本文主要是介绍MIPI CSI-2 Low Level Protocol解读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Low Level Protocol介绍
LLP 是一种面向字节的基于数据包的协议,支持使用短数据包和长数据包格式传输任意数据。为简单起见,本节中的所有示例均为单通道配置。
LLP特性:
-
传输任意数据(与有效载荷无关)
-
8 位字大小
-
在同一链路上支持多达四个交错的虚拟通道
-
用于帧开始、帧结束、行开始和行结束信息的特殊数据包
-
特定于应用程序的有效负载数据的类型、像素深度和格式的描述符
-
用于错误检测的 16 位校验码
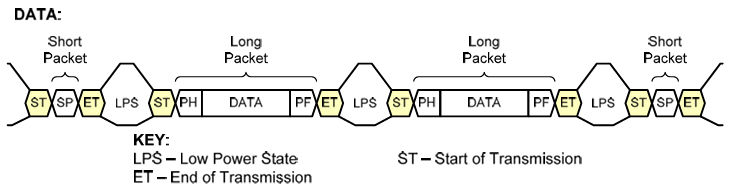
二、LLP Packet Format
LLP通信定义了两种数据包结构: 长包和短包。对于每个数据包结构,从低功耗状态(LPS)退出,后跟传输开始 (SoT) 序列表示数据包的开始。传输结束 (EoT) 序列后跟低功耗状态(LPS)表示数据包结束。
2.1 Long Packet Format
长数据包应由三个元素组成:32 位包头 (PH)、包数据、16位数据包页脚 (PF)。

2.2 Short Packet Format
短包只有SH,没有PH,包含Data ID、Word Count、ECC三部分,WC用来传输短包的数据。
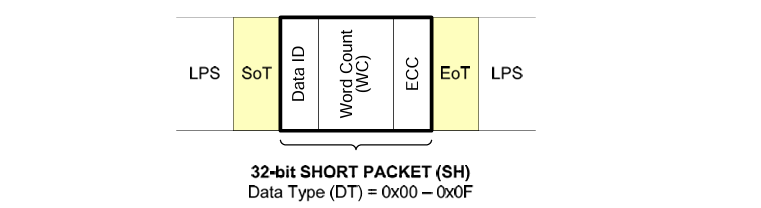
三、Data Identifier(DI)
数据标识符字节包含虚拟通道标识符 (VC) 值和数据类型 (DT) 值。虚拟通道标识符包含在数据标识符字节的两个 MS 位中。数据类型值包含在数据标识符字节的六个 LS 位中。

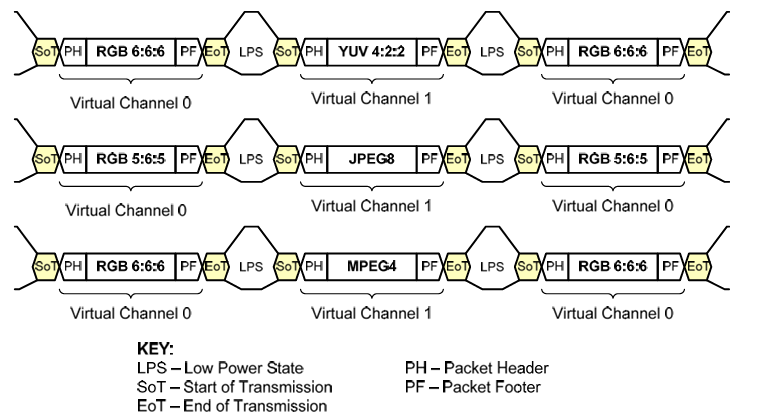
四、Virtual Channel Identifier
虚拟通道标识符的用途是为数据流中交错的不同数据流提供单独的通道。
虚拟通道标识符编号位于数据标识符字节的前两位。接收方将监视虚拟通道标识符,并将交错的视频流解复用到其相应的通道。最多支持四个数据流有效通道标识符为0到3。

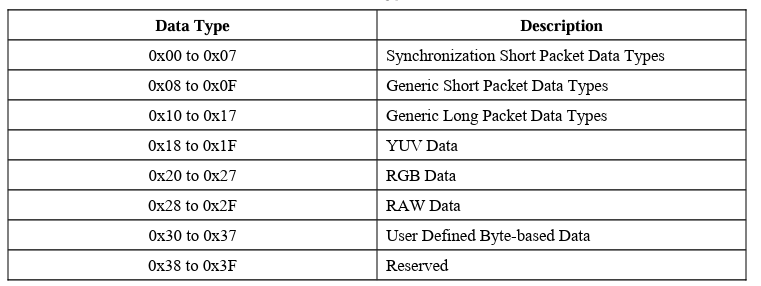
五、Data Type(DT)
“数据类型”值指定有效负载数据的格式和内容。最多支持64种数据类型,共八类,如表所示。在每类中,最多有8个不同的数据类型定义。前两类表示短数据包数据类型。其余六类表示长数据包数据类型。
六、Packet Header Error Correction Code(ECC)
正确地解析数据包的Data Identifier、Word Count和Virtual Channel Extension字段是至关重要的,这是所有后续处理的前提。D-PHY物理层中定义了6-bit包头ECC,能够修正单bit错误,检测2 bits错误,算法细节不是本节重点,想要了解的请自行百度。

七、Checksum Generation
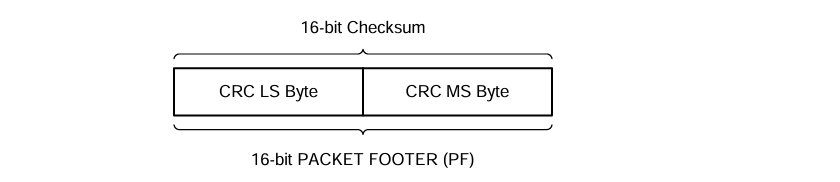
为了检测传输中可能出现的错误,在每个数据包上计算校验和。校验和实现为 16 位 CRC。生成器多项式为 x16+x12+x5+x0。
校验和的传输如图所示
八、Packet Spacing
在LLP数据包之间,必须始终有进出低功耗状态(LPS)的转换。下图显示了LPS的数据包间隔。数据包间隔不必是 8 位数据字的倍数,因为接收方将在 SoT 序列期间重新同步到正确的字节边界,然后再进行下一个数据包的 Packet Header。

注:想要mipi csi-2协议文档的,《MIPI CSI-2.pdf》,请私聊我。
一个专注于“嵌入式知识分享”、“DIY嵌入式产品”的技术开发人员,关注我,一起共创嵌入式联盟。
这篇关于MIPI CSI-2 Low Level Protocol解读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






