本文主要是介绍SuperMap webgl 中使用的gltf模型制作方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
当我们使用Cesium开发KML+GLTF模型表示动态的运动轨迹的时候总会用到gltf格式的模型,但是一般官方的模型库总是只有几个,不能够满足使用,这里整理了一套从数据下载到使用的全家桶套餐供各位看官享用。话不多说,上菜~
目录
一、下载模型
二、下载安装模型转换需要的插件
三、模型开始导出
四、常见问题
一、下载模型
- 注册3d66网站账号,登陆后直接【搜索】需要的模型名称,然后选择【免费】的模型
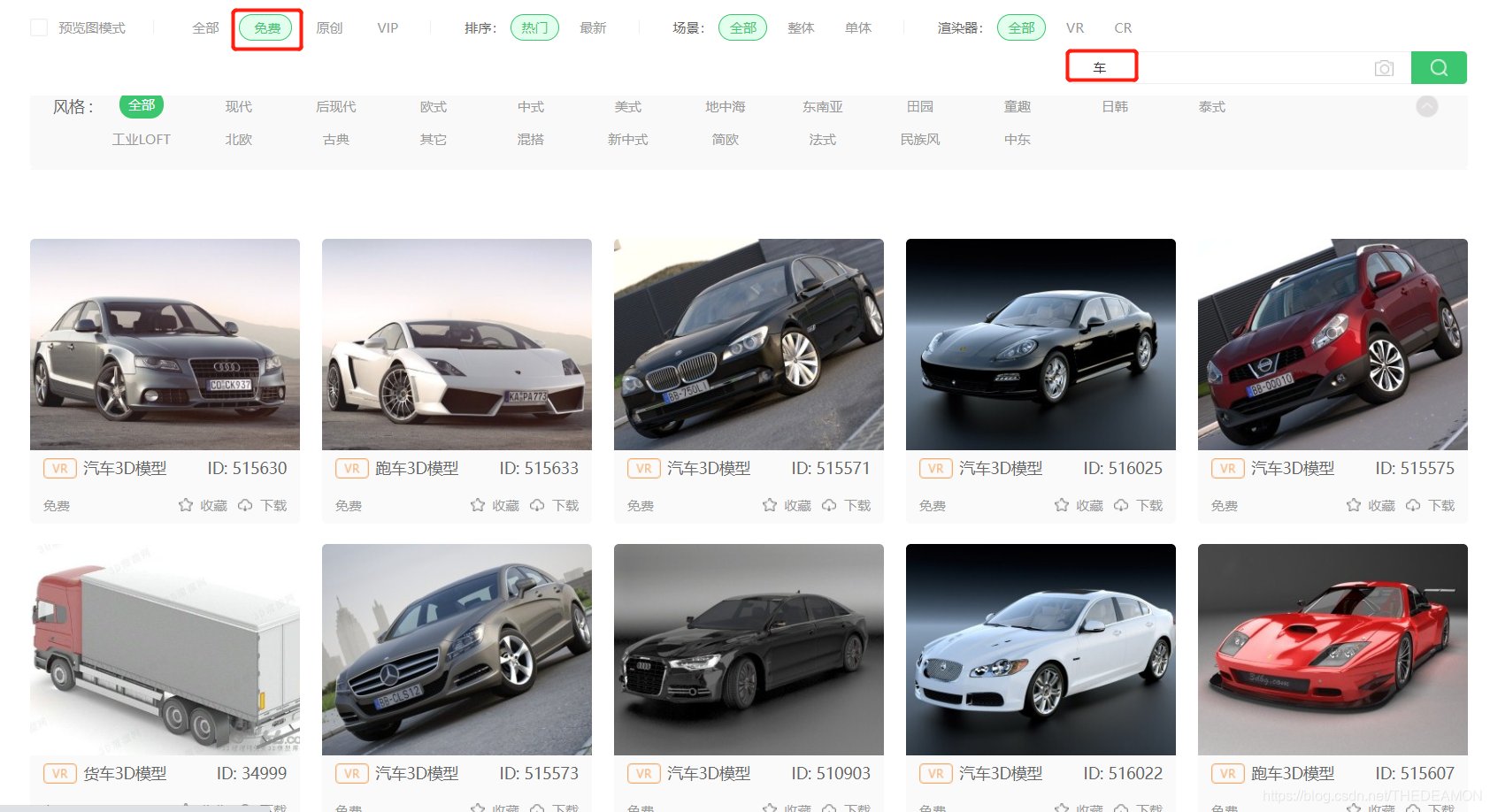
找到心仪的模型,点击进去后, 找到右侧的【立即下载】,然后选择【常规下载】
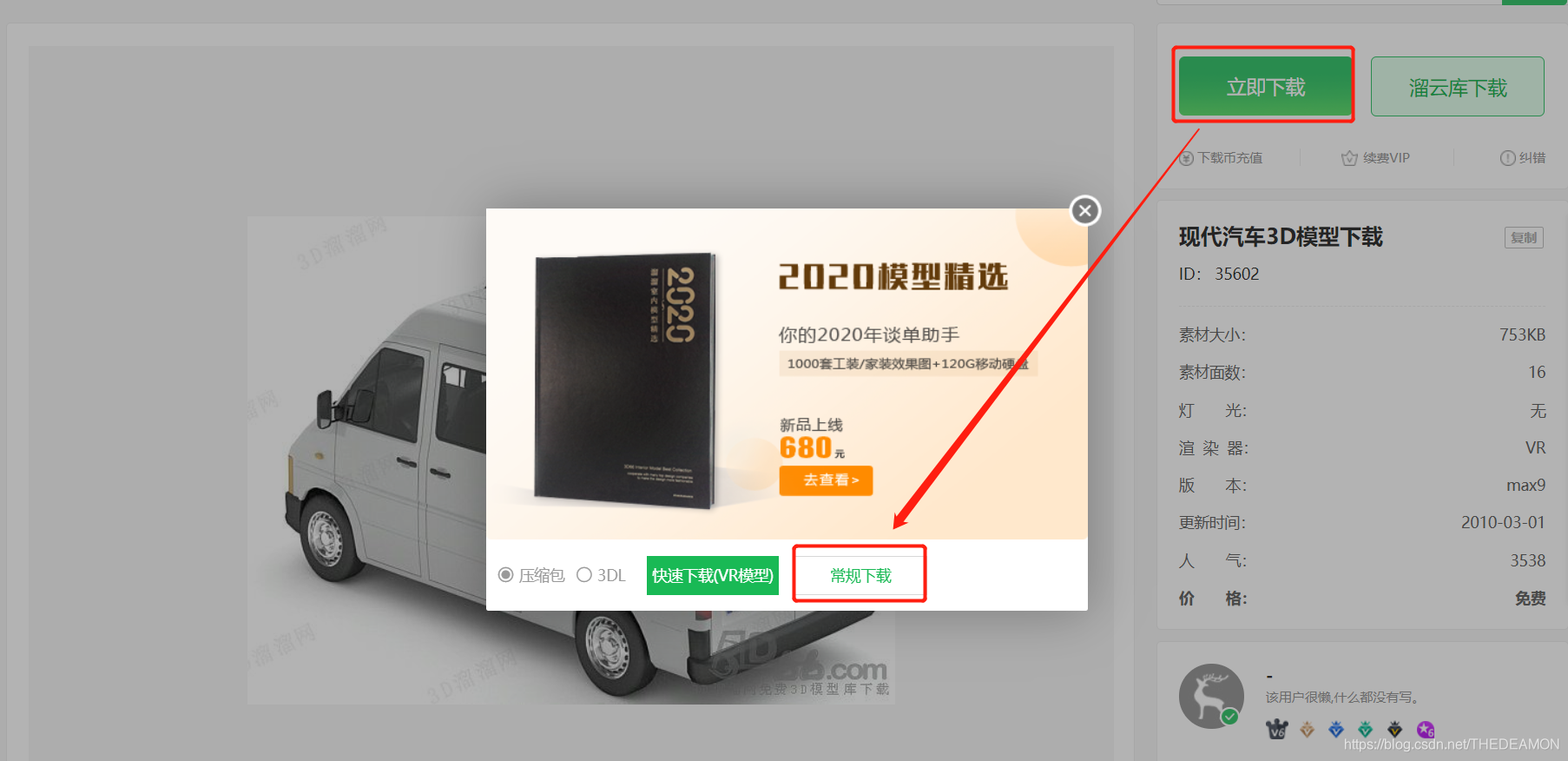
