本文主要是介绍pyplot绘图基础--------------matplotlib数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# -*- coding: utf-8 -*-
"""
Created on Thu Oct 11 11:14:08 2018@author: Administrator
"""import numpy as np
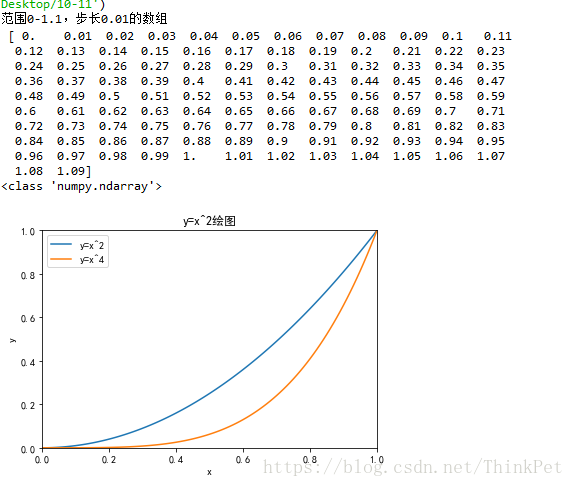
data = np.arange(0, 1.1 , 0.01)
print('范围0-1.1,步长0.01的数组\n',data)
print(type(data))import matplotlib.pyplot as plt
plt.title('y=x^2绘图') #设置标题plt.xlabel('x') #设置x轴名称
plt.ylabel('y') #设置y轴名称'''
x,y轴的范围和刻度可以省略,也可自定义
'''
plt.xlim((0,1)) #设置x轴范围
plt.xticks([0,0.2,0.4,0.6,0.8,1]) #设置x轴刻度
plt.ylim((0,1)) #设置y轴范围
plt.yticks([0,0.2,0.4,0.6,0.8,1]) #设置y轴刻度plt.plot(data,data**2) #绘制y=x^2曲线
plt.plot(data,data**4) #绘制y=x^4曲线
plt.legend( ['y=x^2' , 'y=x^4']) #添加注解
plt.savefig('./y=x^2.png') #保存为png图片
plt.show() #在控制台显示图片
这篇关于pyplot绘图基础--------------matplotlib数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




