本文主要是介绍一篇文章带你弄清数据库日志系统原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一:事务系统
1. 事务的工作模型
事务必须满足原子性,所封装的操作或者全做或者全不做。
事务管理系统需要做两件事,1) 让日志系统产生日志,2) 保证多个事务并发执行,满足ACID 特性。
事务系统工作模型,见图1 。
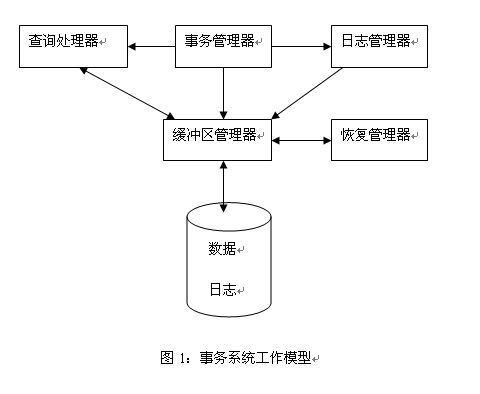
如图,事务管理管理器控制查询处理器的执行、控制日志系统以及缓冲区。日志在缓冲区生成,日志管理器在一定的时候控制缓冲区的刷盘操作。当系统崩溃的时候,恢复管理器就被激活,检查日志并在必要时利用日志恢复数据。
2. 事务的原语操作
在事务系统的运行当中,有三个地址空间供元素存储:1) 磁盘空间、2) 缓冲区、3) 事务的局部地址空间。
一个简单的读、修改X 元素操作的流程如:事务到缓冲中读取元素X ,如果命中,则读取事务局部地址空间并返回,如果未命中,则先将相关页从磁 盘读入缓冲区。事务在它的局部地址空间中修改元素X ,然后写入缓冲区,再从缓冲区写入磁盘。当然缓冲区的数据也可能不是立即拷贝入磁盘的,这取决于具体的 缓冲区管理策略。
为了便于描述,我们描述了五个操作原语:
1) INPUT(X) :将包含数据库元素X 的磁盘块拷贝到内存缓冲区
2) READ(X,t) :将数据库元素X 拷贝到事务的局部变量t 。更准确地说,如果包含数据库元素X 的块不在内存缓冲区中,则首先执行INPUT(X) 。接着将X 的值赋给局部变量t 。
3) WRITE(X,t) :将局部变量t 的值拷贝到内存缓冲区中的数据库元素X 。更准确地说,如果包含数据库元素X 的块不在内存缓冲区中,则首先执行INPUT(X) 。将着将t 的值拷贝到缓冲区中的X 。
4) OUTPUT(X) :将包含X 的缓冲区拷贝到回磁盘。
3. 应用
假设银行系统数据库中有两个元素,元素A( 表示用户1 的余额,值为1000 ,单位:RMB) 与元素B( 表示用户2 的余额,值为500 ,单位:RMB) 。这时候用户1 需要向用户2 转帐50 元。相应的过程为:
A := A – 50;
B := B + 50;
执行之前,两个用户的总余额为1500(1000+500) ,两个操作执行成功之后总余额还是1500(950+550) 。处于一致性状态。
如果只有前一条执行成功,那总额只为1450(950+50) 。处于不一致状态。
为了避免这种不一致状态,我们需要将这两个操作封装成一个事务T 。
我们将这两个操作分解为原语操作。如下:
READ(A,t); t := t-50; WRITE(A,t);
READ(B,t); t := t+50; WRITE(B,t);
OUTPUT(A); OUTPUT(B) // 这两个OUTPUT 原语操作由缓冲区管理器发出。
表1 给出了这8 个原语操作的执行步骤,给出了每一步中A 和B 的内存值、磁盘拷贝的值以及事务T 地址空间中局部变量t 的值
表1 : 一个事务的步骤及其对内存和磁盘的影响
| 步骤 | 动作 | t | 内存A | 内存B | 磁盘A | 磁盘B |
| 1 | READ (A,t ) | 1000 | 1000 |
| 1000 | 500 |
| 2 | t := t-50 | 950 | 1000 |
| 1000 | 500 |
| 3 | WRITE(A,t) | 950 | 950 |
| 1000 | 500 |
| 4 | READ (B,t ) | 500 | 950 | 500 | 1000 | 500 |
| 5 | t := t+50 | 550 | 950 | 500 | 1000 | 500 |
| 6 | WRITE(B,t) | 550 | 950 | 550 | 1000 | 500 |
| 7 | OUTPUT (A ) | 550 | 950 | 550 | 950 | 500 |
