本文主要是介绍【XXL-JOB】执行器架构设计和源码解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
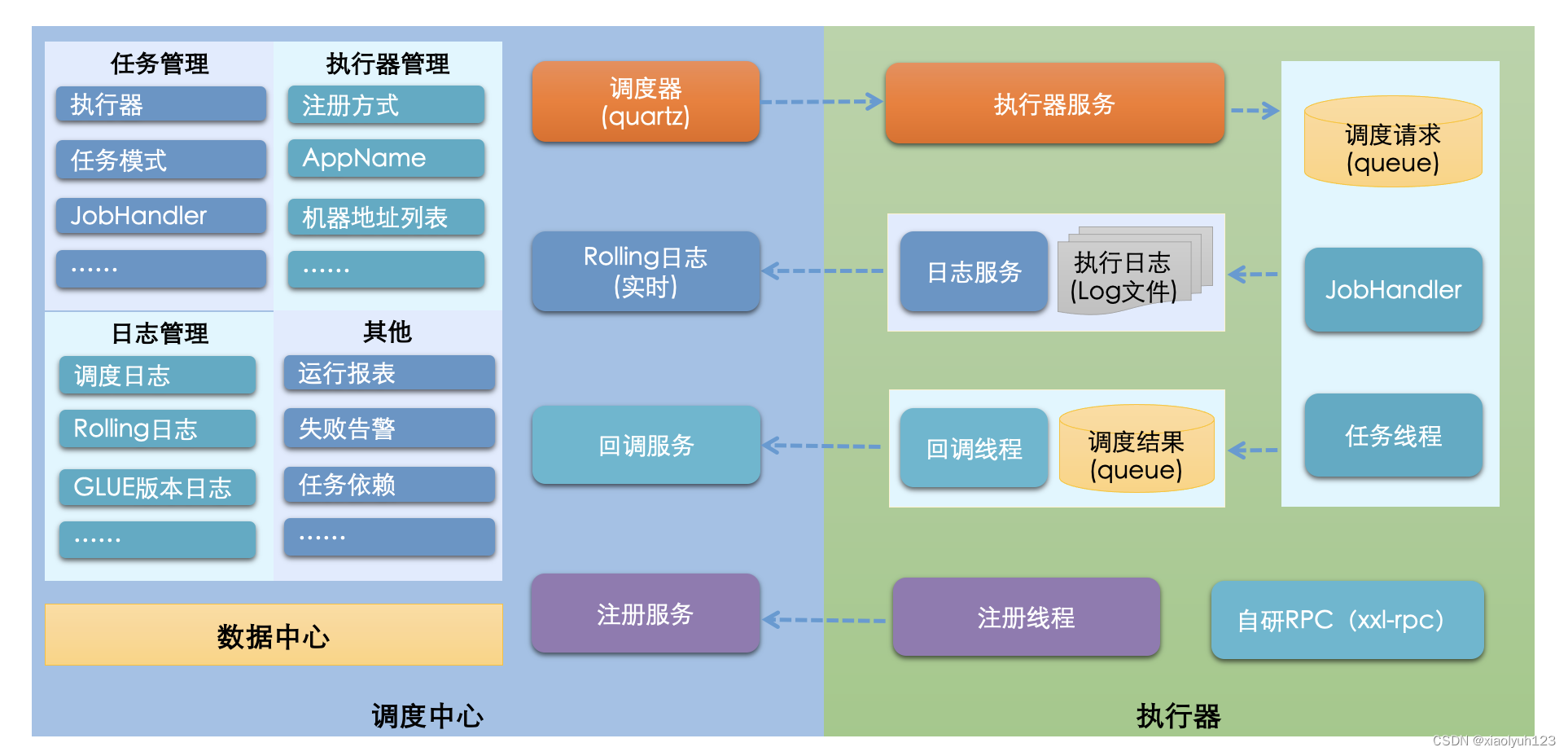
XXL-JOB分为B/S架构,调用中心是XXL-JOB服务端,执行器是客户端。
- 调度中心核心功能:执行器管理、任务管理、任务调度、监控告警和故障转移
- 执行器核心功能:负责业务任务处理,不关心任务调度
XXL-JOB将任务调度和任务执行隔离,将任务调度和执行进行解耦,让研发人员只关注业务部分,提高搞开发效率和系统扩展性。
集成XXL-JOB
添加依赖
<dependency><groupId>com.xuxueli</groupId><artifactId>xxl-job-core</artifactId><version>${最新稳定版}</version>
</dependency>
添加配置
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
以下是我们需要改动的配置:
xxl.job.admin.addresses:调度中心地址,用于自动注册和心跳检测xxl.job.executor.appname:指定执行器名称,每个服务都应该有不同的执行器名称,同一个服务的不同集群节点的执行器名称应该相同xxl.job.accessToken:需要和调度中心配置保持一致,默认是default_tokenxxl.job.executor.port=9999:如果在单机部署多个执行器时,注意要配置不同执行器端口,否则服务启动时会报端口冲突
启动类配置
执行器启动配置支持两种种方式:
- XxlJobSpringExecutor:集成Spring框架【推荐】,不会有类爆炸问题,集成方便
- XxlJobSimpleExecutor:无框架模式,可以参考源码示例
xxl-job-executor-sample-frameless中的FrameLessXxlJobConfig类,优点不限制环境和框架,缺点每个任务就是一个类
这里以XxlJobSpringExecutor为例:
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {logger.info(">>>>>>>>>>> xxl-job config init.");XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();xxlJobSpringExecutor.setAdminAddresses(adminAddresses);xxlJobSpringExecutor.setAppname(appname);xxlJobSpringExecutor.setAddress(address);xxlJobSpringExecutor.setIp(ip);xxlJobSpringExecutor.setPort(port);xxlJobSpringExecutor.setAccessToken(accessToken);xxlJobSpringExecutor.setLogPath(logPath);xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);return xxlJobSpringExecutor;
}
到这里我们的执行器就集成完成啦。
自定义任务处理器
结合上面的配置一个执行器服务就配置好了,现在我们添加一个自定义的任务:
@Component
