本文主要是介绍目标检测之NASNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、目标检测之NASNet
Learning Transferable Architectures for Scalable Image Recognition
- 论文链接:https://arxiv.org/abs/1707.07012
- 论文代码:https://github.com/tensorflow/models/tree/master/research/slim/nets/nasnet
二、NASNet
1、自动产生网络结构
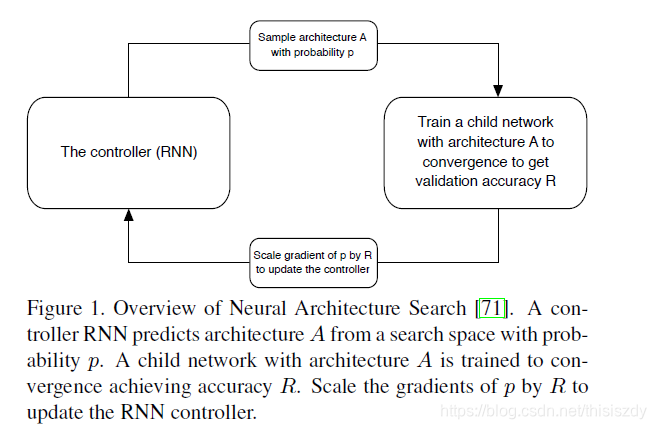
如上图所示,控制器RNN利用概率p从搜索空间预测结构A,一个具有A结构的子网络被训练成收敛性达到精度R,用R缩放p的梯度来更新RNN控制器。
2、采用resnet和Inception重叠使用block结构思想

论文借鉴了目前主流优秀的网络结构(如ResNet和GoogleNet)的重复堆叠思想,使得RNN控制器学习得到也是基本单元convolutional cell,这是和原来的NAS很不一样的地方。论文通过堆叠convolution cell从而构建整个网络结构,上图所示就是基于这两种cell在不同数据集上构建的网络结构。
为了生成可扩展的网络结构并且能够结构任意size的图像,基于此论文设计的convlolution cell主要包含两种:
- Normal Cell:不改变输入feature map的大小的卷积;
- Reduction Cell:将输入feature map的长宽各减少为原来的一半的卷积,是通过增加stride的大小来降低size。
最后RNN控制器用来预测这两种Cell。
3、利用迁移学习将生成的网络迁移到大数据集上提出一个new search space

一个convolution cell由B个block组成,那么一个block又是什么呢,如上图所示,对于每个block来说RNN控制器有5个预测步骤也有5个输出的预测值。每个block的输入是前面的两个block的最后的输出。
预测步骤一共是5个步骤:
- 从h_i,h_i−1或从隐状态的集合中选择一个隐藏的状态,例如上图基本模块的hidden layer A;
- 从与步骤1相同的选项中选择第二个隐藏状态,例如上图基本模块的hidden layer B;
- 选择要应用于步骤1中选择的隐藏状态的操作(黄色框);
- 选择要应用于步骤2中选择的隐藏状态的操作(黄色框);
- 选择一个方法来组合步骤3和步骤4的输出来创建(绿色框);
考虑到计算资源的限制,论文限制了search space,设置B=5。
步骤3和步骤4中选择的操作可以下面的这些选项选择 :

搜索策略:

文章进行了布鲁斯-随机搜索(RS)和强化学习(RL)的对比,得出强化学习(红色)可以获得比随机搜索(蓝色)更好的结果。
最终结构NASNet-A:

4、结果

这篇关于目标检测之NASNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








