本文主要是介绍基于双vip+GTID的半同步主从复制集群项目(MySQL集群),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
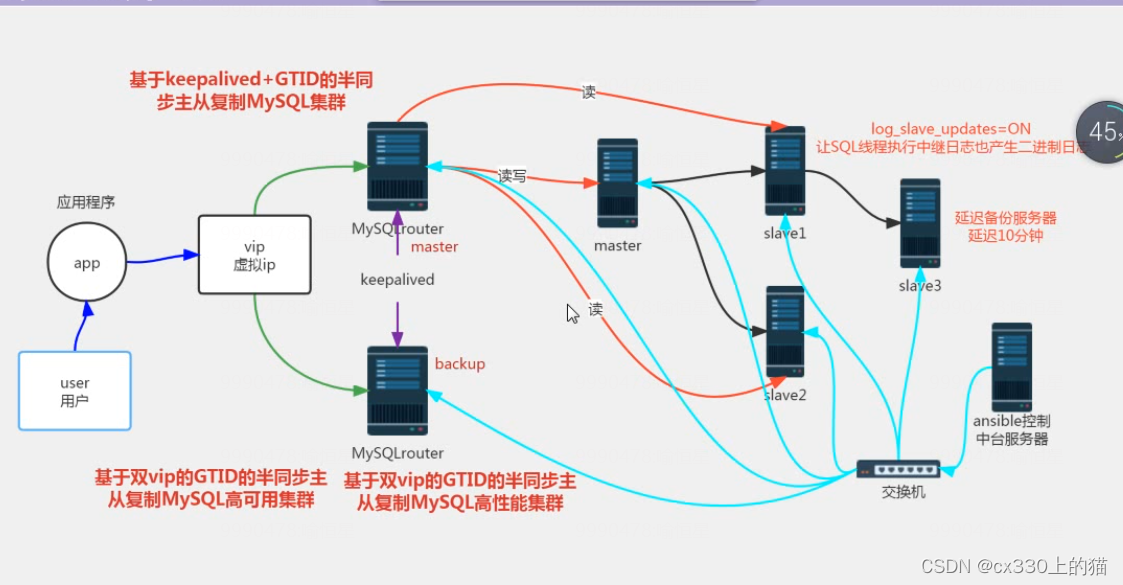
项目标题:基于keepalived+GTID的半同步主从复制MySQL集群
准备七台机器,其中有四台时MySQL服务器,搭建主从复制的集群,一个master,2个slave服务器,一个延迟备份服务器。同时延迟备份服务器也可以充当异地备份服务器,数据从master或者slave上导出,然后rsync到备份服务器。
2台MySQL router服务器,安装好keeplived软件,实现高可用的读写分离服务。
一台ansible中控服务器,显现对MySQL整个集群内的服务器进行批量管理。
项目步骤:
搭建好4台MySQL数据库服务器,安装好mysql系统
- 每台机器都要安装mysql,使用scp将mysql文件传过去,安装好;
对于ansible中控机,需要安装ansible:
配置好ansible:
yum install epel-release -y;
yum install ansible -y;
- 搭建好一台master,三台半同步slave机(开启二进制日志,安装半同步插件,开启半同步配置参数)
在master上新建一个授权用户,给slave复制二进制文件使用:
root@(none) 06:52 mysql>grant replication slave on *.* to 'project'@'192.168.10.%' identified by 'Sanchuang123#';
一台配置成master机,打开二进制文件,安装半同步插件,开启半同步配置参数;其余几台根据各自的配置参数配置好;
配置好后,service mysqld stop 以及service mysqld start;
至此,一台master、两台slave机,一台延迟备份的slave机你,一台ansible都配置好了。
3、将master机的数据库导出成一个sql文件all_db.sql。
安装ansible服务器,通过ansible导入数据到各台机器
1、ansible配置文件中定义主机清单,把管理的主机IP写进去:
[db]
192.168.10.144
192.168.10.145
192.168.10.146
192.168.10.147
[dbslaves]
192.168.10.145
192.168.10.146
192.168.10.147
2、让ansible中控机与所有的MySQL节点服务器建立免密通道,测试通道是否建立成功。
3、在ansible机器上拿到master的基础数据:scp root@192.168.10.144:/root/all_db.sql拿到sql文件。
将基础数据上传到所有slave机器上:ansible -m copy -a “src=/root/all_db.sql dest=/root” dbslaves
将数据库还原:每台机器使用mysql -uroot -p </root/all_db.sql单独恢复。
错误一:恢复数据的时候报错了
原因:打开了gtid,影响了数据的恢复
解决:关掉配置好的gtid,service mysqld restart重启mysqld服务器,在重传数据。
此时,基础数据都准备好了。
最后再把GTID功能打开,启动主从复制功能;
1、在所有slave上指定master:
root@(none) 01:20 mysql>CHANGE MASTER TO MASTER_HOST='192.168.10.144',
-> MASTER_USER='project',
-> MASTER_PASSWORD='Sanchuang123#',
-> MASTER_PORT=3306,
-> MASTER_AUTO_POSITION=1;
root@(none) 01:20 mysql>start slave;
错误二:配置完之后,slave中的I/O线程没有被打开(之后延迟备份那台slave的线程打开了)。
原因:受到以前配置的影响,slave的GTID比master上的GTID还大,也就是slave上的数据比master上的数据还多。
解决:在所有的slave上清除master信息和slave信息。
root@(none) 01:20 mysql>reset master;
root@(none) 01:20 mysql>stop slave;
root@(none) 01:20 mysql>reset slave all;
