本文主要是介绍【MySQL】DCL-数据控制语言-【管理用户&权限控制】 (语法语句&案例演示&可cv案例代码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
大家好吖,欢迎来到 YY 滴MySQL系列 ,热烈欢迎! 本章主要内容面向接触过C++ Linux的老铁
主要内容含:

欢迎订阅 YY滴C++专栏!更多干货持续更新!以下是传送门!
- YY的《C++》专栏
- YY的《C++11》专栏
- YY的《Linux》专栏
- YY的《数据结构》专栏
- YY的《C语言基础》专栏
- YY的《初学者易错点》专栏
- YY的《小小知识点》专栏
- YY的《单片机期末速过》专栏
- YY的《C++期末速过》专栏
- YY的《单片机》专栏
- YY的《STM32》专栏
- YY的《数据库》专栏
- YY的《数据库原理》专栏
目录
- 一.DCL-介绍
- 1.DCL-介绍
- 二.管理用户
- 1.管理用户语法&注意事项&可cv代码
- 2.用户名与主机地址概念(案例演示)
- 3.案例演示&案例可cv代码
- 三.权限控制
- 1.权限控制语法&注意事项&种类&可cv代码
- 2.案例演示&可cv代码
一.DCL-介绍
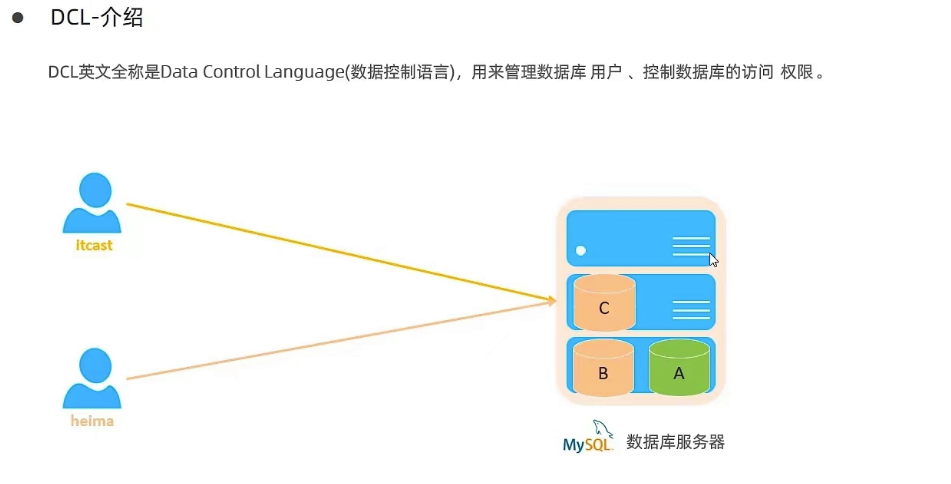
1.DCL-介绍
- 介绍
二.管理用户
1.管理用户语法&注意事项&可cv代码
- 用户管理语法如下所示
用户管理 注意事项:
- 主机名可以使用%通配。
- 这类SQL开发人员操作的比较少,主要是DBA(Database Administrator 数据库管理员)使用。
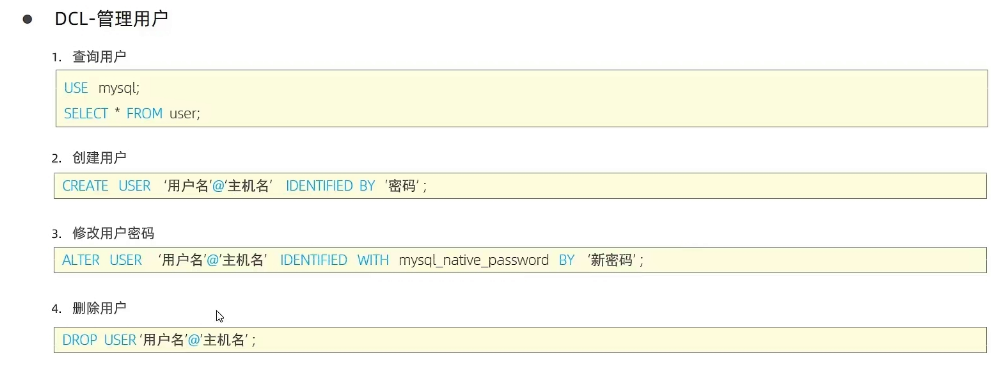
1.查询用户
USE mysql;SELECT *FROM user;
2.创建用户
CREATE USER‘用户名'@'主机名'IDENTIFIED BY‘密码';
3.修改用户密码
ALTER USER ‘用户名‘@'主机名’ IDENTIFIED WITH mysqlLnative_password BY ‘新密码’;
4.删除用户
DROP USER'用户名'@'主机名';
2.用户名与主机地址概念(案例演示)
- 我们点击mysql库,找到user表

