本文主要是介绍隐私计算实训营学习六:隐语PIR介绍及开发指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、隐语实现的PIR总体介绍
- 1.1 PIR的定义和种类
- 1.2 隐语PIR功能分层
- 二、Index PIR-SealPIR介绍
- 三、Keyword PIR- Labeled PSI介绍
- 四、隐语PIR后续计划
一、隐语实现的PIR总体介绍
1.1 PIR的定义和种类
PIR(Private Information Retrieval PIR)隐匿查询:用户查询服务端数据库中的数据,但服务端不知道用户查询的是哪些数据。
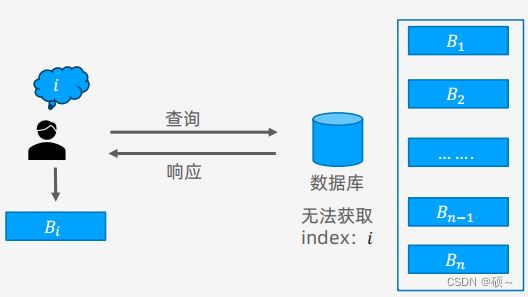
分类:
- 按服务器数量分类:单服务器方案(Single Server)、多服务器方案(Multi-Server)。
- 按查询类型分类:Index PIR、Keyword PIR。
隐语目前支持的PIR方式:
-
Single Server Index PIR : SealPIR。
-
Single Server Keyword PIR:Labeled PSI。
1.2 隐语PIR功能分层
隐语PIR实现位置: 实现位置主要在SPU的代码库。 下层依赖YACL的密码库,上层secretflow层有相应的调用接口(pir_setup、pirquery及基于内存的pir_mem_query)。
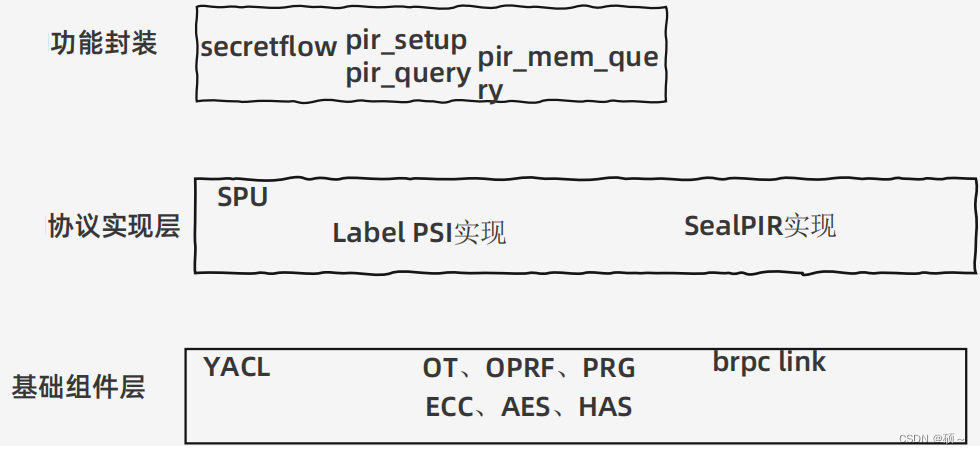
隐语PIR预处理调用接口pir_setup: 提示pir_setup 单方任务,可以使用的secretflow单机模拟配置,或者直接调用spu的python接口。
'''
pir_setup 数据预处理,参数说明:
input_path:服务端数据文件路径,建议绝对路径
key_columns:Key对应的列名
label_columns:Label对应的列名,多列,用逗号分隔
oprf_key_path:服务端ecc密钥文件,32B,二进制文件
mum_per_query:每次查询的id数量
label_max_len:Label数据拼接后填充到固定的长度大小
'''
reports = spu.pir_setup(server='bob',input_path='/path/B_PIR_DATA.csv',key_columns='id',label_columns=['register_date','age'],oprf_key_path='/path/oprf_key.bin',setup_path='/path/setup_path',num_per_query=1,label_max_len=18,
)
隐语PIR调用接口pir_query:
#pir_query双方执行查询任务, 参数说明:
'''
客户端配置input_path:查询id对应的csv文件路径Key_columns:Key对应的列名output_path:PIR查询结果输出的文件路径
#服务端配置oprf_key_path:服务端ecc密钥文件,32B,二进制文件setup_path:预处理阶段结果输出路径
'''
# client
alice_config = {'input_path': ‘/path/A_PIR_ID.csv’,'key_columns’: id','output_path': ‘/path/sf_pir_out.csv’,
}
# server
bob_config = {'oprf_key_path': ‘/path/oprf_key.bin’,'setup_path': ‘/path/setup_path’,
}
query_config = {alice: alice_config,bob: bob_config,
}
reports = spu.pir_query(server='bob’,config=query_config,
)
二、Index PIR-SealPIR介绍
Index PIR-SealPIR: 隐语实现的Index PIR基于SealPIR,SealPIR基于BFV的同态方案,SealPIR主要用到的多项式为密文加法、明文乘密文、密文替换。

