本文主要是介绍全国产数据采集卡定制,24位八通道以太网数据采集卡 labview 100K采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
XM702是一款以太网型高速数据采集卡,具有8通 道真差分输入,24位分辨率,单通道最高采样率100ksps八通 道同步共计800ksps、精密前置增益放大、集成IEPE/ICP硬件 支持的特点。本产品采用了多个高精度24位ADC单元及配合本 公司多年积累开发的前置差分放大模块,使得本产品具有高速 率、高分辨率、高精度、超低噪音、高抑制比、测量范围广、 低温漂的优点,适合精密高速率采集的各种场合使用。 LAN通讯采用TCP/IP交换通讯协议并内置防丢包 算法,能长期保证不丢数据稳定传输采集。
采集卡扩展为系列版本,USB型XM702H,LAN插拔连接 器版本XM702。 XM702采采集卡所有元器件皆为工业等级,采用全 金属屏蔽, 可适应工业干扰强烈场合应用,并具有防潮、防震 和抗干扰的优点。
产品特性
| *ADC高达 24 位分辨率,LAN(以太网)端口传输 *输入范围:0 ~±10V *速率高:800ksps; 每通道最高100ksps *可配置 2 路 PWM *可配置 1 路计数输入 *可配置 1 路 DAC 输出 *高精度参考基准:2.5V ±0.05% *可配置外部触发定量采集 *可配置外部时钟同步采集 *内建256M内存解决网络临时断线问题 | *支持SD离线数据存储 *支持IEPE/ICP传输模式软件可切换 *采用高稳定性LAN单元传输稳定可靠 *输入阻抗:1GΩ *ADC 非线性 THD:>100dB *ADC 输入共模信号抑制比:>140dB *温度漂移: <2 μV/°C *金属屏蔽外壳:抗干扰能力强 *整机采用低噪音工业级器件,低温漂,抗干扰能力强 *TCP/IP数据传输CRC校验,数据不丢失 |
