本文主要是介绍【Pytorch2.0学习记录】第三章 基于Pytorch的MNIST分类实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3.1.1 数据图像的获取与标签的说明
源码\第三章\one_hot.py
import numpy as np
import torch
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")
print(y_train_label[:5]) #[5 0 4 1 9]
x = torch.tensor(y_train_label[:5],dtype=torch.int64)# 定义一个张量输入tensor([5, 0, 4, 1, 9])
y = torch.nn.functional.one_hot(x, 10) # 一个参数张量x,10为类别数,y shape=(5,10)
print(x)
print(y)
#y: tensor([[0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
# [1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
# [0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]])
3.1.4 基于pytorch的手写体识别的实现
源码\第三章\train.py
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' #指定GPU编号
import torch
import numpy as np
from tqdm import tqdmbatch_size = 320 #设定每次训练的批次数
epochs = 1024 #设定训练次数#device = "cpu" #Pytorch的特性,需要指定计算的硬件,如果没有GPU的存在,就使用CPU进行计算
device = "cuda" #在这里读者默认使用GPU,如果读者出现运行问题可以将其改成cpu模式#设定的多层感知机网络模型
class NeuralNetwork(torch.nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = torch.nn.Flatten() # 展平操作,将图片数据展平为一维 self.linear_relu_stack = torch.nn.Sequential(torch.nn.Linear(28*28,312),torch.nn.ReLU(),torch.nn.Linear(312, 256),torch.nn.ReLU(),torch.nn.Linear(256, 10))def forward(self, input):x = self.flatten(input)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork()
model = model.to(device) #将计算模型传入GPU硬件等待计算
torch.save(model, './model.pth')
#model = torch.compile(model) #Pytorch2.0的特性,加速计算速度
loss_fu = torch.nn.CrossEntropyLoss()# 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=2e-5) #设定Adam优化器,学习率为2e-5#载入数据
x_train = np.load("../dataset/mnist/x_train.npy")
y_train_label = np.load("../dataset/mnist/y_train_label.npy")train_num = len(x_train)//batch_size#开始计算
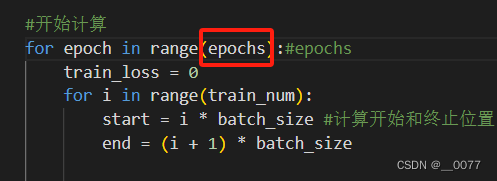
for epoch in range(epochs):#epochstrain_loss = 0for i in range(train_num):start = i * batch_size #计算开始和终止位置,第一次是[0,batch_size-1),第二2次[batch_size,2*batch_size)end = (i + 1) * batch_size#将数据转换为张量并移到指定设备 train_batch = torch.tensor(x_train[start:end]).to(device) label_batch = torch.tensor(y_train_label[start:end]).to(device)pred = model(train_batch)#前向传播,得到预测结果loss = loss_fu(pred,label_batch)#计算损失optimizer.zero_grad()#清零梯度loss.backward()#反向传播,计算梯度 optimizer.step()# 更新模型参数 train_loss += loss.item() # 记录每个批次的损失值# 计算并打印平均损失值train_loss /= train_numaccuracy = (pred.argmax(1) == label_batch).type(torch.float32).sum().item() / batch_sizeprint("epoch:",epoch,"train_loss:", round(train_loss,2),"accuracy:",round(accuracy,2))
