本文主要是介绍八、大模型之Fine-Tuning(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 什么时候需要Fine-Tuning
- 有私有部署的需求
- 开源模型原生的能力不满足业务需求
2 训练模型利器Hugging Face
- 官网(https://huggingface.co/)
- 相当于面向NLP模型的Github
- 基于transformer的开源模型非常全
- 封装了模型、数据集、训练器等,资源下载方面
- 安装依赖
# pip 安装
pip install transformers # 安装最新版本
pip install transformers == 4.30 # 安装指定版本
# conda安装
conda install -c huggingface transformers # 只4.0以后的版本
3 案例
3.1 操作流程
加载数据集—>数据预处理—>数据规整器—>训练器
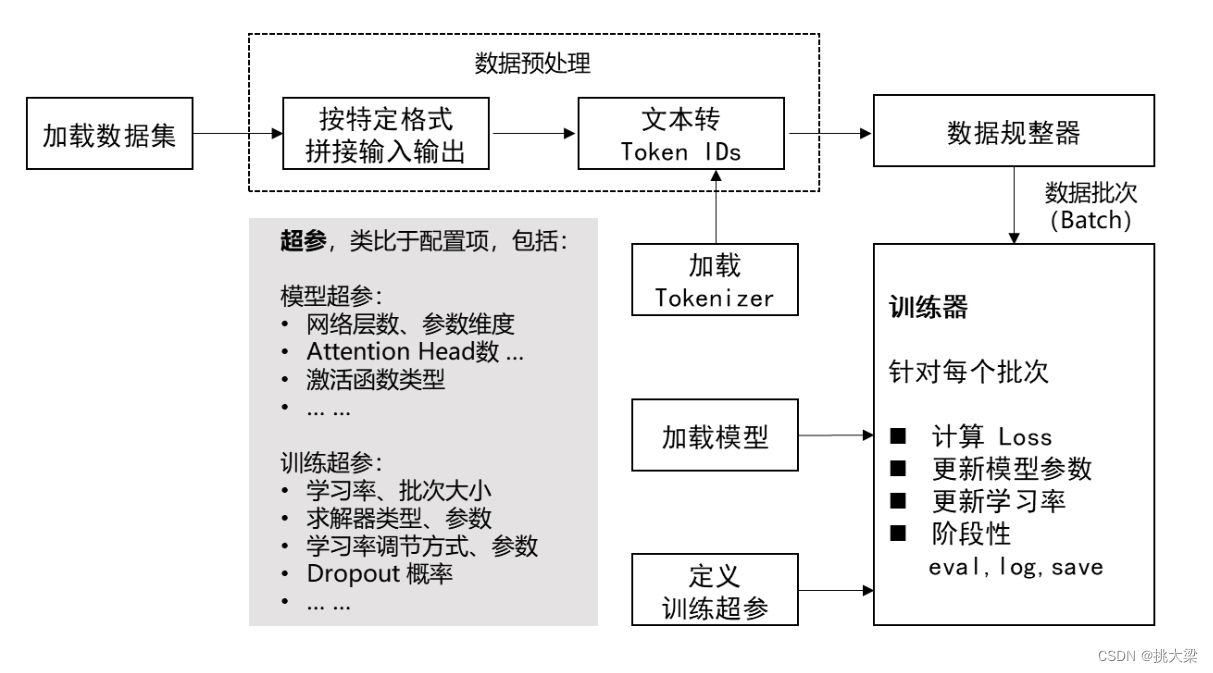
3.2 实现
- 导包
import datasets
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from transformers import AutoModelForCausalLM
from transformers import TrainingArguments, Seq2SeqTrainingArguments
from transformers import Trainer, Seq2SeqTrainer
import transformers
from transformers import DataCollatorWithPadding
from transformers import TextGenerationPipeline
import torch
import numpy as np
import os, re
from tqdm import tqdm
import torch.nn as nn
- 加载数据集
通过HuggingFace,可以指定数据集名称,运行时自动下载
# 数据集名称
DATASET_NAME = "rotten_tomatoes" # 加载数据集
raw_datasets = load_dataset(DATASET_NAME)# 训练集
raw_train_dataset = raw_datasets["train"]# 验证集
raw_valid_dataset = raw_datasets["validation"]
3. 加载模型
# 模型名称
MODEL_NAME = "gpt2" # 加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME,trust_remote_code=True)