SealPIR基于同态密码实现Index PIR的基本原理: 客户端将查询向量(0,1向量)使用同态算法进行加密,加密后发送给服务端,服务端使用该数据进行累积得待查询数据加密结果,返回給客户端;客户端解密得到带查询数据。
存在问题:请求的消息报文太大,包含了n个密文向量。

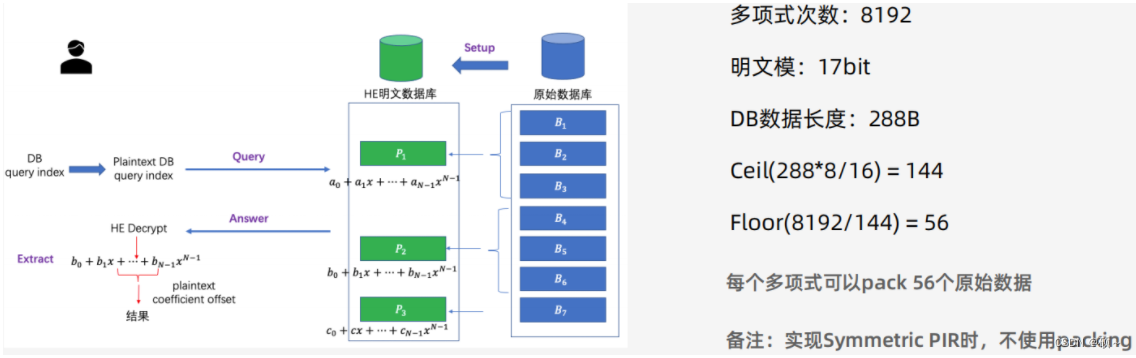
SealPIR主要贡献:
1、多个数据pack到一个HE Plaintext同态明文多项式:查询的db_index转换为plaintext_index。 原始数据B1、B2、B3pack到明文多项式P1,B4、B5、B6pack到P2,用户查询B4情况下,需要将数据库的查询index转换为多项式的查询index P2,服务端返回P2的加密值,客户端同态解密得到明文多项式,再依据pack的偏移找到B4的偏移系数拼接为明文数据。
2、查询向量压缩到一个密文:显著减少通信量,server端可通过计算expand得到查询密文向量。 客户端查询向量压缩将原始n个密文压缩到同态明文多项式,对该明文多项式加密得到查询密文,服务端得到查询密文使用expand扩展算法得到具体n个密文向量,再使用n个向量进行同态乘得到结果。

3、支持多维查询:多维查询将数据转换为 n ∗ n的矩阵,减少expand计算量。

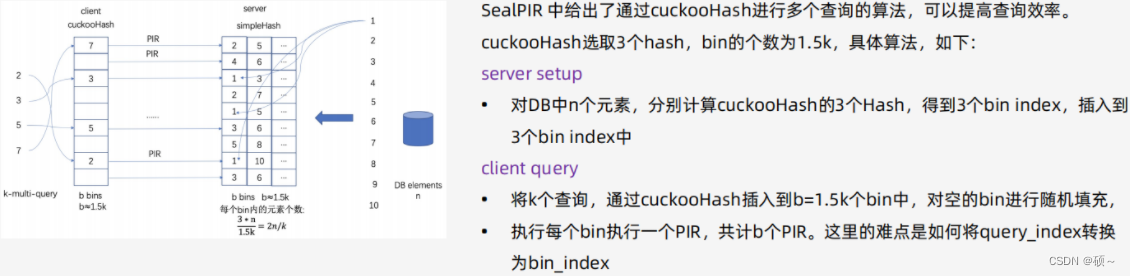
4、支持多个查询:使用cuckoo hash支持同时进行多个查询。
PIR实现位置:

