本文主要是介绍MIT最新研究成果 机器人能够从错误中纠偏 无需编程介入和重复演示,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目前科学家们正在努力让机器人变得更加智能,教会他们完成诸如擦拭桌面,端盘子等复杂技能。以往机器人要在非结构化环境执行这样的任务,需要依靠固定编程进行,缺乏场景通用性,而现在机器人的学习过程主要在于模仿,即通过观看人类的演示,录入到程序当中进行训练,进而掌握和人类相同的运动技能。
事实上,机器人应该是一个出色的模仿者。但如果工程师未对机器人进行编程,使其适应各种可能的碰撞与轻微推动,则机器人在处理这些情况时可能表现不足,机器人无法处理这些行为时会回到原点重新进行任务。
针对这一问题,麻省理工学院的工程师尝试教会机器人一定的常识认知能力,以此来应对在遭到碰撞或推动时能够偏离预设路径。他们研发了一种创新方法,将机器人的运动数据与大型语言模型(LLM)的“常识性知识”相结合,来增强机器人的应变能力。
融合LLM功能之后机器人如何拾取和放置红色罐子
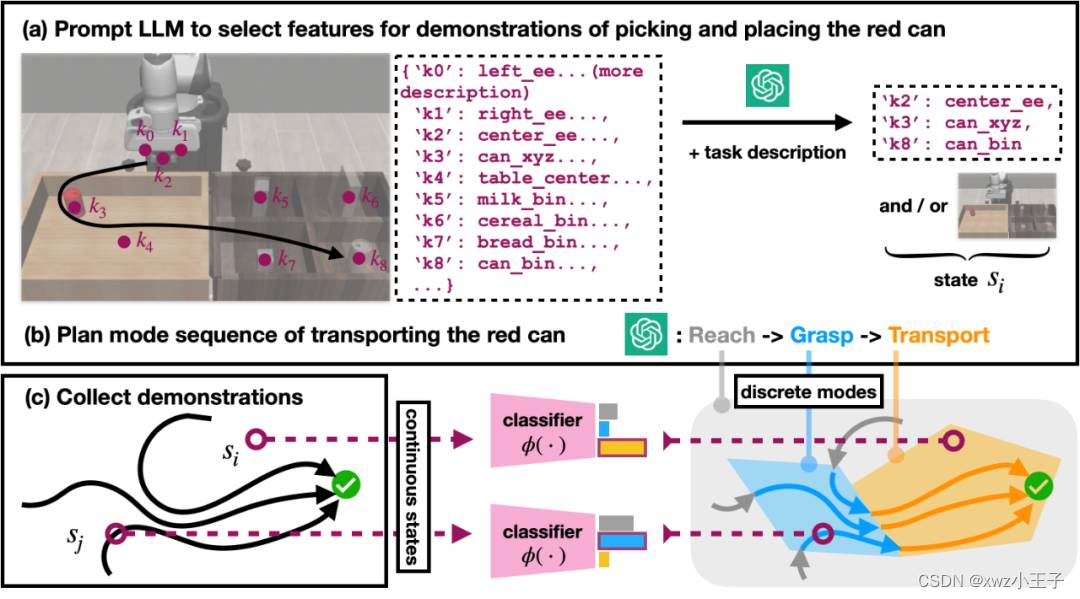
采用该研究方法,机器人能够从逻辑上将许多给定的家庭任务解析为子任务,并对子任务中突然的干扰行为进行物理调整,这样机器人就能继续执行指令,而无需回归初始状态重新执行整个操作,此外工程师也不需要为中途出现的每一个突发情况来编写修复程序。
机器人遇到人为干扰可自动纠正错误

模仿学习是目前家用机器人的主要学习方法,但这种学习方法也有一定的风险,如果盲目模仿人类运动轨迹,一旦产生微小的错误,那么深度学习会将错误进行放大,最终导致执行过程当中产生其他的错误行为。研究人员通过全新的模型算法,使得机器人具备自我纠正执行错误,提升整体任务完成率。
▍LLM可通过自然语言告知机器人完成任务的每个步骤
在具体的实验中,研究人员将勺子固定在机械臂上,左右两侧各有一个碗,机器人的任务是将左侧碗中的玻璃球,通过操作勺子,顺利将玻璃球挪到右侧空碗当中。但为了完成这样的任务,研究人员通常需要机器人在一个流体轨迹上完成舀和倒的动作,为此演示人员通常需要做多次这种动作以此来让机器人进行学习。
