proj :在最大池化后进行的 1x1 卷积降维处理的个数
下图标注可帮助理解。
大家可以在网上找GoogleNet整个神经网络的图片,再结合那一整张参数列表帮助自己更好的理解整个GoogleNet神经网络。
这篇关于GoogleNet神经网络介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