4. 加载Tokenizer
通过HuggingFace,可以指定模型名称,运行自动下载对应Tokenizer
# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME,trust_remote_code=True)
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
tokenizer.pad_token_id = 0# 设置随机种子:同个种子的随机序列可复现
transformers.set_seed(42)# 标签集
named_labels = ['neg','pos']# 标签转 token_id
label_ids = [tokenizer(named_labels[i],add_special_tokens=False)["input_ids"][0] for i in range(len(named_labels))
]

5. 处理数据集:转成模型接受的输入格式
- 拼接输入输出:<INPUT TOKEN IDS><EOS_TOKEN_ID><OUTPUT TOKEN IDS>
- PAD成相等长度:
- <INPUT 1.1><INPUT 1.2>…<EOS_TOKEN_ID><OUTPUT TOKEN IDS><PAD>…<PAD>
- <INPUT 2.1><INPUT 2.2>…<EOS_TOKEN_ID><OUTPUT TOKEN IDS><PAD>…<PAD>
- 标识出参与 Loss 计算的 Tokens (只有输出 Token 参与 Loss 计算)
- <-100><-100>…<OUTPUT TOKEN IDS><-100>…<-100>
MAX_LEN=32 #最大序列长度(输入+输出)
DATA_BODY_KEY = "text" # 数据集中的输入字段名
DATA_LABEL_KEY = "label" #数据集中输出字段名# 定义数据处理函数,把原始数据转成input_ids, attention_mask, labels
def process_fn(examples):model_inputs = {"input_ids": [],"attention_mask": [],"labels": [],}for i in range(len(examples[DATA_BODY_KEY])):inputs = tokenizer(examples[DATA_BODY_KEY][i],add_special_tokens=False)label = label_ids[examples[DATA_LABEL_KEY][i]]input_ids = inputs["input_ids"] + [tokenizer.eos_token_id, label]raw_len = len(input_ids)input_len = len(inputs["input_ids"]) + 1if raw_len >= MAX_LEN:input_ids = input_ids[-MAX_LEN:]attention_mask = [1] * MAX_LENlabels = [-100]*(MAX_LEN - 1) + [label]else:input_ids = input_ids + [tokenizer.pad_token_id] * (MAX_LEN - raw_len)attention_mask = [1] * raw_len + [0] * (MAX_LEN - raw_len)labels = [-100]*input_len + [label] + [-100] * (MAX_LEN - raw_len)model_inputs["input_ids"].append(input_ids)model_inputs["attention_mask"].append(attention_mask)model_inputs["labels"].append(labels)return model_inputs
6.定义数据规整器:训练时自动将数据拆分成Batch
# 定义数据校准器(自动生成batch)
collater = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt",
)
7.定义训练超参
LR=2e-5 # 学习率
BATCH_SIZE=8 # Batch大小
INTERVAL=100 # 每多少步打一次 log / 做一次 eval# 定义训练参数
training_args = TrainingArguments(output_dir="./output", # checkpoint保存路径evaluation_strategy="steps", # 按步数计算eval频率overwrite_output_dir=True,num_train_epochs=1, # 训练epoch数per_device_train_batch_size=BATCH_SIZE, # 每张卡的batch大小gradient_accumulation_steps=1, # 累加几个step做一次参数更新per_device_eval_batch_size=BATCH_SIZE, # evaluation batch sizeeval_steps=INTERVAL, # 每N步eval一次logging_steps=INTERVAL, # 每N步log一次save_steps=INTERVAL, # 每N步保存一个checkpointlearning_rate=LR, # 学习率
)
8.定义训练器
# 节省显存
model.gradient_checkpointing_enable()# 定义训练器
trainer = Trainer(model=model, # 待训练模型args=training_args, # 训练参数data_collator=collater, # 数据校准器train_dataset=tokenized_train_dataset, # 训练集eval_dataset=tokenized_valid_dataset, # 验证集# compute_metrics=compute_metric, # 计算自定义评估指标
)
8.训练
trainer.train()
总结
- 加载数据集
- 数据预处理
- 将输入输出按特定格式拼接
- 文本转Token IDs
- 通过labels标识出哪部分是输出(只有输出的token参与loss计算)
- 加载模型、Tokenizer
- 定义数据规则整器
- 定义训练超参:学习率、批次大小
- 定义训练器
- 开始训练
4 大模型训练相关技术
-
神经网络