三、Keyword PIR- Labeled PSI介绍
Keyword PIR:隐语实现的基于Labeled PIR方案。 基本原理使用两个差值多项式,包括一个匹配多项式和一个Lable差值多项式,在匹配多项式P(key)为0情况下对应的差值多项式Q(key)的值对应三个带查询值。
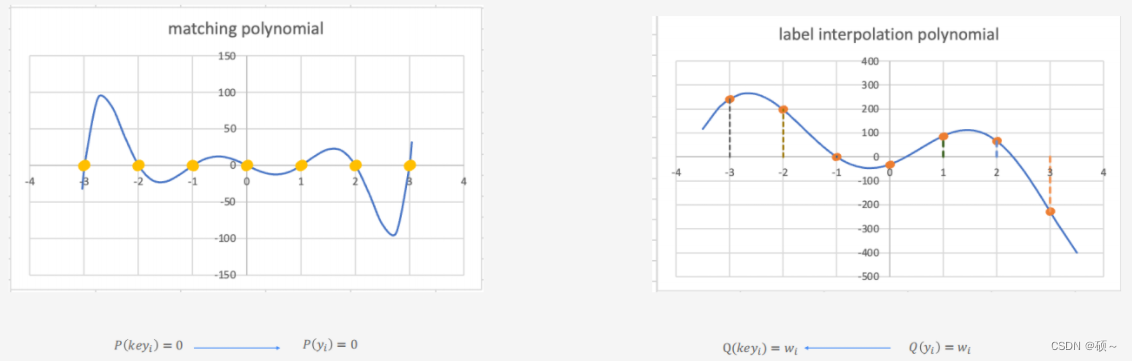
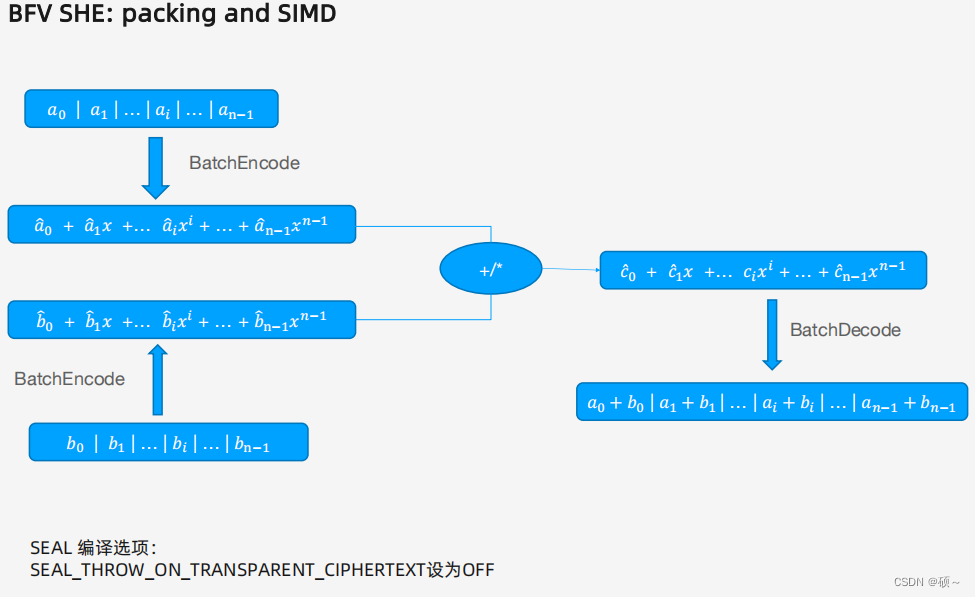
Keyword PIR也使用了BFV的方案: 明文编码方式使用BatchEncode,每个位置上的数据支持基于位置的加法和乘法。
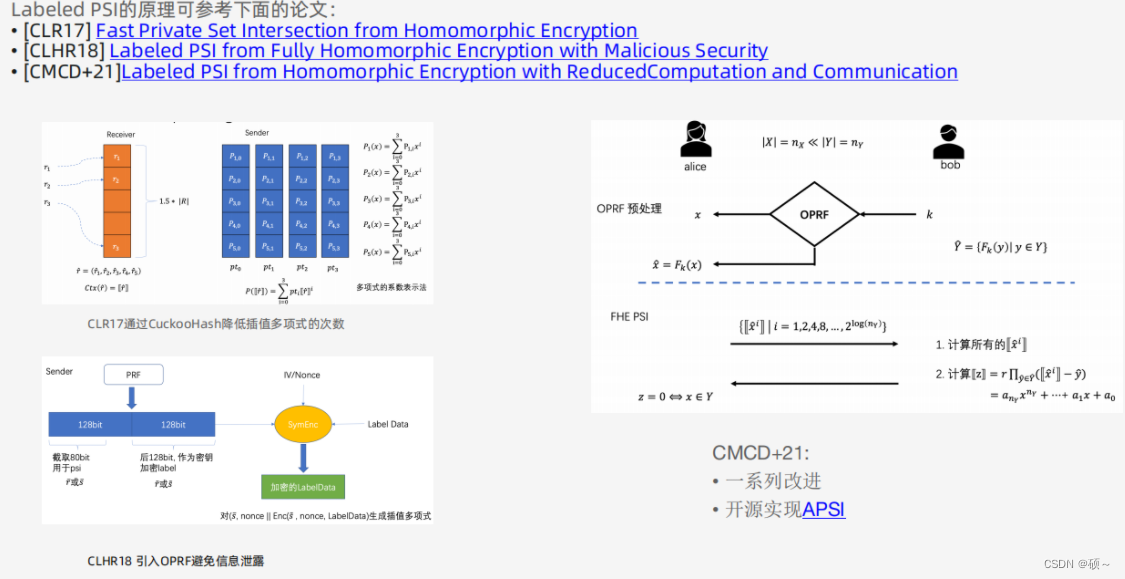
1、减少乘法次数和计算量: 客户端通过窗口机制减少发送密文个数,发送2的次方倍数。服务端可以通过分区将每个bin划分为若干个子集,每个子集对应一个差值多项式,降低相应的多项式次数。