| 8 | OUTPUT (B ) | 550 | 950 | 550 | 950 | 550 |
在表1 中不难发现,只要所有的这些步骤都执行成功,数据库的一致性就能得到保持。如果在执行OUTPUT(A) 前系统发生了故障,那么磁盘 上存储的数据库不会受到任何影响,就好象事务T 从来没有发生过一样。但是如果故障在OUTPUT(A) 后而在OUTPUT(B) 前发生,那么数据就会处于 不一致状态( 从表中可以看出,磁盘中A 为950 ,B 为500) 。我们不能防止这种情况的发生,但可以安排当这些情况发生时对问题进行修复----- 或者A 为1000 、B 为为500 ,或者A 为950 ,B 为550 。
二:undo 日志
1. 概述
日志是日志记录的一个序列。在多事务的数据库系统中,每个事务有若干个操作步骤。每个日志记录记载有关某个事务已做的某些情况。几个事务的 行为可以是“ 交错的” ,因此可能是一个事务的某个步骤被执行,并且其效果被记录到日志中,接着执行另外一个事务的某个步骤并记入日志,接着可能接着做第一 事务的下一个步骤,也可能执行另外一个事务的某个步骤。依次类推。事务的交错执行使日志更复杂,因为仅在事务结束后记载事务的全过程是不够的。
如果系统崩溃,恢复管理器就被激活,检查日志以重建数据库的一致性状态。恢复时,有些事务的工作将会重做,它们写到数据库的新值会重写一次。而另外一些事务的工作将被撤消,数据库被恢复,将仿佛这些事务从来没执行过一样。
Undo 日志是日志类型的一种,这类日志仅仅进行第二类修复。对于要被撤消的事务,因为不能肯定它对数据库的修改是否已经写到磁盘中,所以对于该事务的所有更新都将被撤消,数据库恢复到事务发生以前的状态。
2. 日志记录
日志只允许以附加的方式写入数据。日志块最初在主存中创建,像数据块一样也由缓冲区管理,在确当的时刻,日志块会从缓冲区写入到磁盘。
关于undo 记录形式有四种:
1) : 这一记录表示事务T 开始
2) : 事务T 已经完成。
3) : 事务T 不能成功执行。
4) : 事务T 改变了数据库元素X 的值,元素X 原来的值为v 。
3.undo 日志规则
要想让undo 日志能使我们从系统故障中恢复,事务必须遵循两条规则。
规则1) 如果事务T 改变了数据库元素X ,那么形如的日志记录必须在X 的新值写到磁盘前写到磁盘
规则 2) 如果事务提交,则其COMMIT 日志记录必须在事务改变的所有数据库元素已写到磁盘后再写到磁盘,但应尽快。
简单概括,undo 日志系统顺序如下:
1) 指明所改变数据库元素的日志记录
2) 改变的数据库元素自身
3) COMMIT 日志记录。
4. 应用
对于前面所举的例子(A 转帐50 元给B 帐号) ,如果使用了undo 日志系统,则相关的工作流程如表2 如下。
表2 :undo 日志系统的工作原理
| 步骤 | 动作 | t | 内存A | 内存B | 磁盘A | 磁盘B | undo 日志 |
| 1 |
|
|
|
|
|
| <START T> |
| 2 | READ (A,t ) | 1000 | 1000 |
| 1000 | 500 |
|
| 3 | t := t-50 | 950 | 1000 |
| 1000 | 500 |
|
| 4 | WRITE(A,t) | 950 | 950 |
| 1000 | 500 | <T, A, 1000> |
| 5 | READ (B,t ) | 500 | 950 | 500 | 1000 | 500 |
|
| 6 | t := t+50 | 550 | 950 | 500 | 1000 | 500 |
|
| 7 | WRITE(B,t) | 550 | 950 | 550 | 1000 | 500 | <T, B, 500> |
| 8 | FLUSH LOG |
|
|
|
|
|
|
| 9 | OUTPUT (A ) | 550 | 950 | 550 | 950 | 500 |
|
| 10 | OUTPUT (B ) | 550 | 950 | 550 | 950 | 550 |