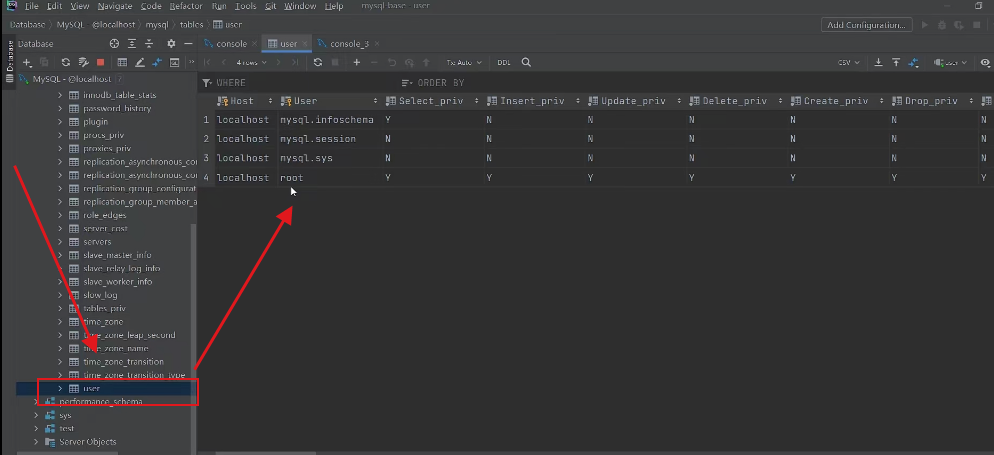
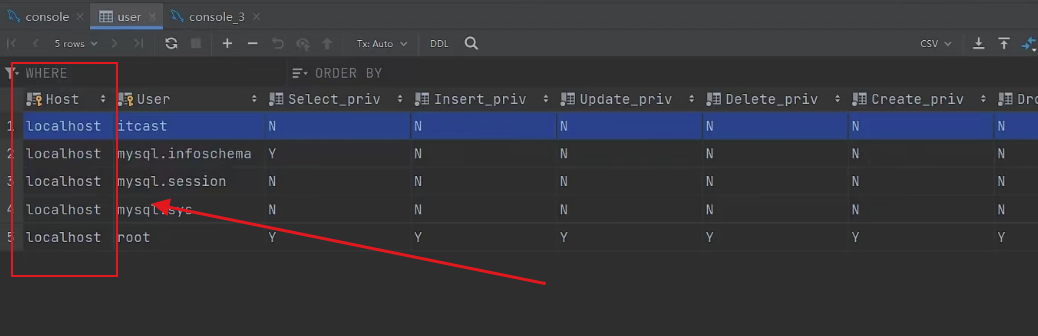
- 要删除用户,要定位 用户名和主机地址
- 主机地址:指的是当前用户 只能在哪个主机上访问当前mysql服务器
- 图中localhost表示只能在主机访问
3.案例演示&案例可cv代码
--创建用户itcast,只能够在当前主机localhost访问,密码123456;
create user 'itcast'@'localhost' identified by '123456';--创建用户yy,可以在任意主机访问该数据库,密码123456;
create user 'heima'@'%' identified by '123456';--修改用户 yy的访间密码为1234;
alter user 'heima'@'%' identified with mysql_native_password by '1234';-- 删除itcast@localhost用户
drop user 'itcast'@'localhost';
三.权限控制
1.权限控制语法&注意事项&种类&可cv代码
- 权限控制语法
- 注意事项
- 多个权限之间,使用逗号分隔
- 授权时,数据库名和表名可以使用 * 进行通配,代表所有

- 权限控制种类
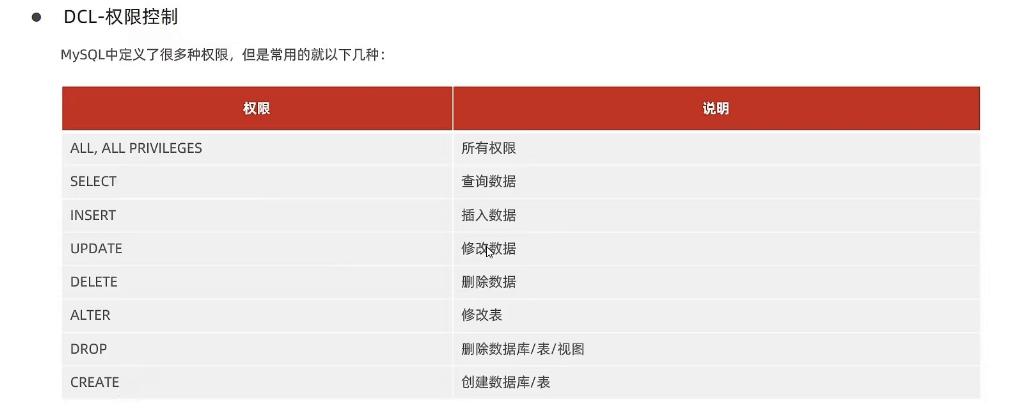
1.查询权限
SHOW GRANTS FOR'用户名'@'主机名’;
2.授予权限
GRANT 权限列表 ON 数据库名.表名 TO'‘用户名‘@’主机名';
3.撤销权限
REVOKE 权限列表 ON 数据库名.表名 FROM‘用户名'@'主机名;
2.案例演示&可cv代码
--查询权眼
show grants for 'yy'@'%'--授予权限
grant all on itcast.* to 'yy'@'%';--撤销权限
revoke all on itcast.* from 'yy'@'%'这篇关于【MySQL】DCL-数据控制语言-【管理用户&权限控制】 (语法语句&案例演示&可cv案例代码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