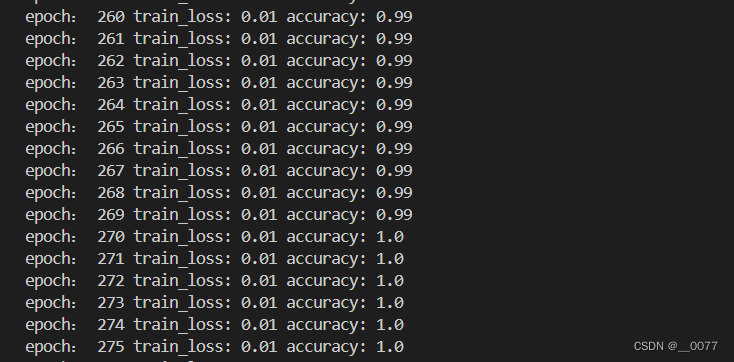
结果:把批次改为epochs后(源码给的是20)就能持续训练了,到270次精确度就=1了。
需要补充的知识点(来自文心老师):
1、PyTorch中常见的操作和概念:
张量(Tensor):PyTorch中的基本数据结构,类似于多维数组,可以存储不同类型的数据(如浮点数、整数等)。
自动微分(Autograd):PyTorch提供了自动微分功能,可以自动计算张量操作的梯度,这对于神经网络的训练非常重要。
神经网络层(Neural Network Layers):PyTorch提供了许多预定义的神经网络层,如卷积层、全连接层、池化层等,用户可以轻松地组合这些层来构建自己的神经网络。
优化器(Optimizers):用于更新神经网络参数的算法,如SGD(随机梯度下降)、Adam等。
数据加载器(Data Loaders):用于从数据集中加载数据,并将其划分为批次(batches)进行训练或测试。
2、self.flatten = torch.nn.Flatten()
torch.nn.Flatten 是 PyTorch 中的一个模块,用于将多维的输入张量展平(flatten)成一维张量,或者展平到指定的维度。这在构建神经网络时特别有用,尤其是当你想要将图像数据(通常是二维或三维的)转换为一维特征向量,以便将其传递给全连接层(linear layers)时。
举例:
import torch
import torch.nn as nn # 假设我们有一个四维张量,代表一批图像数据
batch_size = 4
channels = 3
height = 28
width = 28 # 创建一个随机的四维张量来模拟图像数据
images = torch.randn(batch_size, channels, height, width) # 定义一个包含 Flatten 层的简单模型
class SimpleModel(nn.Module): def __init__(self): super(SimpleModel, self).__init__() #############nn.Flatten()在这里使用###########################self.flatten = nn.Flatten()def forward(self, x): x = self.flatten(x) return x # 初始化模型
model = SimpleModel() # 将图像数据传递给模型
flattened = model(images) # 输出展平后的张量的形状
print(flattened.shape) # 输出应该是 (batch_size, -1),其中 -1 表示自动计算的大小
在这个例子中,nn.Flatten 会将形状为 (batch_size, channels, height, width) 的张量展平成一个形状为 (batch_size, -1) 的张量,其中 -1 是一个占位符,表示该维度的大小是自动计算的。实际上,-1 的大小会是 channels * height * width,即所有非批次维度的乘积。
对于 MNIST 数据集,图像通常是单通道的(灰度图),大小为 28x28 像素。因此,如果你有一个形状为 (batch_size, 1, 28, 28) 的张量,nn.Flatten 会将其展平为形状为 (batch_size, 784) 的张量(因为 1 * 28 * 28 = 784)。这样,你就可以将这个一维张量传递给全连接层进行进一步的处理了。
3、torch.nn.Sequential()
torch.nn.Sequential 是 PyTorch 中的一个容器模块,它按照添加到其中的顺序依次包含多个子模块。当你向 Sequential 中添加模块时,它们将按照添加的顺序被依次执行。这种顺序执行使得 Sequential 非常适合于创建简单的、层叠式的神经网络结构。
使用 Sequential 的好处是它提供了一种简洁的方式来创建模型,而无需定义前向传播方法。你只需要将各个层添加到 Sequential 容器中,PyTorch 就会按照添加的顺序来执行这些层。
尽管 Sequential 对于简单的网络结构非常有用,但当你需要更复杂的控制流(如条件语句或循环)或需要定义自己的前向传播逻辑时,你可能需要定义自己的 nn.Module 子类,并在其中实现 forward 方法。
3.2.1 查看模型结构和参数信息
源码\第三章\netron.py
对于自定义网络,直接使用如下函数完成模型的打印:
model = NeuralNetwork()
print(model)
输出:
NeuralNetwork((flatten): Flatten(start_dim=1, end_dim=-1)#平滑成【1,X】大小(linear_relu_stack): Sequential((0): Linear(in_features=784, out_features=312, bias=True)#全连接层,接受784个输入特征,输出312个特征。bias=True表示这一层有偏置项。(1): ReLU()#这是ReLU激活函数,它应用于前一个线性层的输出。ReLU函数会将所有负值变为0,而正值保持不变。(2): Linear(in_features=312, out_features=256, bias=True)(3): ReLU()(4): Linear(in_features=256, out_features=10, bias=True))