2.下载好后是一个max文件的压缩包,然后开始下一步
二、下载安装模型转换需要的插件
需要准备两个插件,一个是COLLADA插件,另一个是DAE转GLTF的工具
COLLADA插件下载地址:
链接:https://pan.baidu.com/s/1ihJX8bUVgCBu-kk5gxDqAA
提取码:8jwj
DAE转GLTF工具下载地址:
Converter Builds · KhronosGroup/glTF Wiki · GitHub
or
链接: https://pan.baidu.com/s/11bEVFKnxUVuEqRUAPJymPg
提取码:iri6
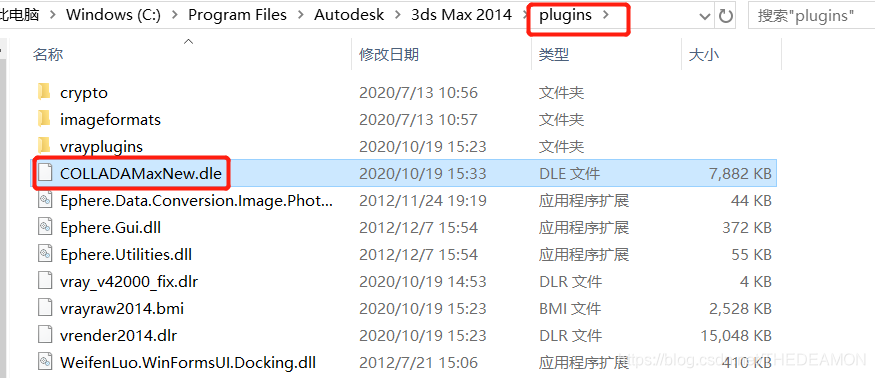
- 安装DAE导出插件,安装方法是把插件复制到max的安装目录的【plugins】文件夹内
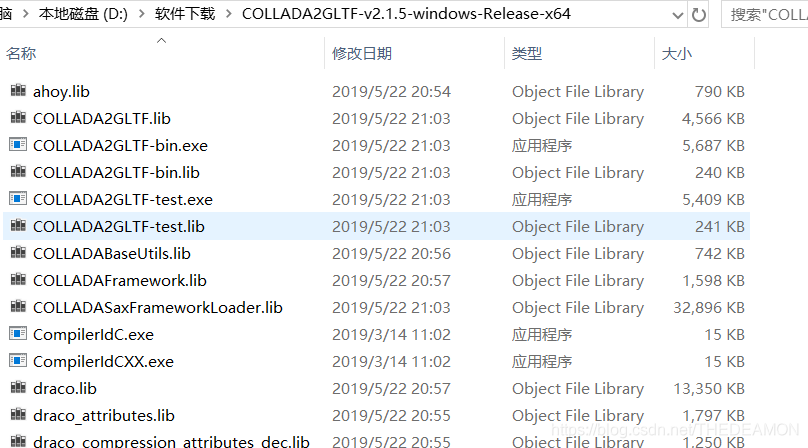
