本文主要是介绍基于哈希槽的docker三主三从redis集群配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、三主三从redis集群配置
1、关闭防火墙+启动docker后台服务
2、新建6个docker容器redis实例
3、进入容器redis-node-1为6台机器构建集群关系
3.1进入容器
3.2构建主从关系
4、查看集群状态
4.1链接进入6381作为切入点
二、主从容错切换迁移按例
1、数据读写存储(防止路由失效加-c参数)
2、查看集群信息
3、主6381和从机切换,先停止主机6381
4、还原之前的3主3从
三、主从扩容按例,四主四从
1、新建6387、6388两个节点,然后观察是否有8个节点。
2、进入6387容器实例内部,将新增的6387节点(空槽号)作为master节点加入原集群
3、重新分派槽号:
4、为主节点6387分配从节点6388
四、主从缩容案例(6387和6388下线)
1、先清除从节点6388,清出来的槽号重新分配,再删除6387,恢复三主三从。
2、删除6387
3、最后检查集群情况
一、三主三从redis集群配置
1、关闭防火墙+启动docker后台服务
systemctl stop firewalld
systemctl start docker
2、新建6个docker容器redis实例
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386注解:
docker run 创建并运行docker容器实例
--name redis-node-6 容器名字
--net host 使用宿主机的IP和端口,默认
--privileged=true 获取宿主机root用户权限
-v /data/redis/share/redis-node-6:/data 容器卷,宿主机地址:docker内部地址
redis:6.0.8redis 镜像和版本号
--cluster-enabled yes 开启redis集群
--appendonly yes 开启持久化
--port 6386 redis端口号
3、进入容器redis-node-1为6台机器构建集群关系
3.1进入容器
docker exec -it redis-node-1 /bin/bash3.2构建主从关系
注意自己的真实ip地址
redis-cli --cluster create 192.168.80.171:6381 192.168.80.171:6382 192.168.80.171:6383 192.168.80.171:6384 192.168.80.171:6385 192.168.80.171:6386 --cluster-replicas 1--cluster-replicas 1表示为每一个master创建一个slave节点
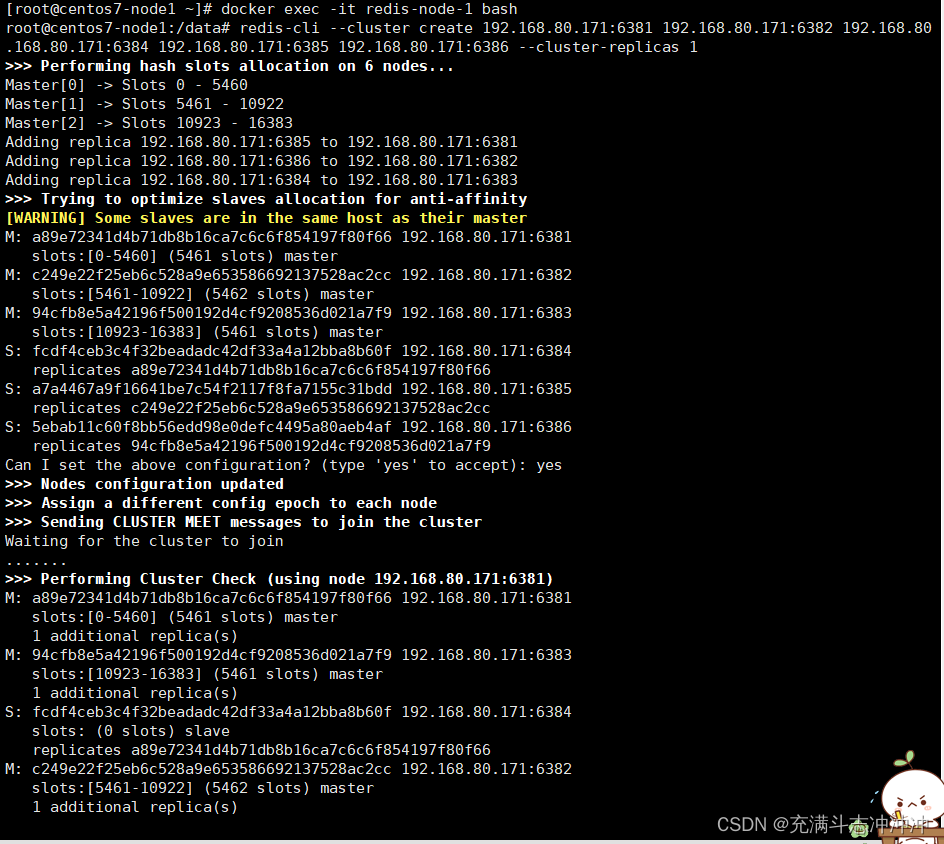
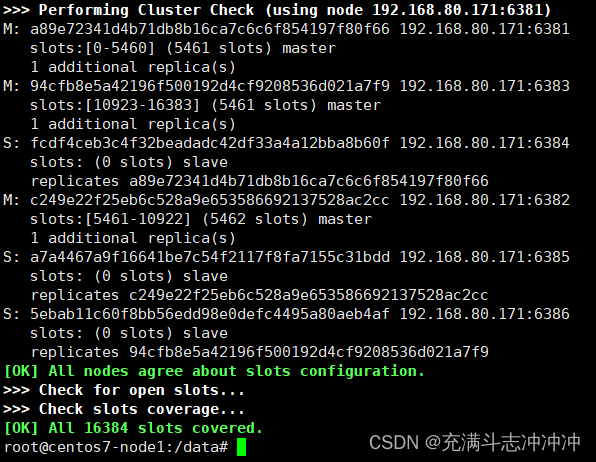
4、查看集群状态
4.1链接进入6381作为切入点
redis-cli -p 6381
cluster info
cluster nodes
二、主从容错切换迁移按例
1、数据读写存储(防止路由失效加-c参数)
redis-cli -p 6381 -c
不加-c的时候
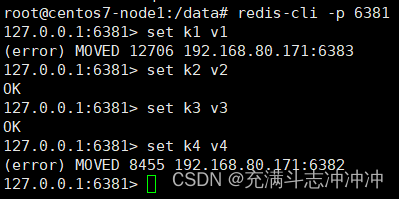
加-c的时候