-
常用的激活函数

-
梯度下降

-
学习率
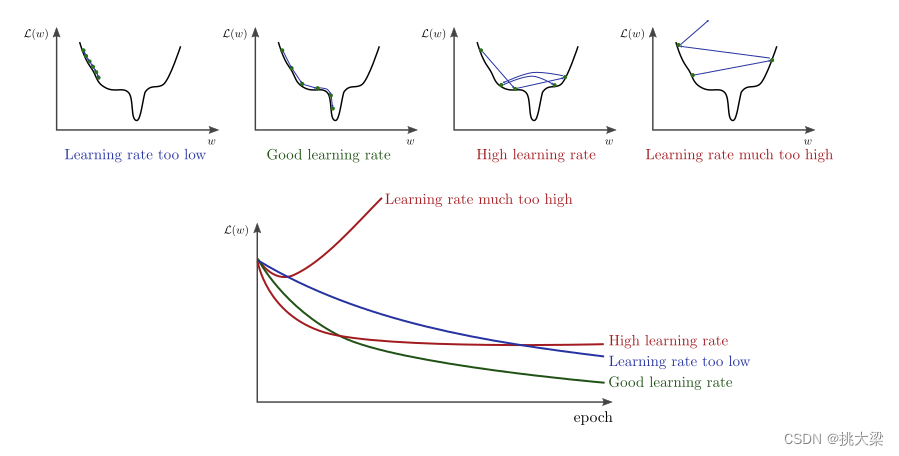
-
求解器
为了让训练过程更好的收敛,人们设计了很多更复杂的求解器
- 比如:SGD、L-BFGS、Rprop、RMSprop、Adam、AdamW、AdaGrad、AdaDelta 等等
- 但是,好在对于Transformer最常用的就是 Adam 或者 AdamW
- 一些常用的损失函数
-
两个数值的差距,Mean Squared Error: ℓ M S E = 1 N ∑ i = 1 N ( y i − y ^ i ) 2 \ell_{\mathrm{MSE}}=\frac{1}{N}\sum_{i=1}^N(y_i-\hat{y}_i)^2 ℓMSE=N1∑i=1N(yi−y^i)2 (等价于欧式距离,见下文)
-
两个向量之间的(欧式)距离: ℓ ( y , y ^ ) = ∥ y − y ^ ∥ \ell(\mathbf{y},\mathbf{\hat{y}})=\|\mathbf{y}-\mathbf{\hat{y}}\| ℓ(y,y^)=∥y−y^∥
-
两个向量之间的夹角(余弦距离):

-
两个概率分布之间的差异,交叉熵: ℓ C E ( p , q ) = − ∑ i p i log q i \ell_{\mathrm{CE}}(p,q)=-\sum_i p_i\log q_i ℓCE(p,q)=−∑ipilogqi ——假设是概率分布 p,q 是离散的
-
这些损失函数也可以组合使用(在模型蒸馏的场景常见这种情况),例如 L = L 1 + λ L 2 L=L_1+\lambda L_2 L=L1+λL2,其中 λ \lambda λ是一个预先定义的权重,也叫一个「超参」
这篇关于八、大模型之Fine-Tuning(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








