本文主要是介绍近期活动盘点:Apache Flink社区Meetup北京站、基于大数据的中国城市技术社会治理探索...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

想知道近期有什么最新活动?大数点为你整理的近期活动信息在此:
Apache Flink社区Meetup北京站
2019年6月29日
6月29号,Apache Flink 社区 Meetup 北京站即将到来,此次 Meetup 一如既往地邀请了社区多位 Flink 技术专家现场分享。伴随着 Apache Flink 1.9 版本发布日期临近,大家对 Apache Flink 1.9 版本有哪些新特性都十分好奇。本次 Meetup 特邀 Apache Flink PMC 与阿里巴巴、快手、Airbnb 的技术专家为你解读新特性、分享 Flink 的应用与实践。
【活动时间】2019年6月29日 10:00-18:00
【活动地点】北京海淀花园北路52号,中国信息通信研究院黄楼2楼
【报名方式】扫描下方二维码

数据派读者报名审核优先通过,心动不如行动,赶快马上报名吧!
注:报名信息公司岗位一栏处填写“数据派”即可。
Apache Flink Meetup 北京站,抢先了解关于 Flink 的最新动态:
Apache Flink 1.9 版本有哪些新特性?
Flink Table API 机器学习生态的未来规划是什么?
Airbnb 与 快手的 Flink 应用有哪些经验分享?
Flink 1.9 版本与 Hive 兼容性如何?
Flink on Kubernetes 有哪些进展?
活动流程
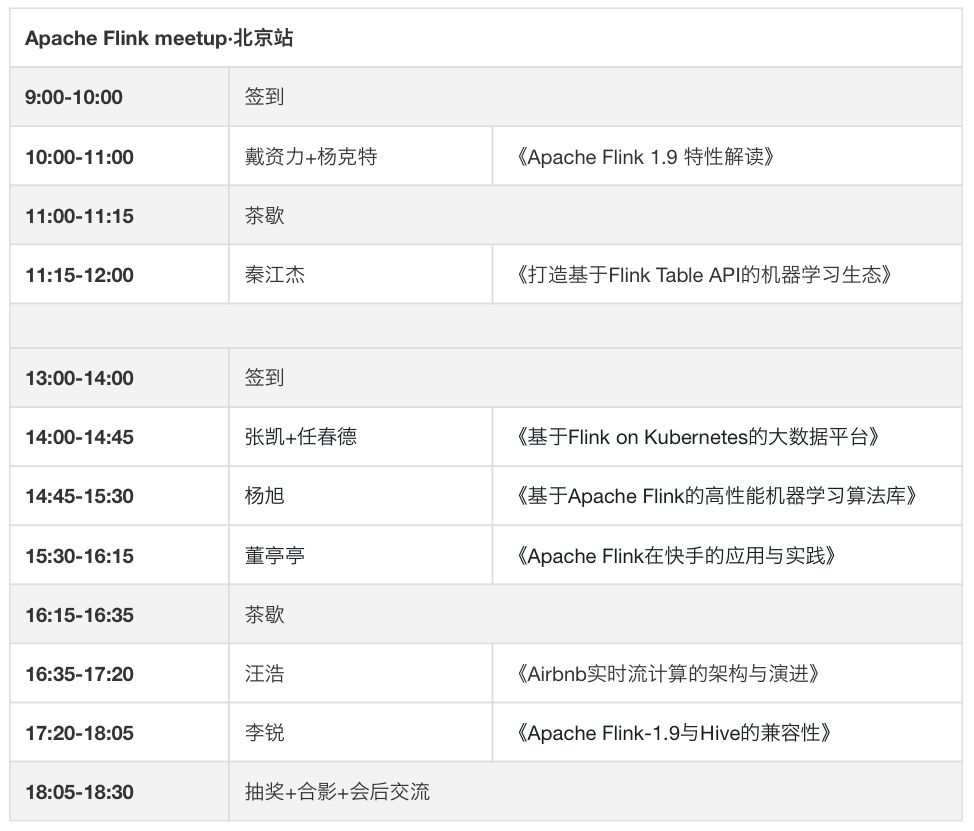
演讲主题及嘉宾介绍
《 Apache Flink 1.9 特性解读》

戴资力(Gordon Tai)
Apache Flink PMC ,Ververica Software Engineer
个人简介:戴资力(GordonTai)是 Apache Flink 开源社区的 PMC 成员,目前任职于 Ververica 担任 Software Engineer,主要负责 Flink 的系统开发。在 Flink 的主要贡献包含:Apache Kafka / AWS Kinesis 精确一次连接数据源,数据类序列化框架,有状态流处理的应用升级等。曾于 Flink Forward San Francisco / Berlin / Beijing 与 Strata Data 担任讲者分享 Flink 相关议题。