2.DAE转GLTF工具无需安装,解压即可
三、模型开始导出
备注:以车为例,模型正确的方向在max中看是车头朝【南】方,不然会出现车辆在移动过程中,车头方向不正确的问题

-
max打开刚才下载的数据,然后点击【导出】 ,格式选择【OpenCOLLADA(*.DAE)】
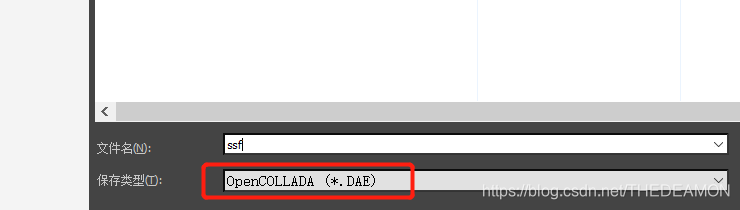
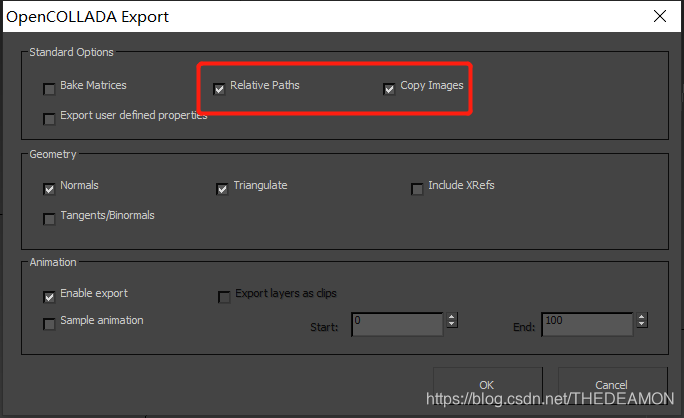
点击保存 ,在弹出的确认框中勾选上下面两项
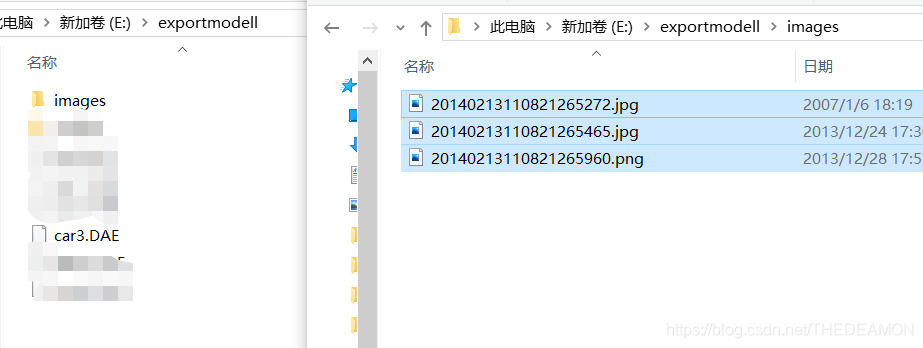
2.找到导出的DAE文件,再把max的贴图拷贝到【images】文件夹里
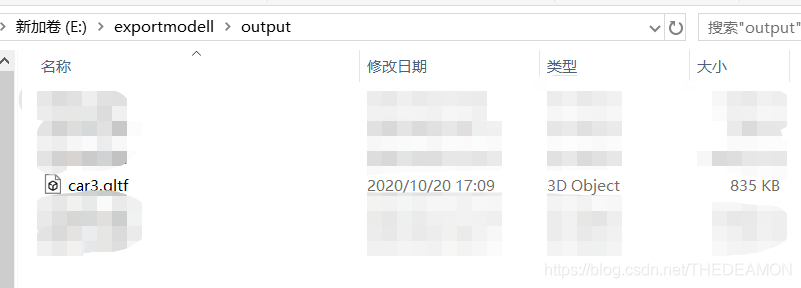
3.然后打开cmd,进入到DAE转GLTF的工具里,然后运行命令行【COLLADA2GLTF-bin.exe -f %datapath% -e】

其中,【datapath】是DAE文件的全路径,运行完成后,会在同一目录下生成【output】文件夹,里面存放我们需要的gltf文件
四、常见问题
1.gltf模型没有贴图
解决:①检查dae模型存放的路径是否含有中文,如果有修改成英文
②DAE文件用文本编辑器打开,找到images标签,确认贴图路径和名称是否正确,一般贴图名称前面会有前缀【数字_】,例如【0_20010302.jpg】修改为【20010302.jpg】后保存并重新转换
2.gltf模型有法线问题
解决:在max里修改后重新导出和转换
最后补一张在前端加载的效果图

这篇关于SuperMap webgl 中使用的gltf模型制作方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