2、使用extremal postage stamp bases减少通信量。
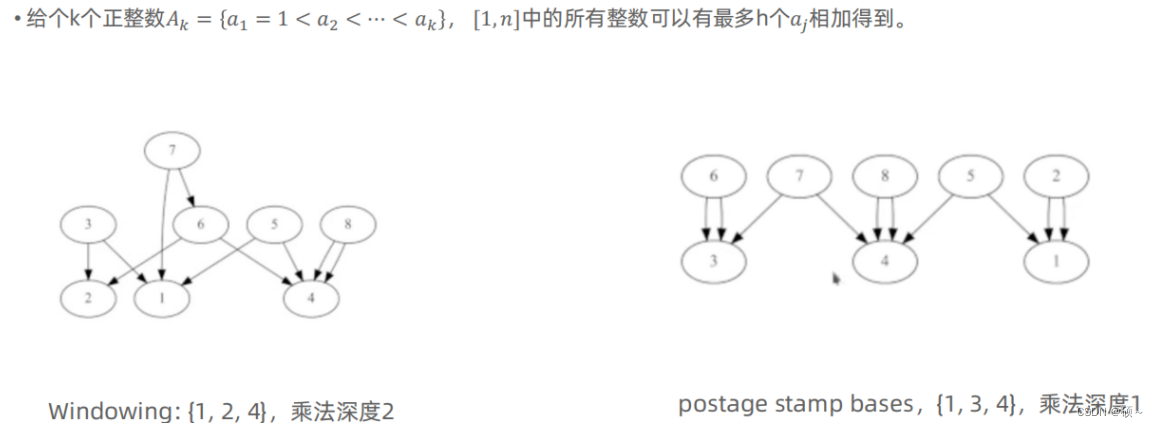
3、Paterson-Stockmeyer算法,减少密文乘法。
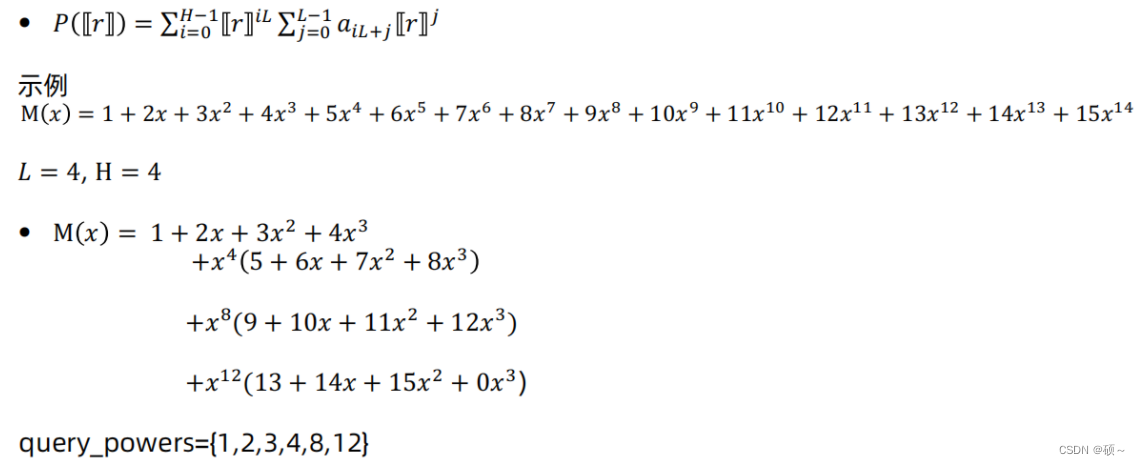
隐语label PIR的主要工作:
- 以微软的开源代码功能为核心;
- OPRF采用隐语的实现:支持的ecc曲线包括:FourQ, Secp256k1, SM2;
- Label的自动填充;
- 增加了服务的预处理结果保存功能:可以支持离线和查询(多次)两个阶段。
服务端预处理setuo阶段流程:
- 参数选择:对cuckoo hash、同态多项式明文、密文进行参数选择;
- 对服务端数据进行prf计算:prf得到256bit,前128bit根据截取用于匹配,后128bit作为对称算法密钥加密label;
- 根据prf前128bit截断后将数据插入Simple Hash;
- 对Simple Hash每一行分别划分bin bundle,并计算相应的差值多项式matching polynomial和label polynomial;
- 将插值多项式系统packing到同态算法明文。