产品应用
*微弱信号测量采集 *低噪音数据采集
*以太网组网测量系统 *高阻差分信号测量
采集卡端口示意图
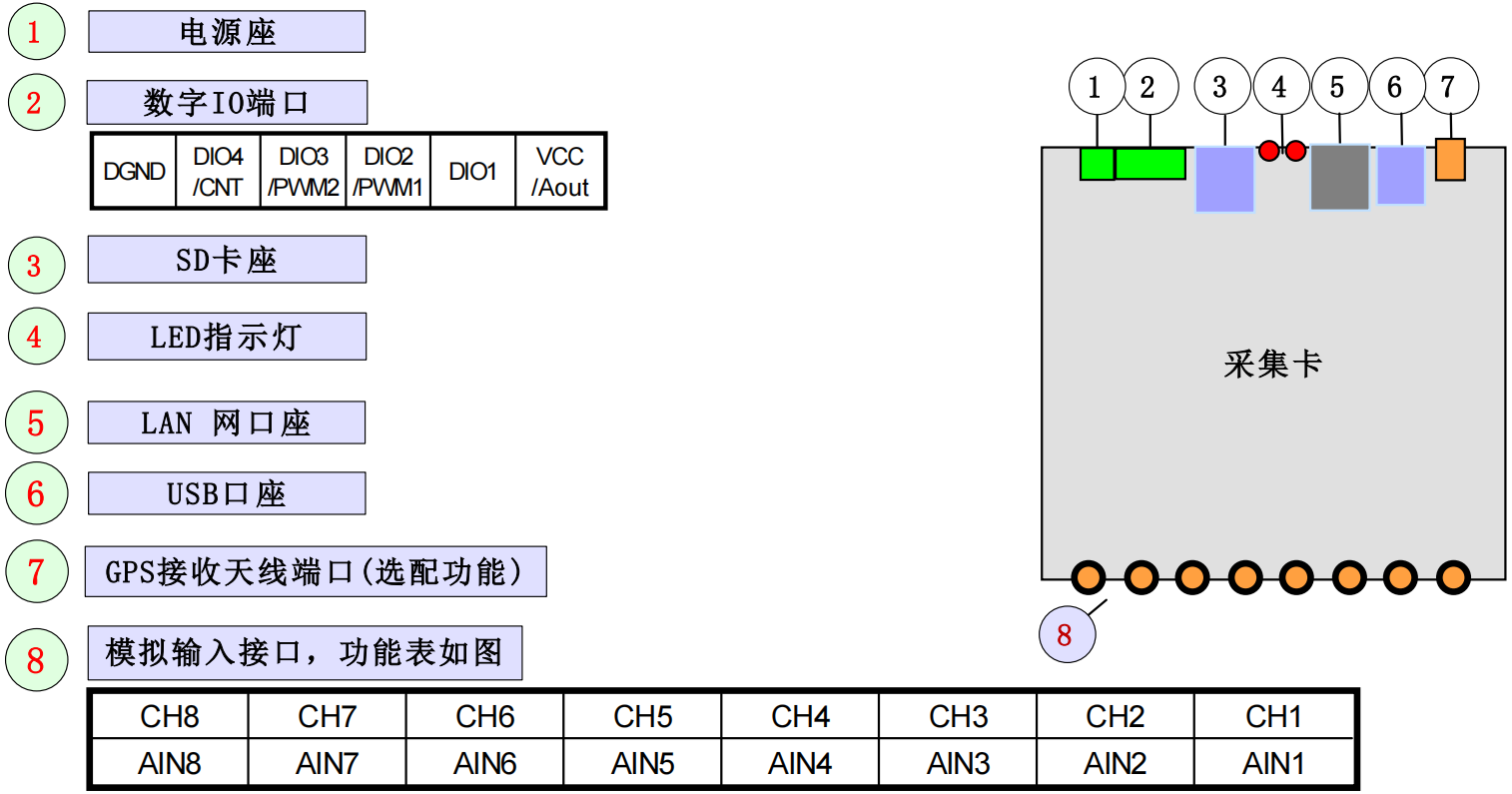
采集100uV正弦波的波形
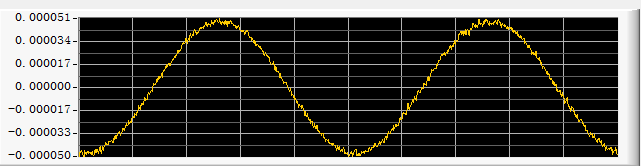
采集2V正弦波的波形
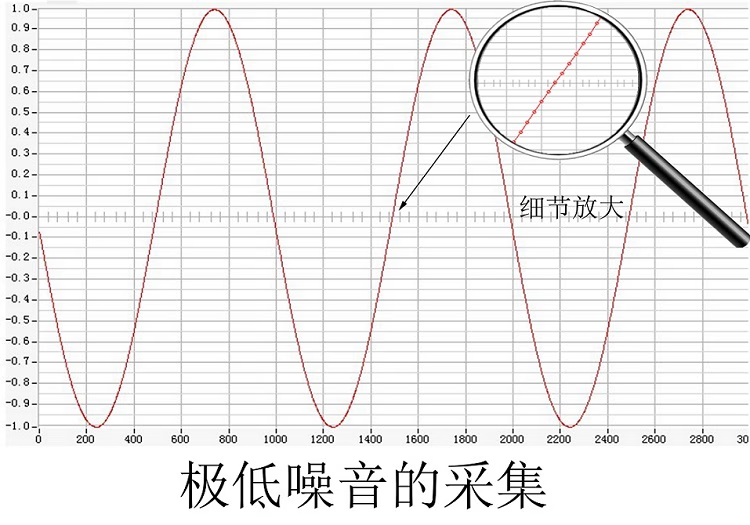
数据保存到EXCEL

配套采集测试软件
采集卡使用软件说明
XM702以太网24位数据采集卡可工作在WIN11/Win10/WIN7、LINUX等常用操作系统中,并提供Python,VB,VC, C#、C++Builder, VB,Delphi,Labview/Labwindows,Matlab等常用编程语言调用的动态链接库,编程函数接口简单易用,易于编写应用程序,提供Python,VB,VC, C#、C++Builder, VB,Delphi,Labview/Labwindows,Matlab等例程。
发货清单
1.采集卡*1
2.1米镀金无氧铜高速数据线*1
3.1米无氧铜网线*1
4.例程等资料包(网盘下载或通过邮箱发送)
这篇关于全国产数据采集卡定制,24位八通道以太网数据采集卡 labview 100K采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