public class SampleXxlJob {private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);@XxlJob("demoJobHandler")public void demoJobHandler() throws Exception {XxlJobHelper.log("XXL-JOB, Hello World.");for (int i = 0; i < 5; i++) {XxlJobHelper.log("beat at:" + i);TimeUnit.SECONDS.sleep(2);}// default success}
}
开发步骤:
- 任务开发:在Spring Bean实例中,开发Job方法;
- 注解配置:为Job方法添加注解 “@XxlJob(value=“自定义jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)”,注解value值对应的是调度中心新建任务的JobHandler属性的值。
- 执行日志:需要通过 “XxlJobHelper.log” 打印执行日志,这个日志可以在管理端的执行日志被查看;
- 任务结果:默认任务结果为 “成功” 状态,不需要主动设置;如有需求,比如设置任务结果为失败,可以通过
XxlJobHelper.handleFail/handleSuccess自主设置任务结果; - 在调度中心配置任务调度
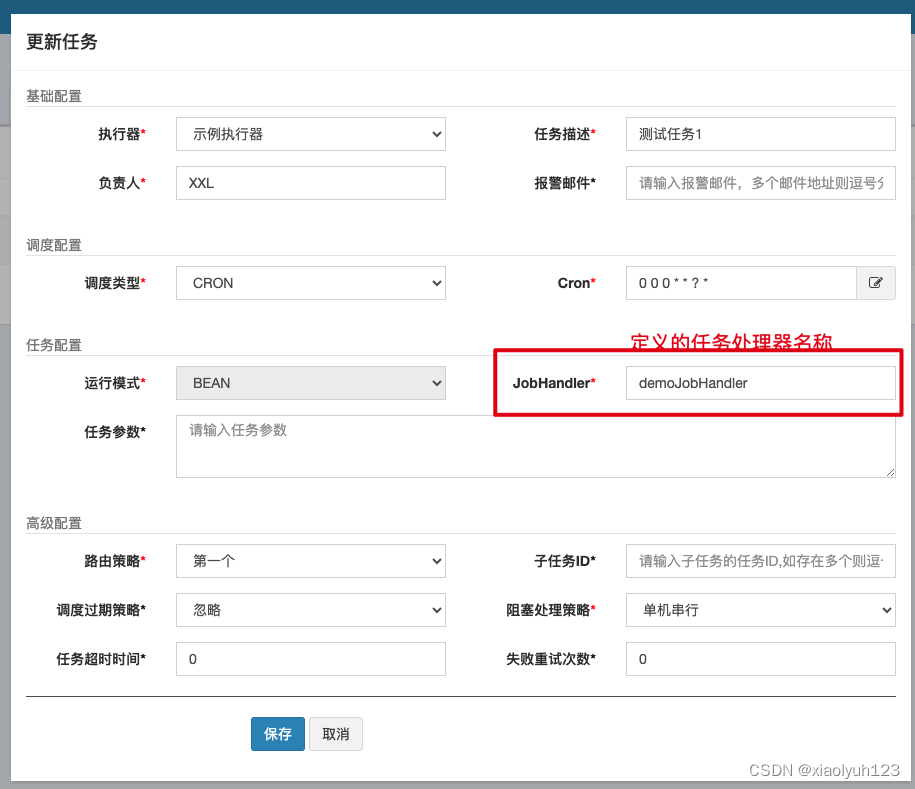
任务类型
这列演示的是最简单的任务,XXL_JOB还支持更为复杂的任务,任务分类:
- 简单任务示例(Bean模式):定义一个Spring Bean,其中包含要执行的任务方法。
- 分片广播任务:允许将一个大任务拆分成多个小任务,并在多个执行器实例上并行执行。这通常用于大数据处理或并行计算。
- 命令行任务:允许直接执行系统命令或脚本。
- 跨平台Http任务:通过HTTP请求来触发任务。在XXL-JOB调度中心添加任务时,选择HTTP模式,并配置相应的URL、请求方法和参数。
- 生命周期任务示例:任务初始化与销毁时,支持自定义相关逻辑,常用于资源准备和清理工作。;
命令行任务和跨平台Http任务都是通过传入指定的参数在JOB中实现的任务操作,具体实现给可以看源码。
运行模式
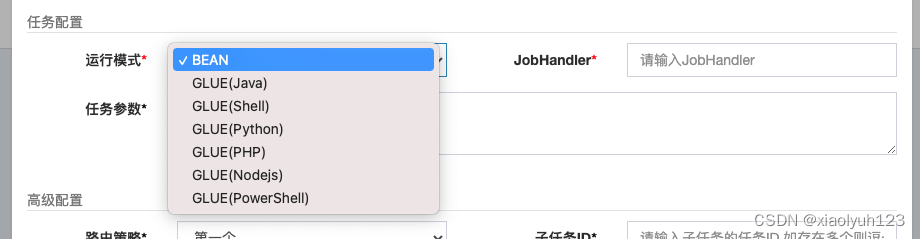
这里的运行模式大致可以分为两种BEAN和````GLUE```。
BEAN:就是刚刚提到的简单示例的模式,也是最常用的模式。GLUE:允许你在线编写任务的执行代码。你可以使用Groovy语言编写代码,并在XXL-JOB的Web界面上直接运行和调试。
GLUE示例
然后在线编辑任务,实现任务调度。

11:06:56.418 logback [xxl-job, EmbedServer bizThreadPool-1281151494] INFO c.x.job.core.executor.XxlJobExecutor - >>>>>>>>>>> xxl-job regist JobThread success, jobId:3, handler:com.xxl.job.core.handler.impl.GlueJobHandler@7ae04e7a
GLUE任务测试
任务执行成功。
执行器生命周期
当服务启动后会通过XxlJobSpringExecutor去集成执行器,集成过程中就会完成执行器自动注册。