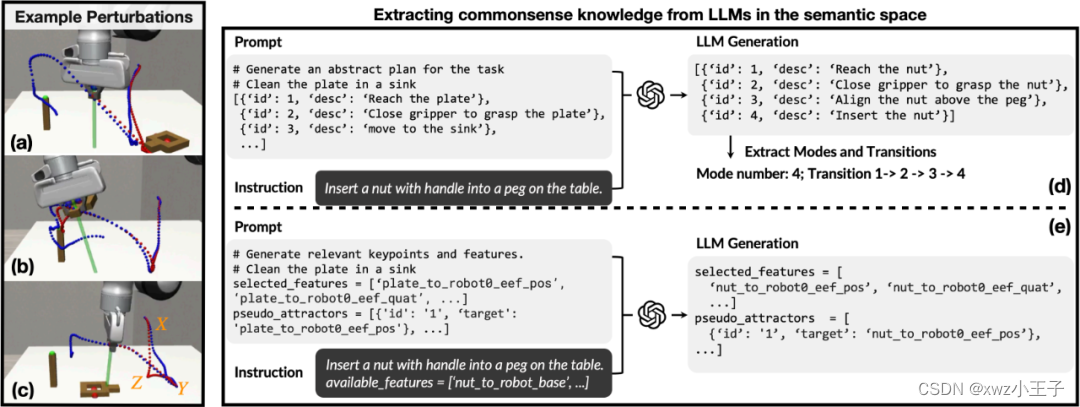
机器人从语义空间中的LLM中提取常识知识
机器人在执行这个指令时,所需要的规划是线性的,必须先将勺子伸进装有玻璃球的碗中,才能舀起玻璃球,在运送玻璃球的过程当中遭遇碰撞和拖动则会停下来,回到起点重新进行任务。

机器人2D导航任务的图示
研究人员发现,机器人运行的一些动作可以由LLM自动完成。利用深度学习模型可以管理大量的文本库,并利用这些文本库建立单词、句子和段落之间的联系,并根据这些联系生成全新的句子。此外,LLM还能在提示下列出特定任务所涉及的子任务的逻辑列表。
研究人员表示,LLM可以用自然语言告诉你如何完成任务的每个步骤。人类的连续演示就是这些步骤在物理空间中的体现。将两者进行有效地结合,机器人就能自动知道自己处于任务的哪个阶段,并能够在动作受到干扰时,自动重新规划和恢复任务。
▍融合算法之后 机器人执行指令变得更加聪明
研究团队的新算法将LLM针对特定子任务的自然语言标签与机器人在物理空间中的位置,以及编码机器人状态的图像连接起来,将机器人的物理坐标或机器人状态图像映射到自然语言标签,随后根据机器人的物理坐标或图像视图,自动识别机器人所处的语义子任务。
机器人舀玻璃球任务示意图
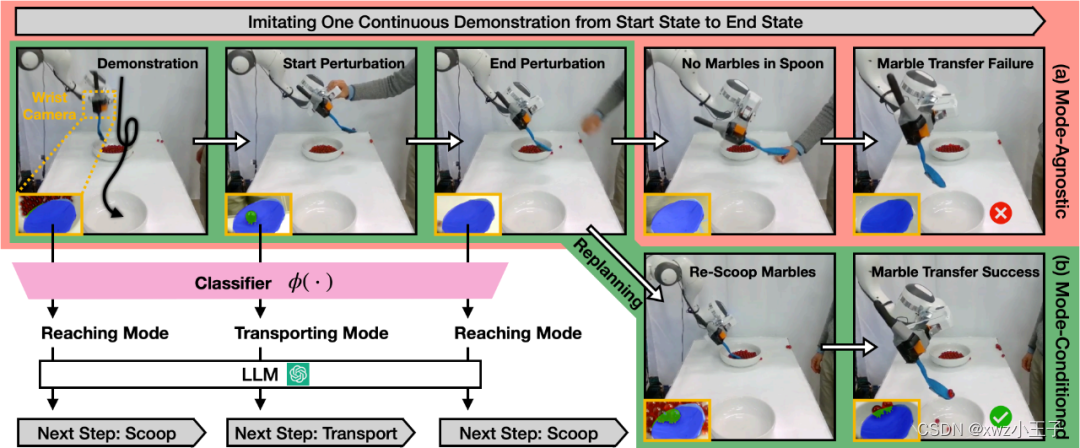
在实验中尽管工作人员在机器人执行任务的时候,手动拖拽并且打散勺子中的玻璃球,使其偏离轨道,但机器人依然不会停下来,回到原点重新执行任务,同时也不会在勺子上没有玻璃球之后,继续执行任务,而是能够自我纠正,在完成每个子任务后再继续下一个任务。
从这方面来看,机器人拥有了一定的智能性,而不是盲目在存在错误时,继续执行未完成的指令,而是通过识别子任务的方式,及时进行修正,进而完成整体任务。采用该算法,有效减少了人工调试成本。
这篇关于MIT最新研究成果 机器人能够从错误中纠偏 无需编程介入和重复演示的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