2、查看集群信息
redis-cli --cluster check 192.168.80.171:6381

3、主6381和从机切换,先停止主机6381
docker stop redis-node-16381作为1号主机分配的从机以实际情况为准,具体是几号机器就是几号

再次查看集群信息
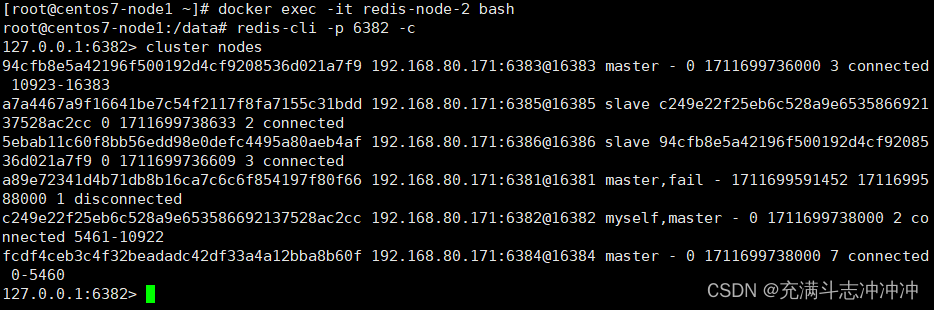
6381宕机了,6384上位成为了新的master。
备注:本次脑图笔记6381为主下面挂从6384。
每次案例下面挂的从机以实际情况为准,具体是几号机器就是几号
4、还原之前的3主3从
先启用6381
docker start redis-node-1
发现node1变成从了
再停止6384
docker stop redis-node-4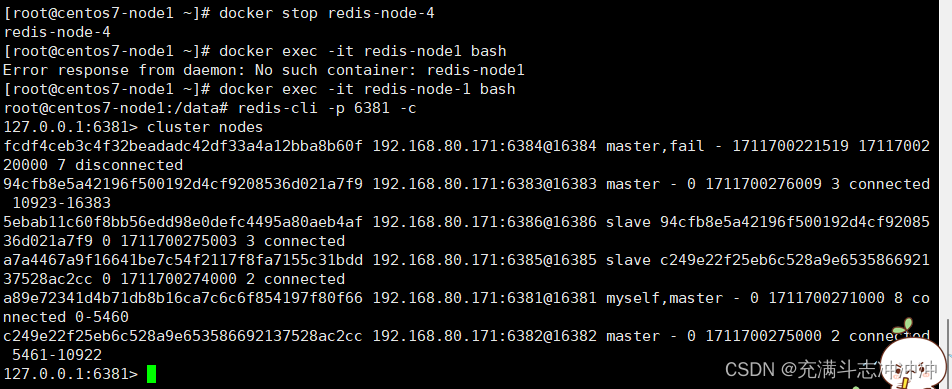
node1变成主了,node4宕机状态。
再启动6384
docker start redis-node-5
发现node1还是主,node4变成从了。
三、主从扩容按例,四主四从
1、新建6387、6388两个节点,然后观察是否有8个节点。
docker run -d --name redis-node-7 --net host --privileged=true -v /data/redis/share/redis-node-7:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6387docker run -d --name redis-node-8 --net host --privileged=true -v /data/redis/share/redis-node-8:/data redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6388
2、进入6387容器实例内部,将新增的6387节点(空槽号)作为master节点加入原集群
docker exec -it redis-node-7 bash[root@centos7-node1 ~]# docker exec -it redis-node-7 bash
root@centos7-node1:/data# redis-cli --cluster add-node 192.168.80.171:6387 192.168.80.171:6381
将新增的6387作为master节点加入集群
redis-cli --cluster add-node 自己实际IP地址:6387 自己实际IP地址:6381
6387 就是将要作为master新增节点
6381 就是原来集群节点里面的领路人,相当于6387拜拜6381的码头从而找到组织加入集群