public class XxlJobExecutor {public void start() throws Exception {// init logpathXxlJobFileAppender.initLogPath(logPath);// init invoker, admin-clientinitAdminBizList(adminAddresses, accessToken);// init JobLogFileCleanThreadJobLogFileCleanThread.getInstance().start(logRetentionDays);// init TriggerCallbackThreadTriggerCallbackThread.getInstance().start();// init executor-serverinitEmbedServer(address, ip, port, appname, accessToken);}
}
XxlJobFileAppender.initLogPath(logPath);:执行日志路和GULE源码路径初始化initAdminBizList(adminAddresses, accessToken);:初始化调用调度中心的RPC工具JobLogFileCleanThread.getInstance().start(logRetentionDays);:初始化日志定期清楚守护线程TriggerCallbackThread.getInstance().start();:初始化任务执行结果通知调度中心的回调守护线程initEmbedServer(address, ip, port, appname, accessToken);:初始化执行器服务端线程
启动内嵌服务 EmbedServer
在上诉执行器完成初始化后会启动嵌入式服务。
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);
start方法中第一步会启动一个内嵌的netty服务器。
// start server
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup).channel(NioServerSocketChannel.class).childHandler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel channel) throws Exception {channel.pipeline().addLast(new IdleStateHandler(0, 0, 30 * 3, TimeUnit.SECONDS)) // beat 3N, close if idle.addLast(new HttpServerCodec()).addLast(new HttpObjectAggregator(5 * 1024 * 1024)) // merge request & reponse to FULL.addLast(new EmbedHttpServerHandler(executorBiz, accessToken, bizThreadPool));}}).childOption(ChannelOption.SO_KEEPALIVE, true);// bind
ChannelFuture future = bootstrap.bind(port).sync();logger.info(">>>>>>>>>>> xxl-job remoting server start success, nettype = {}, port = {}", EmbedServer.class, port);
内嵌服务启动后会对外暴露接口给调度中心使用,完成执行器与调度中心的通讯。