|
| 11 |
|
|
|
|
|
| <COMMIT T> |
| 12 | FLUSH LOG |
|
|
|
|
|
|
在表2 ,我们可以看到FLUSH LOG 这个命令。该命令的用于强制将还没有刷盘日志记录写到磁盘上。对于步骤8 执行之前,三个undo 记录(,,) 是存储在缓冲区中的( 这样描述是为将问题简单化) ,执行步骤8 之后,三条undo 记录便写入了磁盘日志文件。在步骤12 再次执行FLUSH LOG 命令时,只将未刷盘的日志记录写入磁盘。
步骤9 、10 ,在前面已经描述过,是将数据库元素的修改从缓冲区写入到磁盘文件,因为WRITE 操作仅仅是将修改反应到缓冲区中(这样描述也是为了将问题简单化) 。
关注步骤8 ,执行完步骤8 之后,将满足undo 的规则1( 如果事务T 改变了数据库元素X ,那么形如的日志记录必须在X 的新值写到磁盘前写到磁盘) 。在我们真正将数据库元素A 与B 的修改反应到磁盘前,我们已经将它们对应的与写入到磁盘日志文件。
关注步骤11 与步骤12 ,执行它们将满足undo 的规则2( 如果事务提交,则其COMMIT 日志记录必须在事务改变的所有数据库元素已写到磁盘后再写到磁盘,但应尽快) 。我们已经将数据库元素A 与B 的修改反应到磁盘上,接着可以写入来表示事务T 的成功执行,但是该日志记录还在缓冲区中,所以我们在步骤12 执行FLUSH LOG 进行日志刷盘。
5. 使用undo 日志进行数据库的恢复
现在假设系统故障发生了。有可能给定事务的某些数据库更新已经写到磁盘上,而同一事务的另外一些更新尚未到达磁盘。如果这样,事务的执行就不是原子的,数据库状态就可能不一致。这时候,我们就有必要使用日志将数据库恢复到一致的状态。
比如,在表2 中,如果故障发生在步骤9 之后、步骤10 之前。数据库的状态就是不一致的。
恢复管理的第一个任务就是将事务划分为已经提交事务和未提交事务。如果在日志中,根据undo 的规则2 ,
事务T所做的全部改变在此之前已经写到磁盘上,因此当故障发生时,该事务T不可能导致数据库的不一致状态。
然而,假设在日志中,只有记录,而没有与之相匹配的记录。那么就有可能在崩溃前,事务的某些修改已经反应到磁盘上,而另外一些修改可能未发生或者还在缓冲区中。这种情况下,T是一个未完成的事务,因为必须被撤消。也就是说,T所做的任何修改都必须恢复为原来的值。Undo的规则1使该想法可以成为可能,因为在修改数据刷盘之前,日志文件中已经保存了修改数据的原先值。对于,只需要将X的值恢复为v就行了(我们不必检查数据库中X现有值是否为v)。
日志中可能有一些未提交的事务,并且甚至可能有一些未提交的事务修改了X,所以恢复时采用从日志文件尾向前扫描。在扫描过程中记住所有有或记录的事务T。同时在随后的扫描中,如果它看见,则:
1) 如果T的COMMIT记录已被扫描到,则什么也不做。
2) 否则,将数据库中元素X的值改为v。在做完这些操作后,为以前未中止且未完成的每个事务T写入一个日志记录,然后刷新日志。
对于表2,作如下分析:
1)崩溃在第12步后发生。因为日志记录已经写入日志文件。当恢复时,不需要处理T事务。
2)崩溃发生在11步和12步之间。日志中记录了三条记录:、以及。当恢复管理进行向后扫描时,首先遇到记录,于是它将B在磁盘上的值存为500。接着它遇到记录,于是它将A在磁盘上的值存为1000。最后记录被写到日志中且日志被刷新。
3)崩溃发生在第8步和第11步之间。情况2一样。
4)崩溃发生在第8步之前。日志系统中只有一条记录:。记录被写到日志中且日志被刷新。(实际上,在实际系统中,可能其他的事务执行FLUSH LOG操作,而将事务T的日志记录写入磁盘中,如果是这样的话,日志中可能已经写入和,对于这种情况,执行情况2的恢复就行。实际上这些细节不影响undo的恢复效用,为了简单起见,忽视这些情况)。
6.静态检查点