)
具体参数和层数的输出,有关net.parameters,参考此链接:
import torch
device = "cuda" #在这里读者默认使用GPU,如果读者出现运行问题可以将其改成cpu模式
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")#设定的多层感知机网络模型
class NeuralNetwork(torch.nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = torch.nn.Flatten()self.linear_relu_stack = torch.nn.Sequential(torch.nn.Linear(2,3),torch.nn.ReLU(),torch.nn.Linear(3, 5),torch.nn.ReLU(),torch.nn.Linear(5, 2))def forward(self, input):x = self.flatten(input)logits = self.linear_relu_stack(x)return logitsmodel = NeuralNetwork()
#print(model)
model = model.to(device) #将计算模型传入GPU硬件等待计算
# #torch.save(model, './model.pth')params=list(model.parameters())
k=0
for num,para in enumerate(params):l=1print("第",num,"层的结构:"+str(list(para.size())))for j in para.size():l*=jprint("该层参数和:"+str(l))print(para)print('______________________________')k=k+l
print("总参数数量和:"+str(k)) 输出:
其中,我们加上输出层一共设置了3层全连接层,对应以下第0、2、4层;第1、3层是偏置层。

还有一点,层的结构是[out,in],比如第一个 torch.nn.Linear(2,3)对应的层结构为[3, 2]。
第 0 层的结构:[3, 2]
该层参数和:6
Parameter containing:
tensor([[ 0.5712, 0.2243],[ 0.6914, -0.6446],[ 0.0275, 0.4616]], device='cuda:0', requires_grad=True)
______________________________
第 1 层的结构:[3]
该层参数和:3
Parameter containing:
tensor([0.1890, 0.0555, 0.6089], device='cuda:0', requires_grad=True)
______________________________
第 2 层的结构:[5, 3]
该层参数和:15
Parameter containing:
tensor([[ 0.4450, 0.3689, 0.5252],[ 0.4570, 0.1599, -0.4878],[ 0.2633, 0.4276, -0.5587],[-0.1436, 0.0929, 0.3933],[ 0.5510, 0.0286, -0.5658]], device='cuda:0', requires_grad=True)
______________________________
第 3 层的结构:[5]
该层参数和:5
Parameter containing:
tensor([ 0.2082, -0.0087, 0.3519, -0.3106, 0.0778], device='cuda:0',requires_grad=True)
______________________________
第 4 层的结构:[2, 5]
该层参数和:10
Parameter containing:
tensor([[ 0.0707, -0.0262, -0.2613, 0.1295, -0.1679],[-0.3952, -0.3387, -0.0963, -0.1872, 0.0991]], device='cuda:0',requires_grad=True)
______________________________
第 5 层的结构:[2]
该层参数和:2
Parameter containing:
tensor([-0.3942, -0.3752], device='cuda:0', requires_grad=True)
______________________________
总参数数量和:41
3.2.2 基于netron库的PyTorch2.0模型可视化
这篇关于【Pytorch2.0学习记录】第三章 基于Pytorch的MNIST分类实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