检查集群情况第一次
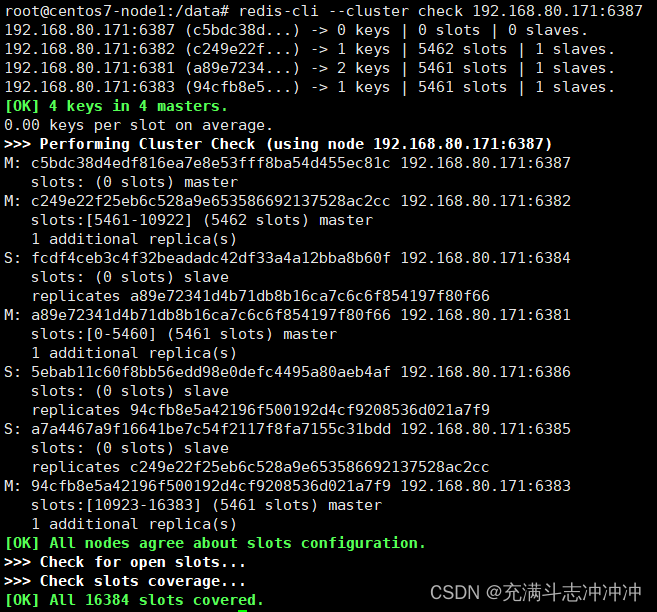
3、重新分派槽号:
redis-cli --cluster reshard 192.168.80.171:6381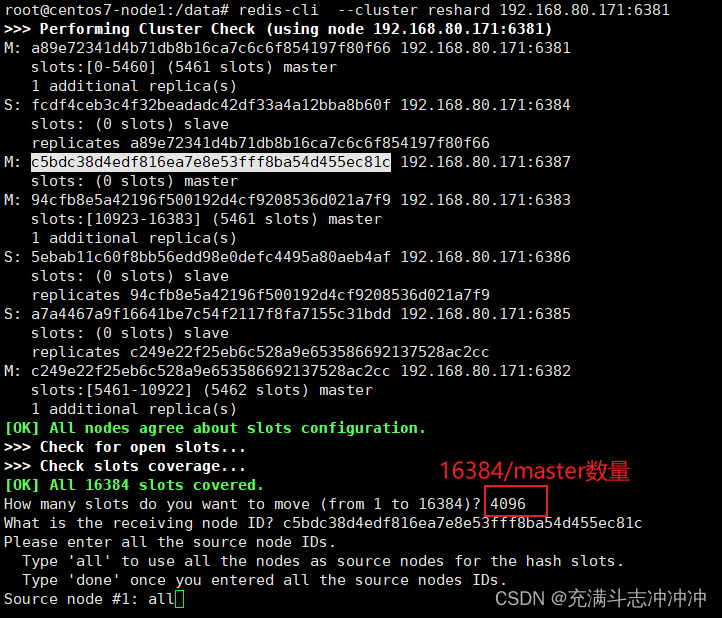
检查集群情况第2次