正如我们所看到的那样,恢复时需要检查整个日志。当采用undo类型的日志时,一旦日志记录被写入日志文件,事务T的日志记录就可以忽视了。但是此时事务T却不能截断日志,因为事务是交替执行的,如果这时将日志截断,可能丢失活动着的事务的日志记录。
解决该问题的方法是周期性地对日志做检查点。步骤如下:
1)停止接受新的事务
2)等待所有当前的活动事务提交或终止,并且在日志文件中写COMMIT或ABORT记录。
3)将日志刷新到磁盘
4)写入日志记录,并再次刷新记录。
5)重新开始接受新事务。
当恢复事,扫描到日志时,就不需要继续扫描日志记录了。
例如:假设日志开始时是这样的:
|
<START T1> |
|
<T1, A, 5> |
|
<START T2> |
|
<T2, B, 10> |
这时候,我们做一个检查点。等待事务T1和事务T2都完成,才在日志文件中写记录。检查点做完后,可以接受新的事务,这里为事务T3,T3执行了一些操作,此时系统崩溃了。日志文件的内容如下:
|
<START T1> |
|
<T1, A, 5> |
|
<START T2> |
|
<T2, B, 10> |
|
<T2, C, 15> |
|
<T1, D, 20> |
|
<COMMIT T1> |
|
<COMMIT T2> |
|
<CKPT> |
|
<START T3> |
|
<T3, E, 25> |
|
<T3, F, 30> |
恢复时,从文件尾部开始扫描,因为T3是未完成事务,则将磁盘上F的值存为前值30、磁盘上E的值存为前值25。当扫描到日志记录时,我们知道没有必要检查以前的日志记录了,并且数据库状态的恢复已经完成。
7.非静态检查点
静态检查点的缺点在与,可能需要很长时间等待活跃事务的完成,在用户系统看来似乎是静止了。非静态检查克服了该缺点,在做检查点时允许新事务进入。步骤如下:
1) 写入日志记录.其中T1,……,Tk为活跃事务。
2) 等待T1,……,Tk每一个事务提交或终止,但允许其它事务开始。
3) 当T1,……,Tk都已完成时,写入日志记录并刷新日志。
当系统发生故障时,从日志尾部开始扫描日志。根据扫描过程中先遇到记录还是记录,有两种情况。
1) 如果先遇到记录。所有未完成的事务在记录后开始,只要扫描到。就不需要继续扫描了。前的记录是可以截断的。
2) 如果先遇到,那么崩溃发生在检查点过程中。未完成事务只可能是到达前遇到的那些,以及T1,……,Tk在崩溃前未完成的那些。因此只要继续扫描到未完成事务中最早的那个事务的开始就行了。
一个通常的规律是,一旦记录到了磁盘,我们就可以将上一个记录前的日志删除了。
例如:假设日志开始时是这样的:
|
<START T1> |
|
<T1, A, 5> |
|
<START T2> |
|
<T2, B, 10> |
现在我们决定做一非静态检查点。因为事务T1和T2是活动的,我们写入记录。在等待T1和T2完成时,事务T3开始了。
执行到崩溃时,日志记录可能如下(对应恢复的第一种情况):
|
<START T1> |
|
<T1, A, 5> |
|
<START T2> |
|
<T2, B, 10> |
|
<START CKPT(T1,T2)> |
|
<T2, C, 15> |
|
<START T3> |
|
<T1, D, 20> |
|
<COMMIT T1> |
|
<T3, E, 25> |
|
<COMMIT T2> |
|
<END CKPT> |
|
<T3, F, 30> |
对于这种情况,恢复时,从尾部开始检查日志。T3是未完成的事务,将磁盘上的F值恢复为值30。发现记录,知道所有未完成的事务从前一个START CKPT开始。继续扫描,将磁盘上E的值恢复为25。继续扫描,发现没有其它已开始但尚未提交的事务。恢复完成。
当然,崩溃时的日志记录可能是另外一种格式,如下:
|
<START T1> |
|
<T1, A, 5> |
|
<START T2> |
|
<T2, B, 10> |
|
<START CKPT(T1,T2)> |
|
<T2, C, 15> |
|
<START T3> |
|
<T1, D, 20> |
|