杨克特 (花名:鲁尼)
阿里巴巴高级技术专家,Apache Flink Committer
个人简介:2011 年硕士毕业于浙江大学后加入阿里巴巴,先后从事过搜索引擎,调度系统,大数据处理等核心系统的设计与研发,目前负责实时计算 Flink 的 SQL 引擎。
《打造基于 Flink Table API 的机器学习生态》

秦江杰
Apache Kafka PMC,阿里巴巴 高级技术专家
个人简介:阿里巴巴实时计算平台高级技术专家。硕士毕业于卡耐基梅陇大学,曾任职于 LinkedIn 负责 Apache Kafka 的开发,是 Apache Kafka PMC member。目前在阿里巴巴参与 Apache Flink 的开发工作。
《基于 Flink onKubernetes 的大数据平台》

张凯
阿里云 高级技术专家
个人简介:负责容器服务 Kubernetes 产品架构和研发,重点探索利用容器技术加速异构计算、深度学习、边缘计算等广泛场景方案的交付与落地。

任春德(花名:瓦力)
阿里巴巴 高级技术专家
个人简介:2006 年毕业加入阿里集团,长期从事 Hadoop 相关的大数据计算平台研发,目前在计算平台事业部担任高级技术专家,负责 YARN 和 Flink 资源调度的研发。通过 Flink 与 YARN 的深度对接,为实时计算提供大规模、高效、稳定的运行平台。
《基于 Apache Flink 的高性能机器学习算法库》

杨旭
阿里巴巴 资深算法专家
个人简介:杨旭是阿里巴巴集团计算平台事业部的资深算法专家,主要负责阿里云机器学习算法平台 PAI 中的基础机器学习算法的研发和维护,并基于 Flink 研发了批流一体的通用算法平台 Alink。Alink 已在阿里集团内部广泛使用,杨旭与其团队近期正在推进开源基于 Flink 的机器学习算法库,进一步回馈社区。
《Apache Flink 在快手的应用与实践》

董亭亭
快手 实时计算引擎团队负责人
个人简介:董亭亭,快手大数据架构实时计算引擎团队负责人。目前负责 Flink 引擎在快手内的研发、应用以及周边子系统建设。2013 年毕业于大连理工大学,曾就职于奇虎 360、58 集团。主要研究领域包括:分布式计算、调度系统、分布式存储等系统。
Airbnb 实时流计算的架构与演进

汪浩
Airbnb Data Platform Engineering Manager
个人简介:汪浩,南加州大学博士,现就职于 Airbnb, 现任 Data Platform Engineering Manager,带领流计算团队,为全公司提供实时流计算的基础设施。曾任职于 IBM Watson,负责搭建用于支持 Watson 产品的数据平台。主要领域为实时流计算,大数据分析系统,自然语言处理。
《Apache Flink - 1.9 与 Hive 的兼容性》

李锐
Apache Hive PMC,阿里巴巴技术专家
个人简介:阿里巴巴技术专家,Apache Hive PMC 成员,加入阿里巴巴之前曾就职于 Intel、IBM 等公司,主要参与 Hive、HDFS、Spark 等开源项目。
具体情况请点击:报名 | Apache Flink社区Meetup北京站:抢先了解关于Flink的最新动态
基于大数据的中国城市技术社会治理探索
2019年6月19日
本讲座选取北京、深圳、成都三个城市基于大数据手段的技术社会治理探索的四个街道(区)的典型案例,以社区社会资本、行政资源配置力度为划分标准,将这些街区的探索实践归纳为四种中国城市大数据技术社会治理模式。
【主题】基于大数据的中国城市技术社会治理探索
【讲师】何晓斌 清华大学社会科学学院副教授
【时间】2019年6月19日(周三)
下午3:30~6:00
【地点】清华大学近春园第二会议室
【主办单位】清华大学·野村综研中国研究中心、数据科学研究院
【报名方式】扫描下方二维码进行报名。本讲座名额有限需提前报名,收到报名成功短信后方可参加。

*讲座现场采用中日文交传的方式
【讲师介绍】

何晓斌,清华大学社会科学学院社会学系副教授,县域治理研究中心主任,社会与金融研究中心副主任,清华大学中国经济社会数据研究中心研究员。
研究兴趣包括经济和组织社会学,城市社会学,创新与创业等。他目前已经在中英文期刊上发表论文30多篇,英文专著一本。他的论文发表于《Social Science Research》,《Computers in Human Behavior》,《Development and Change》,《经济研究》,《管理世界》等国内外优秀期刊上。他还主持或参与国家及省部级课题10余项。
目前的研究课题涉及中国新创企业的政治策略,中国城市居民的主观幸福感,组织的社会资本和组织绩效,领导力和创新等。
具体情况请点击:报名 | 基于大数据的中国城市技术社会治理探索


这篇关于近期活动盘点:Apache Flink社区Meetup北京站、基于大数据的中国城市技术社会治理探索...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