/beat:调度中心故障探测接口,当任路由策略务配置为故障转移时是调用这个接口探活/idleBeat:忙碌检测接口,当任务路由策略配置为忙碌转移时调用这个接口/run:任务触发接口/kill:任务终止接口/log:在调用中心查看任务执行日志时调用这个接口
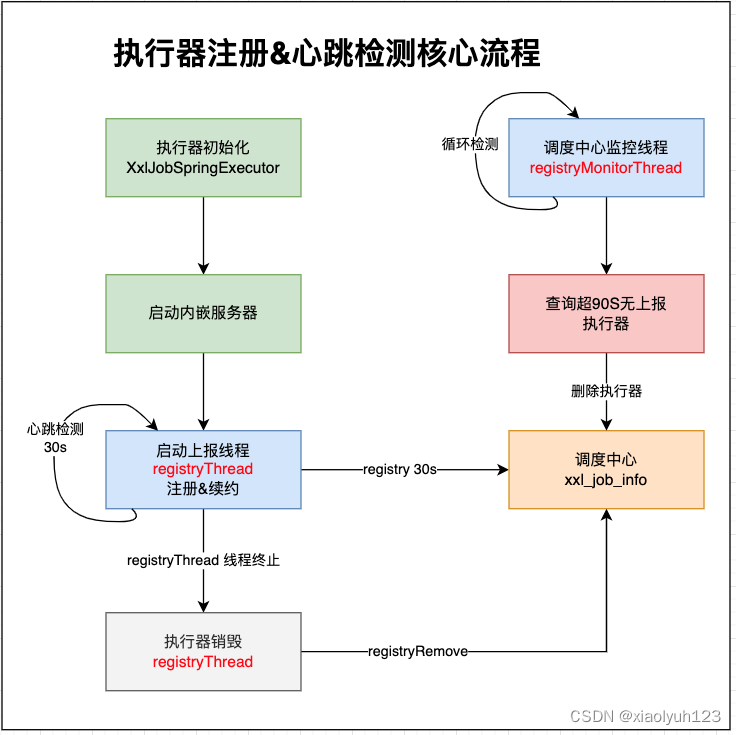
执行器注册&心跳检测 registryThread
启动内嵌服务后就会开始注册执行器到调度中心,执行器注册和心跳检测调用的是调度中心的同一个接口/registry。
ExecutorRegistryThread.getInstance().start(appname, address);
while (!toStop) {try {RegistryParam registryParam = new RegistryParam(RegistryConfig.RegistType.EXECUTOR.name(), appname, address);for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {try {// 调用接口registry接口完成上报ReturnT<String> registryResult = adminBiz.registry(registryParam);if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {registryResult = ReturnT.SUCCESS;logger.debug(">>>>>>>>>>> xxl-job registry success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});break;} else {logger.info(">>>>>>>>>>> xxl-job registry fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});}} catch (Exception e) {logger.info(">>>>>>>>>>> xxl-job registry error, registryParam:{}", registryParam, e);}}} catch (Exception e) {...}try {if (!toStop) {// 每次循环休眠30秒TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);}} catch (InterruptedException e) {...}
}
ExecutorRegistryThread.getInstance().start(appname, address);这里的start方法会启动一个守护线程,一直循环调用调度中心/registry接口,以此完成对注册器的注册和心跳检测- 心跳检测频率为30S一次
- 调用中心有个守护线程每30秒执行一次,每次检查并删除超过90秒没有上报的执行器
执行器销毁 registryThread
当服务停用时会主动调用/registryRemove接口去调度中心销毁执行器
