本文主要是介绍IO流:从键盘录入数据,将数据变成大写打印在控制台上,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【需求】:从键盘录入数据,将数据变成大写打印在控制台上
【代码】:
import java.io.IOException;
import java.io.InputStream;public class SystemInDemo {public static void main(String[] args) throws IOException {InputStream is=System.in;StringBuilder sb=new StringBuilder();while(true){int ch=is.read();if(ch=='\r'){continue;} else if(ch=='\n'){String str=sb.toString();if("over".equals(str)){break;}System.out.println(str.toUpperCase());sb.delete(0,str.length());}else{sb.append((char)ch);}}is.close();}
}
【输出】:
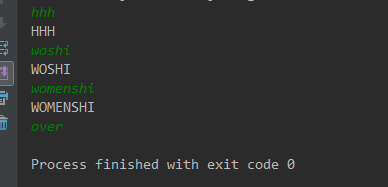
【常见问题】:
1.如果没有sb.delete(0,str.length())

无法停止,且一直会显示前一行的数据。
2.

这种导致的原因是:没有放在else块中,那么每次执行完前两个条件语句,还会执行这一句,就是会将\r\n加在str后面,所以会导致打印结果空出一行。即:

【升级版】
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;/*** 键盘录入升级版*/
public class SystemInDemo2 {public static void main(String[] args) throws IOException {//获取键盘录入对象InputStream in=System.in;//将字节流对象转换成字符流对象InputStreamReader isr=new InputStreamReader(in);//将字符流对象引入缓冲区BufferedReader bufr=new BufferedReader(isr);String line=null;while(true){line=bufr.readLine();if(line.equals("over")){break;}else{System.out.println(line.toUpperCase());}}}
}
这篇关于IO流:从键盘录入数据,将数据变成大写打印在控制台上的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