root@(none) 01:20 mysql>CHANGE MASTER TO MASTER_HOST='192.168.10.144',
-> MASTER_USER='project',
-> MASTER_PASSWORD='Sanchuang123#',
-> MASTER_PORT=3306,
-> MASTER_AUTO_POSITION=1;
root@(none) 01:20 mysql>start slave;
root@(none) 01:20 mysql>show slave status\G;(查看是否打开I/O线程)
检测主从复制是否配置正确;此时GTID编号都一样。
延迟备份的slave机的配置:开启延迟备份功能,从slave1延迟备份数据。
root@(none) 01:20 mysql>reset master;
root@(none) 01:20 mysql>stop slave;
root@(none) 01:20 mysql>reset slave all;
root@(none) 01:20 mysql>CHANGE MASTER TO MASTER_HOST='192.168.10.145',
-> MASTER_USER='project',
-> MASTER_PASSWORD='Sanchuang123#',
-> MASTER_PORT=3306,
-> MASTER_AUTO_POSITION=1;
root@(none) 01:20 mysql>CHANGE MASTER TO MASTER_DELAY=100;(单位是秒)
root@(none) 01:20 mysql>start slave;
测试延迟备份是否成功;
在master上创建备份脚本和备份任务,每天2:30同步数据
备份脚本:
[root@sc-master backup]# cat alldb.sh
#!/bin/bash
mkdir -p /backup
mysqldump -uroot -p'Sanchuang123#' --all-databases --triggers --routines --events >/backup/$(date +%Y%m%d%H%M%S)_all_db.sql
scp /backup/$(date +%Y%m%d%H%M%S)_all_db.sql 192.168.10.144:/backup
设置计划任务:
Crontab -e
30 2 * * * bash /backup/alldb.sh
实现读写分离的部署:MySQL router
下载MySQL router包,rpm安装,修改配置文件,开启服务。
在master上建立两个授权用户,一个读用户,一个写用户:
root@(none) 01:20 mysql>grant select on *.* to ‘scread’@’%’ identified by ‘Sanchuang123#’;
root@(none) 01:20 mysql>grant all on *.* to ‘scwrite’@’%’ identified by ‘Sanchuang123#’;
启动MySQL router机器:service mysqlrouter restart;
在客户端(虚拟机)上测试读写分离的效果,使用两个账号一个读,一个写。
client----------->MySQL router--------------->master/slave
登录不同的用户,测试完读写分离。
读写分离的关键点:其实是用户的权限,让不同的用户连接不同的端口,最后仍然要到后端的mysql服务器里去验证是否有读写的权限,MySQL router只是做了读写的分流,让应用程序去连接不同的端口。
主要是用户权限的控制,有写权限的用户使用读的端口也可以写。读的用户走写的通道也只能读。
其他的中间件:mycat数据库中间件,使用Java编写。
使用keepalived排除MySQL router的单点故障,实现高可用
关于keepalived知识点:
C语言编写的路由软件,基于传输层的,提供给Linux系统简单而强大的负载均衡和高可用性能。
高可用HA:不会出现单点故障,一个坏了,另外的能顶替,不影响工作,有备份。
实现HA常用软件:heartbeat、keepalived、HAproxy
Keepalived2大核心功能:
-->1、负载均衡loadbalance:ipvs====》lvs软件在Linux内核中已经安装,不需要单独安装。
-->2、高可用:底层基于vrrp协议,虚拟路由器冗余协议。