ExecutorRegistryThread.getInstance().toStop();public void start(final String appname, final String address){// validif (appname==null || appname.trim().length()==0) {logger.warn(">>>>>>>>>>> xxl-job, executor registry config fail, appname is null.");return;}if (XxlJobExecutor.getAdminBizList() == null) {logger.warn(">>>>>>>>>>> xxl-job, executor registry config fail, adminAddresses is null.");return;}registryThread = new Thread(new Runnable() {@Overridepublic void run() {...// registry removetry {RegistryParam registryParam = new RegistryParam(RegistryConfig.RegistType.EXECUTOR.name(), appname, address);for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {try {// 调用`/registryRemove`接口去调度中心销毁执行器ReturnT<String> registryResult = adminBiz.registryRemove(registryParam);if (registryResult!=null && ReturnT.SUCCESS_CODE == registryResult.getCode()) {registryResult = ReturnT.SUCCESS;logger.info(">>>>>>>>>>> xxl-job registry-remove success, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});break;} else {logger.info(">>>>>>>>>>> xxl-job registry-remove fail, registryParam:{}, registryResult:{}", new Object[]{registryParam, registryResult});}} catch (Exception e) {...}}} catch (Exception e) {...}}});registryThread.setDaemon(true);registryThread.setName("xxl-job, executor ExecutorRegistryThread");registryThread.start();}
执行器生命周期核心流程
执行定时任务
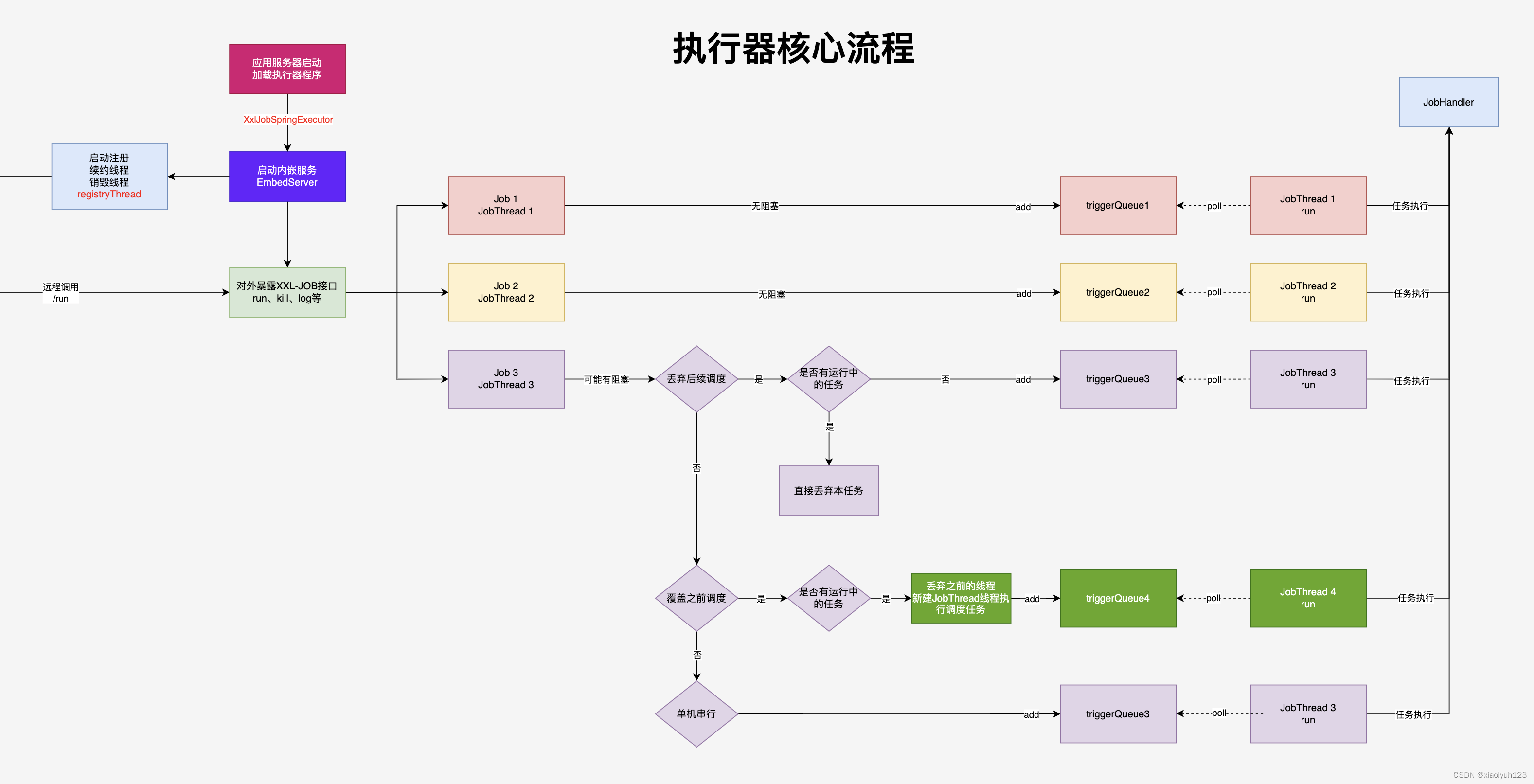
我们执行器初始化完成后执行器就正常注册到调度中心,当任务在时间轮被拿出来后通过调度策略和阻塞策略,最终通过EmbedServer暴露出来的/run接口触发任务执行。
case "/run":TriggerParam triggerParam = GsonTool.fromJson(requestData, TriggerParam.class);return executorBiz.run(triggerParam);
这里会带上几个核心参数:
- jobId:任务ID
- executorHandler:任务执行器名称
- executorParams:执行参数
任务执行线程管理 JobThread
// 执行线程容器