<COMMIT T1> |
|
<T3, E, 25> |
对于这种情况,崩溃发生在检查点过程中。向后扫描,确定T3然后又确定T2是未完成事务,并撤消它们所做的修改。当到达时,我们知道其它可能未完成的事务只有T1了,但是T1的记录已经发现。我们也发现了。所以我们只要继续扫描到记录,并在此过程中将磁盘B的值恢复成10。
三:redo记录
1.概述
Undo是恢复的一种策略,但是不是唯一的策略。
Undo日志的一个潜在的问题是:在所有修改数据没有写到磁盘前,不允许提交该事务。有时,让修改的数据页暂时缓冲在主存中,是可以节省磁盘IO的;只要在崩溃的时候有日志用来恢复。
2.redo日志的规则
Redo日志用新值表示数据元素的更新,而undo日志使用的是旧值。Redo日志的表示:事务T为数据库元素X写入新值v。
Redo日志系统的规则只有一条:
规则1:在修改磁盘上任何数据库元素X之前,要保证所有与X这一修改相关的日志记录,包括更新记录以及记录,都必须出现在磁盘上。
Redo日志顺序如下:
1) 指出被修改元素的日志记录
2) COMMIT日志记录
3) 改变的数据元素自身。
3.应用
对于前面所举的例子(A转帐50元给B帐号),如果使用了undo日志系统,则相关的工作流程如表3如下。
表3:redo日志系统的工作原理
|
步骤 |
动作 |
t |
内存A |
内存B |
磁盘A |
磁盘B |
undo日志 |
|
1 |
|
|
|
|
|
|
<START T> |
|
2 |
READ(A,t) |
1000 |
1000 |
|
1000 |
500 |
|
|
3 |
t := t-50 |
950 |
1000 |
|
1000 |
500 |
|
|
4 |
WRITE(A,t) |
950 |
950 |
|
1000 |
500 |
<T, A, 950> |
|
5 |
READ(B,t) |
500 |
950 |
500 |
1000 |
500 |
|
|
6 |
t := t+50 |
550 |
950 |
500 |
1000 |
500 |
|
|
7 |
WRITE(B,t) |
550 |
950 |
550 |
1000 |
500 |
<T, B, 550> |
|
8 |
|
|
|
|
|
|
<COMMIT T> |
|
9 |
FLUSH LOG |
|
|
|
|
|
|
|
10 |
OUTPUT(A) |
550 |
950 |
550 |
950 |
500 |
|
|
11 |
OUTPUT(B) |
550 |
950 |
550 |
950 |
550 |
|
与记录的是新值。只有所有相关的日志记录被刷盘(步骤9),才允许将A与B的新值写到磁盘。步骤10与11在日志刷盘之后立即将数据修改写到磁盘,而实际中为了提高IO命中率,刷盘的时间可能会晚些。
4.使用redo日志的恢复
对于redo日志,根据规则1,我们可以知道如果日志没有,则事务T的修改所做的所有的更新都没反映到磁盘上,就像事务T从来没有发生过一样。
如果发现记录记录,却不敢保证所有的数据库修改已经反映到磁盘上,这和undo日志是相反的。我们必须将事务T重做一次。
使用redo日志恢复,过程如下:
1) 确定提交事务
2) 从首部开始扫描日志,对遇到的每一记录:
(a):如果T是未提交的事务,则什么也不做。
(b):如果T是提交的任务,则为磁盘上数据库元素写入值v
3)对于每一个未完成的事务T,在日志中写入一个记录并刷新日志。
例如,对于表3
1) 如果故障发生在第9步以后,记录已被刷新到磁盘。恢复时,遇到记录,为磁盘上的A写入值950。遇到记录,为磁盘上的B写入值550。
2) 如果故障发生在第9步之前,如果已经到达磁盘,则恢复过程同情况1。如果未到达磁盘,T被做为未完成事务,磁盘上的A和B不作任何修改,最后将一条写入日志并刷盘。
这篇关于一篇文章带你弄清数据库日志系统原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