为什么6387是3个新的区间,以前的还是连续?
重新分配成本太高,所以前3家各自匀出来一部分,从6381/6382/6383三个旧节点分别匀出1364个坑位给新节点6387
4、为主节点6387分配从节点6388
root@centos7-node1:/data# redis-cli --cluster add-node 192.168.80.171:6388 192.168.80.171:6387 --cluster-slave --cluster-master-id c5bdc38d4edf816ea7e8e53fff8ba54d455ec81c命令:redis-cli --cluster add-node ip:新slave端口 ip:新master端口 --cluster-slave --cluster-master-id 新主机节点ID
检查集群情况第3次
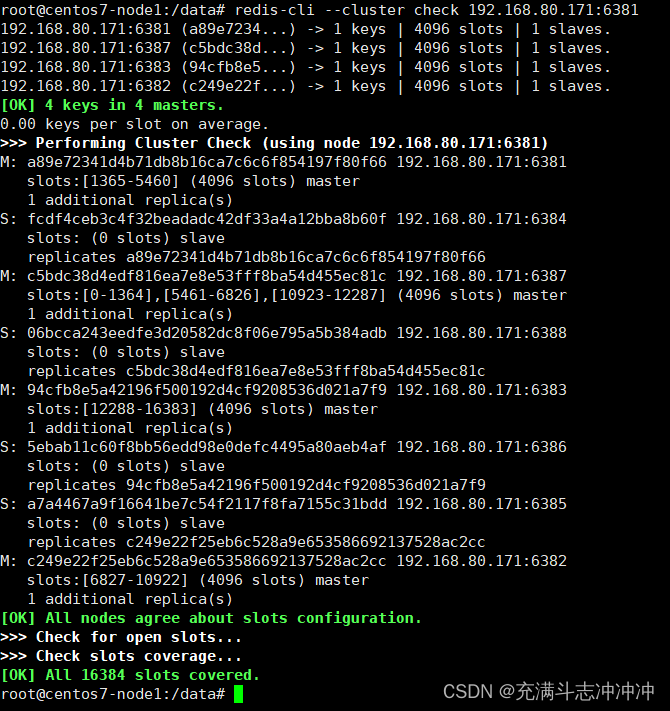
四、主从缩容案例(6387和6388下线)
1、先清除从节点6388,清出来的槽号重新分配,再删除6387,恢复三主三从。
redis-cli --cluster del-node 192.168.80.171:6388 06bcca243eedfe3d20582dc8f06e795a5b384adb redis-cli --cluster reshard 192.168.80.171:6381
#将6387的槽号清空,重新分配,本例将清出来的槽号都给6381
将6387的槽位全部分配给6381

检查集群情况第一次

输入4096个槽位都指给6381,它变成了8192个槽位,相当于全部都给6381了,不然要输入3次,一锅端
2、删除6387
redis-cli --cluster del-node 192.168.80.171:6387 c5bdc38d4edf816ea7e8e53fff8ba54d455ec81c
3、最后检查集群情况
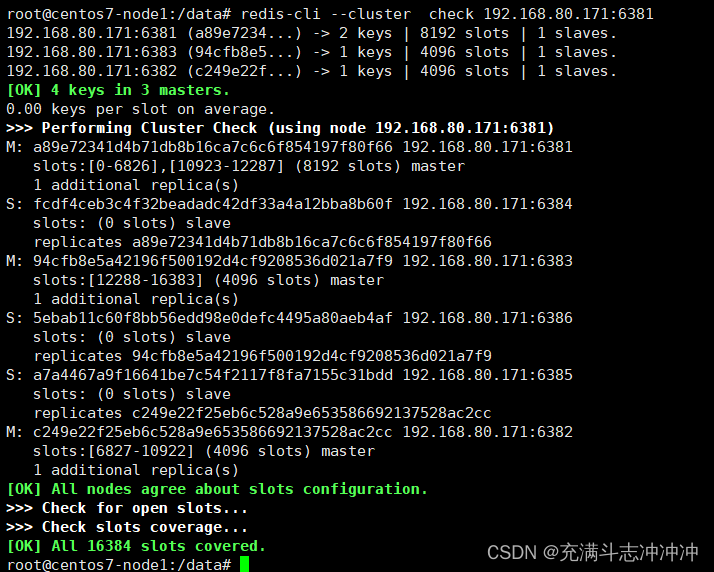
最后恢复成三主三从了
这篇关于基于哈希槽的docker三主三从redis集群配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