private static ConcurrentMap<Integer, JobThread> jobThreadRepository = new ConcurrentHashMap<Integer, JobThread>();
public static JobThread registJobThread(int jobId, IJobHandler handler, String removeOldReason){JobThread newJobThread = new JobThread(jobId, handler);newJobThread.start();logger.info(">>>>>>>>>>> xxl-job regist JobThread success, jobId:{}, handler:{}", new Object[]{jobId, handler});JobThread oldJobThread = jobThreadRepository.put(jobId, newJobThread); // putIfAbsent | oh my god, map's put method return the old value!!!if (oldJobThread != null) {oldJobThread.toStop(removeOldReason);oldJobThread.interrupt();}return newJobThread;
}
public static JobThread loadJobThread(int jobId){return jobThreadRepository.get(jobId);
}
XXL-JOB会给每个任务创建一个执行线程 JobThread,每个线程会有一个任务队列triggerQueue。每当有任务提交过来会先获取到对应的执行线程,并将任务放到这个线程下的队列中。这个线程如果在30个周期内都没有新任务需要执行,那么这个线程将会被回收。
任务阻塞处理策略 ExecutorBlockStrategyEnum
...
// 如果存在 jobThread 说明可能存在有任务在执行,则需要进行阻塞处理策略
if (jobThread != null) {ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {// 判断是否有任务在执行,如果有则直接丢弃任务if (jobThread.isRunningOrHasQueue()) {return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());}} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {// 判断是否有任务在执行,如果有则覆盖之前的调度if (jobThread.isRunningOrHasQueue()) {removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();jobThread = null;}} else {}
}
...
if (jobThread == null) {jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);
}
...
// 单机串行或者没有任务执行则直接放到线程队列中
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
任务执行JobThread.run()
// execute
