本文主要是介绍2010-2021年各省碳排放测算数据(含原始数据+计算过程+结果),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2010-2021年各省碳排放测算数据(含原始数据+计算过程+结果)
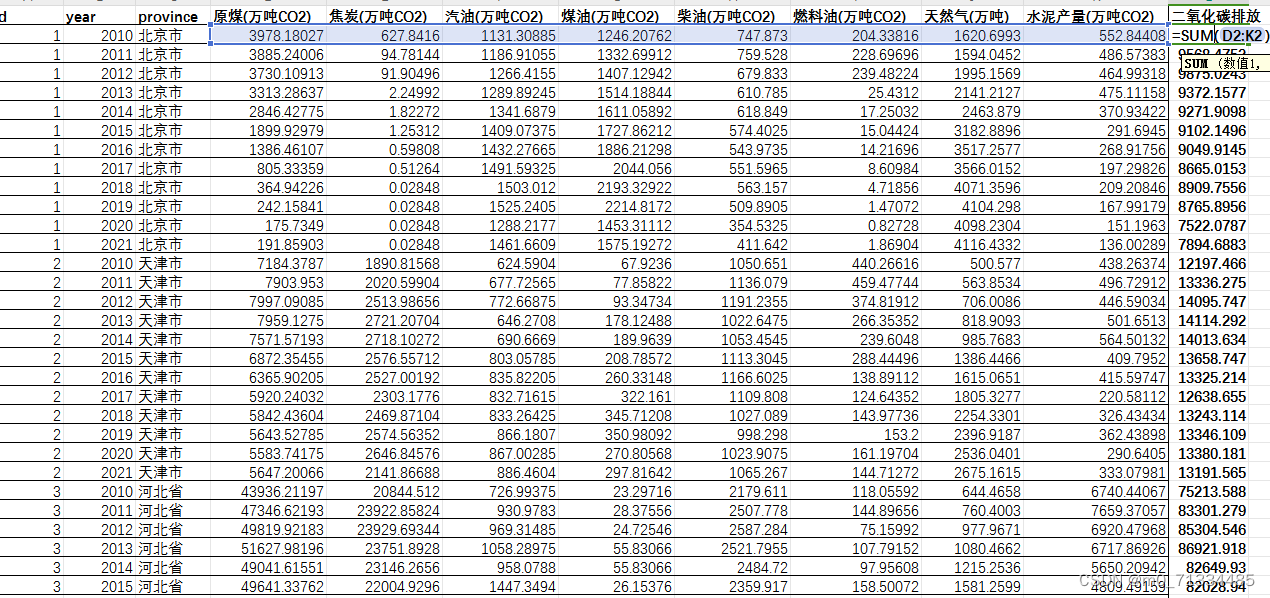
1、时间:2010-2021年
2、指标:原煤(万吨)、原煤(万吨CO2)、焦炭(万吨)、焦炭(万吨CO2)、汽油(万吨)、汽油(万吨CO2)、煤油(万吨)、煤油(万吨CO2)、柴油(万吨)、柴油(万吨CO2)、燃料油(万吨)、燃料油(万吨CO2)、天然气(亿立方米)、天然气(万吨)、水泥产量(万吨)、水泥产量(万吨CO2)、二氧化碳排放
3、来源:各省年鉴、能源年鉴、国家统计局
4、范围:30个省份
5、计算方法:采用焦炭、煤炭、煤油、柴油、汽油、燃料油及天然气等7种化石燃料与水泥产量折算而得
6、参考文献:
朱东波,任力,刘玉.中国金融包容性发展、经济增长与碳排放[J].中国人口·资源与环境,2018,28(02):66-76.
杜立民.我国二氧化碳排放的影响因素:基于省级面板数据的研究[J].南方经济,2010,No.254(11):20-33.
7、下载链接:
2010-2021年各省二氧化碳排放数据(含原始数据+计算过程+结果)![]() https://download.csdn.net/download/m0_71334485/89019512
https://download.csdn.net/download/m0_71334485/89019512
这篇关于2010-2021年各省碳排放测算数据(含原始数据+计算过程+结果)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