Vrrp协议:虚拟路由冗余协议。一组路由器协同工作,但仍不同的角色,有master角色,有backup角色:master状态的路由器会承担实际的数据流量转发任务;backup状态的路由器监听master路由器的状态,并在master路由器发生故障时,接替其工作,从而保证业务的平滑切换。
Master是选举上来的;
Vip:虚拟IP地址,这个IP飘到哪里,哪一台机器就是master;谁成为master谁就成为默认网关。
VRRP协议报文是从同一个组播224.0.0.18上传出去的。只有机器上运行了vrrp协议就会收这个报文,然后选举优先级最高的机器成为master,vip飘到这个机器上。
Vrrp协议工作在哪里?--网络层
Vrrp的工作原理:
选举master:
·所有的路由器或者服务器发送vrrp宣告报文,进行选举,必须是相同的vrid和认证密码的,优先级高的服务器或者路由器会被选举为master,其他机器是backup;
·Master定时发送vrrp宣告报文,以便向backup路由器告知自己的存活情况。默认是间隔一秒。
·接收master设备发送的vrrp宣告报文,判断master设备状态是否正常。如果超过一秒没有收到vrrp报文,就认为master挂了,开始重新选举新的master,vip就会漂移到新的master上。
下载mysql router软件,修改配置文件,启用服务,一共配置了两台mysql router。
使用两台机器是为了避免单点故障。使用keepalived实现高可用。
两台机器都安装keepalived:yum insatll keepalived -y
修改配置文件:密码认证,vip,优先级,监听接口,虚拟路由id的编号(两台要一样),一台设置成master,一台设置成backup。
重启服务service keepalived restart;
错误三:使用ip add查看发现,两台MySQL router都被选为master,出现脑裂现象
原因:未关闭防火墙,所以两台机器不能正常通信
解决:service firewalld stop;重启服务service keepalived restart;再ip add就会发现只有一台的IP地址是vip;
脑裂现象:多态机器出现vip。
- 虚拟路由id不一样
- 网络通信有问题
- 认证密码不一样
脑裂有没有危害?如果有危害对业务有什么影响?
答案:没有危害,能正常访问,反而还有负载均衡的作用。脑裂恢复的时候,还是有影响的,会短暂的中断,影响业务。
测试:当master挂掉之后,backup会马上顶上:
此时,vip飘在mysql router 1上面,使用service keepalived stop关闭服务,第二台MySQL router就监听不到master的宣告了,使用ip add就能看到vip已经飘到了mysql router 2上。当mysql router 1恢复服务后,master又会回到MySQL router 1上。
注:
为了实现读写分离,在MySQL router中设置了两个端口,一个实现读7001,一个实现写7002。在MySQLrouter中配置keepalived的配置文件时,bind_address(绑定本机地址)要配置成0.0.0.0,也就是随机ip,因为这个ip是vip分配的,实现MySQL router一个网卡有多个IP。MySQL router其实只是一个分流的工具,主要是用户权限的控制:让不同的用户连接不同的端口,最后仍然是后端的服务器去验证是否有读写的权限。
只有一台MySQL router容易出现单点故障,所以使用keepalived实现HA,keepalived中的vrrp协议实现master的切换。
Keepalived使用组播方式,IP包里的目的IP是一个组播地址。
Keepalived实现主备切换:通过选举比较虚拟ip和路由ip是不是一样的,比较优先级,确定master,配置虚拟ip。当master挂掉了,backup通过监听马上就会发现收不到master的宣告了,虚拟ip就会飘到backup上。
双vip的实现:会有一台router是闲置的,为了避免资源浪费,实现双虚拟ip
做两个vrrp实例,两个vip,两个实例互为主备。
在router1的配置文件中在配置一个backup实例,即一个实例是master,一个实例是backup,虚拟地址要再找一个(192.168.2.186);
在router2的配置文件中在配置一个,master实例,即一个实例是master,一个实例是backup,虚拟地址也是192.168.2.186;
刷新服务:service keepalived restart;
此时ip add:router1的IP是192.168.2.187,router2的IP是192.168.2.186。如果其中一台挂掉了,另一台就会有两个vip,两台机器互为主备。
此时用户怎么知道用哪个?