while(!toStop){running = false;idleTimes++;TriggerParam triggerParam = null;try {// 获取需要执行的任务triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);if (triggerParam!=null) {// 生成对应的日志文件, 格式为 "logPath/yyyy-MM-dd/9999.log" 999为调度日志的IDString logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());...if (triggerParam.getExecutorTimeout() > 0) {// limit timeoutThread futureThread = null;try {// 超时任务的执行FutureTask<Boolean> futureTask = new FutureTask<Boolean>(new Callable<Boolean>() {@Overridepublic Boolean call() throws Exception {// init job contextXxlJobContext.setXxlJobContext(xxlJobContext);handler.execute();return true;}});futureThread = new Thread(futureTask);futureThread.start();Boolean tempResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);} catch (TimeoutException e) {...} finally {futureThread.interrupt();}} else {// 普通任务的执行handler.execute();}// 任务回调if (XxlJobContext.getXxlJobContext().getHandleCode() <= 0) {XxlJobHelper.handleFail("job handle result lost.");} } else {if (idleTimes > 30) {if(triggerQueue.size() == 0) { // avoid concurrent trigger causes jobId-lostXxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");}}}} catch (Throwable e) {...} finally {...}
}
这里首先需要在对象获取需要执行的任务,如果获取到任务需要直接修改线程运行状态为运行中,再判断是否是超时任务,如果是需要采用FutureTask来执行任务,否则直接执行。任务的执行直接调用Spring注册过来的hander。
执行器核心流程
总结
- 大量采用异步线程来任务调度的性能问题
- 执行器通过心跳机制来保证执行器的可用性
- 通过线程隔离、阻塞策略的方式来解决任务调度的可靠性
- 通过提调度中心dashboard的来解决系统可维护性和可观测性
- 通过
accessToken来解决远程通讯的安全性
XXL-JOB完成流程
源码
https://github.com/xuxueli/xxl-job
引流
GitFlowPlus
GitFlowPlus分支管理IDEA插件
layering-cache
layering-cache 多级缓存开发框架
这篇关于【XXL-JOB】执行器架构设计和源码解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


