本文主要是介绍SuperMap三维专题之倾斜摄影——倾斜摄影数据介绍篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
倾斜摄影测量三维模型技术发展至今,属于一项成熟度很高的技术。很多人手里都有大大小小的一些倾斜摄影三维模型数据,但是数据怎么展示,怎么进行使用,怎么与业务进行结合一直是大家很头痛的事情。下面我会为大家介绍从数据拿到手到最后展示的一整套流程。
倾斜摄影三维数据目前有好几款自动化建模软件可以进行生产,使用度比较高的有CC(原Smart3D)、街景工厂、PhotoScan等,随之而来的也有很多格式的数据。目前市面上公开认可的倾斜摄影数据的标准格式为OSGB格式,我们也将基于这个格式进行介绍。
1.倾斜摄影数据的组织格式
以CC软件生产的OSGB格式为例,倾斜摄影数据是有很多个包含OSGB数据的文件夹,一个s3c后缀的文件以及一个metadata.xml的文件组成:

.2.倾斜摄影数据文件含义解析
- *.s3c文件:该文件为CC软件的工程文件,后面使用SuperMap软件无需使用,可忽略
- Data文件夹:存放倾斜摄影三维数据的文件夹,俗称根目录
- metadata.xml文件:存放倾斜摄影三维数据的坐标系和坐标值信息
3.metadata.xml文件详细解析
倾斜摄影数据在生产的时候就已经制定好数据的坐标系信息和中心点的坐标值等,这些信息都存放在这个xml文件中。
①第一种
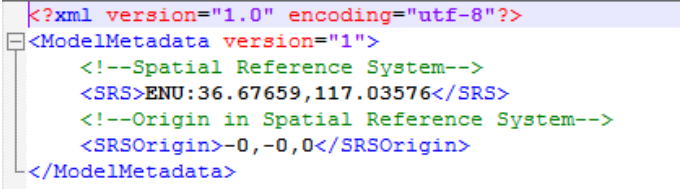
文件中ENU表示该倾斜摄影数据使用的是ENU坐标系,并且后面的坐标值表示倾斜摄影数据的插入点坐标,打开SuperMap iDesktop软件,找到三维数据→数据管理→生成配置文件

然后在对话框中填入xml的信息

备注:源数据路径选择到data文件夹,目标文件路径建议与源数据路径一致,目标文件名可以修改为有意义的名称
②第二种

文件中的EPSG:32649表示该倾斜摄影三维数据用的是编号为32649的EPSG坐标系,并且该数据的插入中心点坐标为(686169,2541593,0),SuperMap iDesktop中可以根据EPSG的编号新建坐标系,具体操作方法为:首先打开新建配置文件的对话框,填写好源数据路径和目标文件路径和路径名以及插入点坐标点后,勾选投影设置,在投影设置对话框中选择新建,根据EPSG编码新建(或者再搜索框里直接输入编码搜索即可)



4.加载数据
配置文件生成完成后我们就可以利用SuperMap iDesktop软件打开倾斜摄影三维数据进行数据浏览。具体操作方法为,在工作空间文件管理器的场景节点上右键,选择新建球面场景
 然后再场景选项卡中点击缓存按钮,再在文件选择窗口中选择刚才生成的配置文件(*.scp)即可
然后再场景选项卡中点击缓存按钮,再在文件选择窗口中选择刚才生成的配置文件(*.scp)即可
 打开后,在左边图层管理器中双击倾斜摄影图层即可以定位到数据位置
打开后,在左边图层管理器中双击倾斜摄影图层即可以定位到数据位置
 好了,到这里倾斜摄影第一课就完成啦,我们学会了怎么加载和浏览倾斜摄影数据,进步很大呢!
好了,到这里倾斜摄影第一课就完成啦,我们学会了怎么加载和浏览倾斜摄影数据,进步很大呢!
这篇关于SuperMap三维专题之倾斜摄影——倾斜摄影数据介绍篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