答:同一个域名对应两个ip,使用dns域名解析做负载均衡。(买一个域名,添加多个ip,就能实现dns解析实现负载均衡实验中用的私网ip,实际上我们要用公网ip)
User----->dns--轮询算法-->192.168.2.187,192.168.2.186
高可用的开源架构:MMM,MHA
OLTP联机事务处理和OLAP联机分析处理:OLTP主要是对数据的增删改,侧重实时性;OLAP主要是对数据的查询,侧重大数据量查询。
MySQL的压力测试工具:Tpcc、Sysbench。
Sysbench的使用:
官方下载MySQL安装源,
Yum install mysql-community-devel automake libtool;
使用香港服务器下载sysbench源码包,传递到当前服务器,下载相关软件,解决软件依赖;
错误四:有很多软件依赖,一直报错;mysql相关库报错有一个密钥;
解决:进入缓存路径,yum localinstall mysql-community-* ,使用localinstall安装下载好的安装包。
安装好sysbench,配置相关文件。
准备一台测试机test-client:
Yum install epel-release源去安装sysbench
Yum install sysbench -y
使用sysbench进行压力测试;
Sysbench实现失败:测试服务器连接中间件服务器时,一定要去连接写的端口7002,不然会导致写数据到从服务器上,因为有两个服务器,会轮询调动到不同的机器,找不到数据库。
要使用写的用户去连接,不然权限不够。
测试结果良好。
压力测试工具:tpcc
Wget下载安装包;解压安装包;安装;
在其他的服务器上连接到读写分离器上,创建tpcc库;
需要在测试的服务器master上创建tpcc库,需要导入表到tpcc库中,需要将tpcc的create_table.sql和add_fkey_idx.sql从test-client服务器上远程拷贝到master上;
然后在master服务器上导入create_table.sql和add_fkey_idx.sql:
Mysql -uroot ‘Sanchuang123#’ tpcc <create_table.sql
Mysql -uroot ‘Sanchuang123#’ add_fkey_idx.sql
加载数据:
进行测试中:模拟写入数据,内存、cpu等消耗很小;
基于keeplived+gtid半同步主从复制的MySQL集群
#基于GTID的半同步主从复制的搭建过程:
- 安装好4台MySQL服务器系统和MySQL软件,安装好半同步相关的插件,开启GTID功能;
- 选一台做master,其他的做slave(有一台做延迟备份服务器);
- 配置好ansible服务器,定义好主机清单;
- 在master上导出基础数据到ansible上,然后ansible下发到所有slave服务器上;
- 在所有slave机器上导入基础数据。
- 开启GTID功能,启动主从复制服务
- 配置延迟备份服务器,从slave1上那二进制日志
- 在master上创建一个计划任务每天进行数据库的备份,编写备份脚本,master和ansible服务器之间建立双向免密通道,方便同步数据。Ansible也可以做一个异地备份服务器。
- 在一台服务器上安装部署了MySQL router,实现读写分离
- 安装keepalived实现高可用,配置两个vrrp实例实现双vip的高可用功能。
- 在dns域名里面添加同一个名字对应2个vip,实现dns的负载均衡。
- 集群的压力测试,sysbench进行测试。
项目心得:
- 一定要规划好整个集群的架构,配置要细心,脚本要提前准备好,边做边修改;
- 防火墙和selinux一定要记得关闭;
- 对MySQL的集群高可用有深入了解
- 对自动化批量部署和监控有更加多的应用和理解
- Keepalived的配置需要更加细心和IP地址的规划有了新的认识
- 对双vip的使用,添加了两条负载均衡记录,实现dns轮询,达到两个vip负载均衡器上的分流。
这篇关于基于双vip+GTID的半同步主从复制集群项目(MySQL集群)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