客户端和服务端(query)阶段-流程:
- 客户端向服务端请求参数;
- 执行oprf协议;
- 计算查询值的同态密文幂集合;
- 使用同态私钥解密服务端返回的同态密文;
- 满足匹配条件时,使用oprf的后128bit解密得到label。

Lable PIR的主要参数: ItemParams每个元素在明文多项式对应的系数;TableParams包括cuckoo hash个数和表大小;QueryParams查询次数;SEALParams同态参数包括多项式次数(明文模/密文模)。
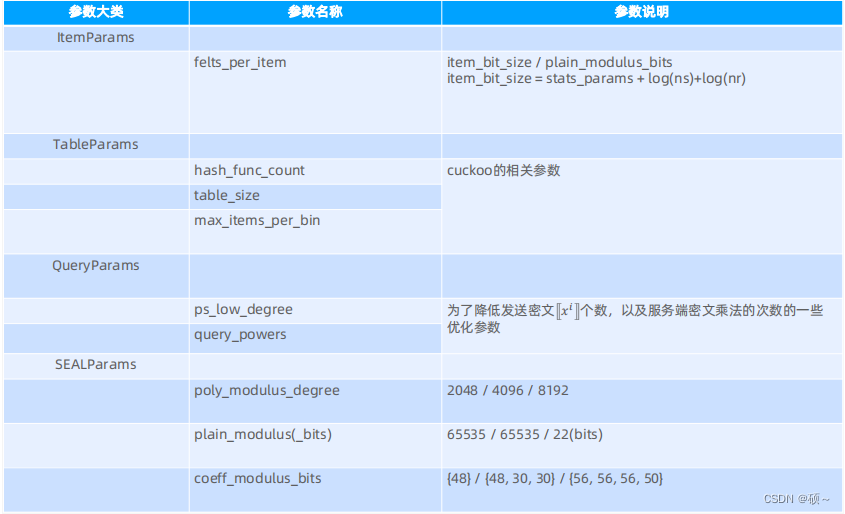
PIR实现位置:

四、隐语PIR后续计划

这篇关于隐私计算实训营学习六:隐语PIR介绍及开发指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






