本文主要是介绍Transformer的前世今生 day09(Transformer的框架概述),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情提要
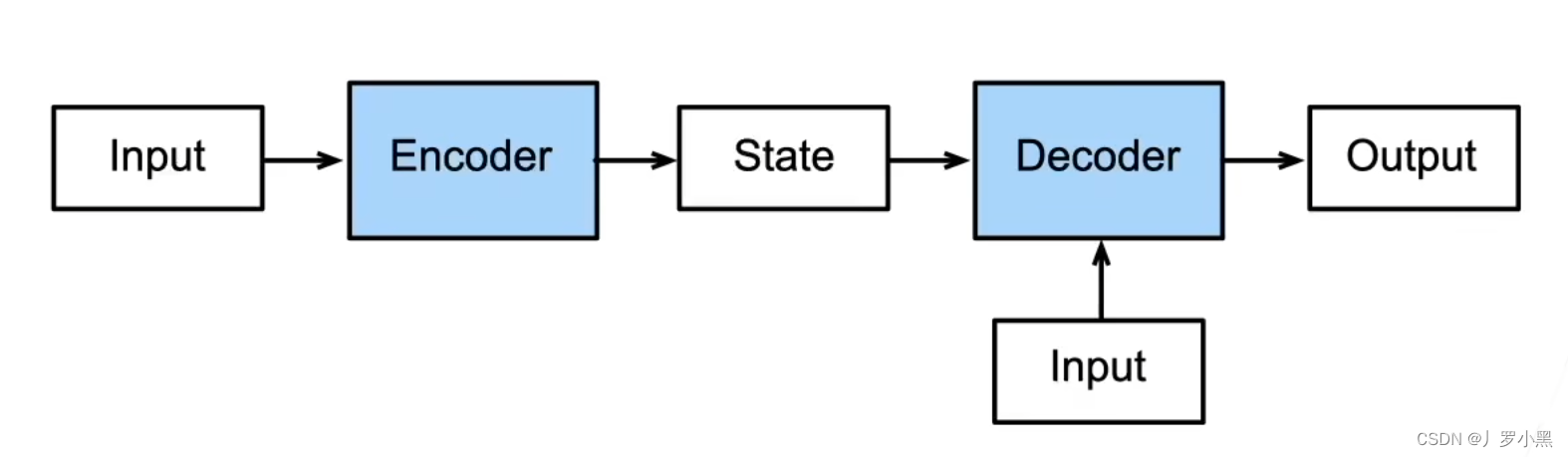
编码器-解码器结构
- 如果将一个模型分为两块:编码器和解码器
- 那么编码器-解码器结构为:编码器负责处理输入,解码器负责生成输出
- 流程:我们先将输入送入编码器层,得到一个中间状态state,并送入解码器层,和额外的输入一同处理后,得到模型的输出
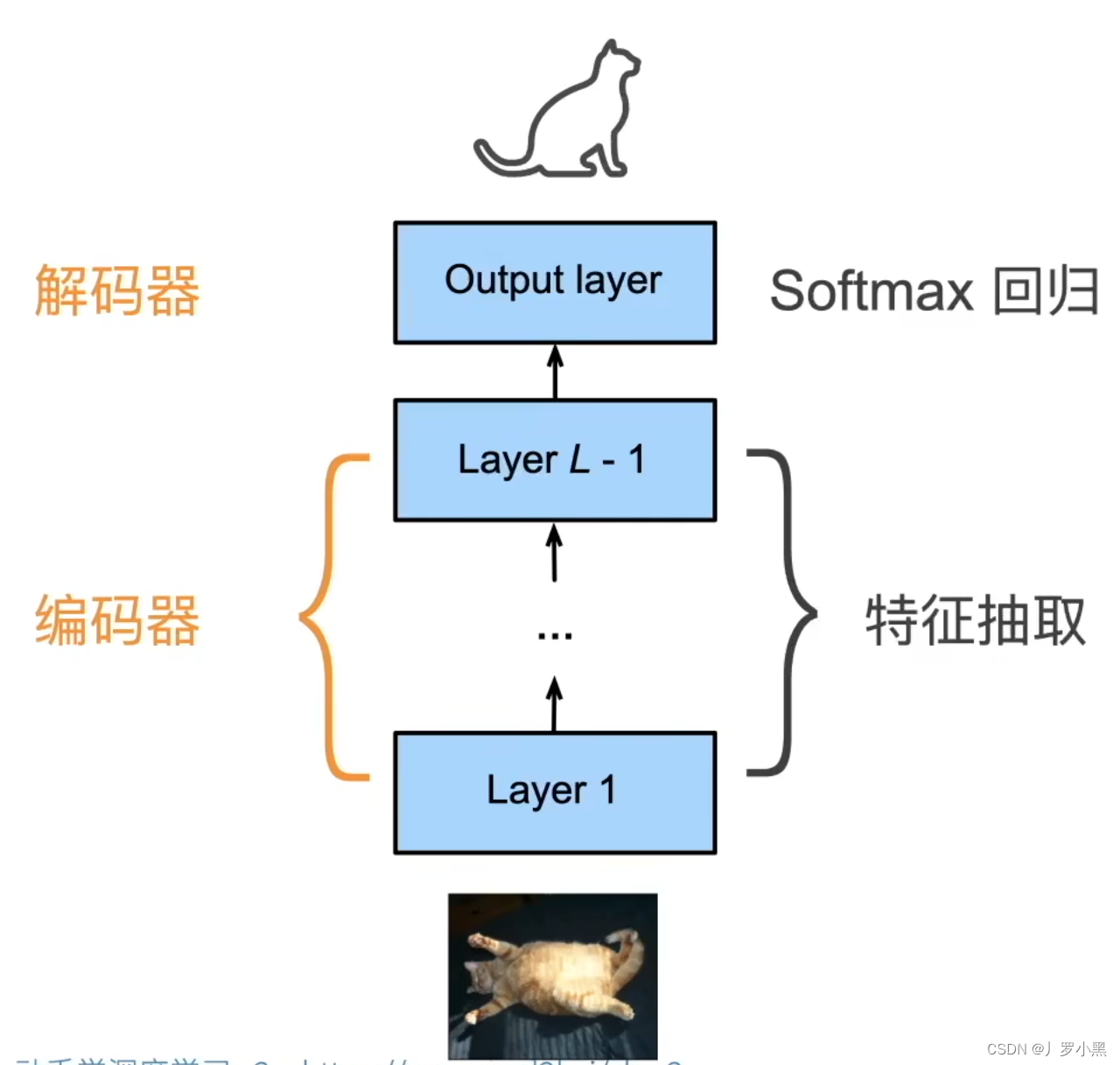
- CNN就可以重新表示为下图
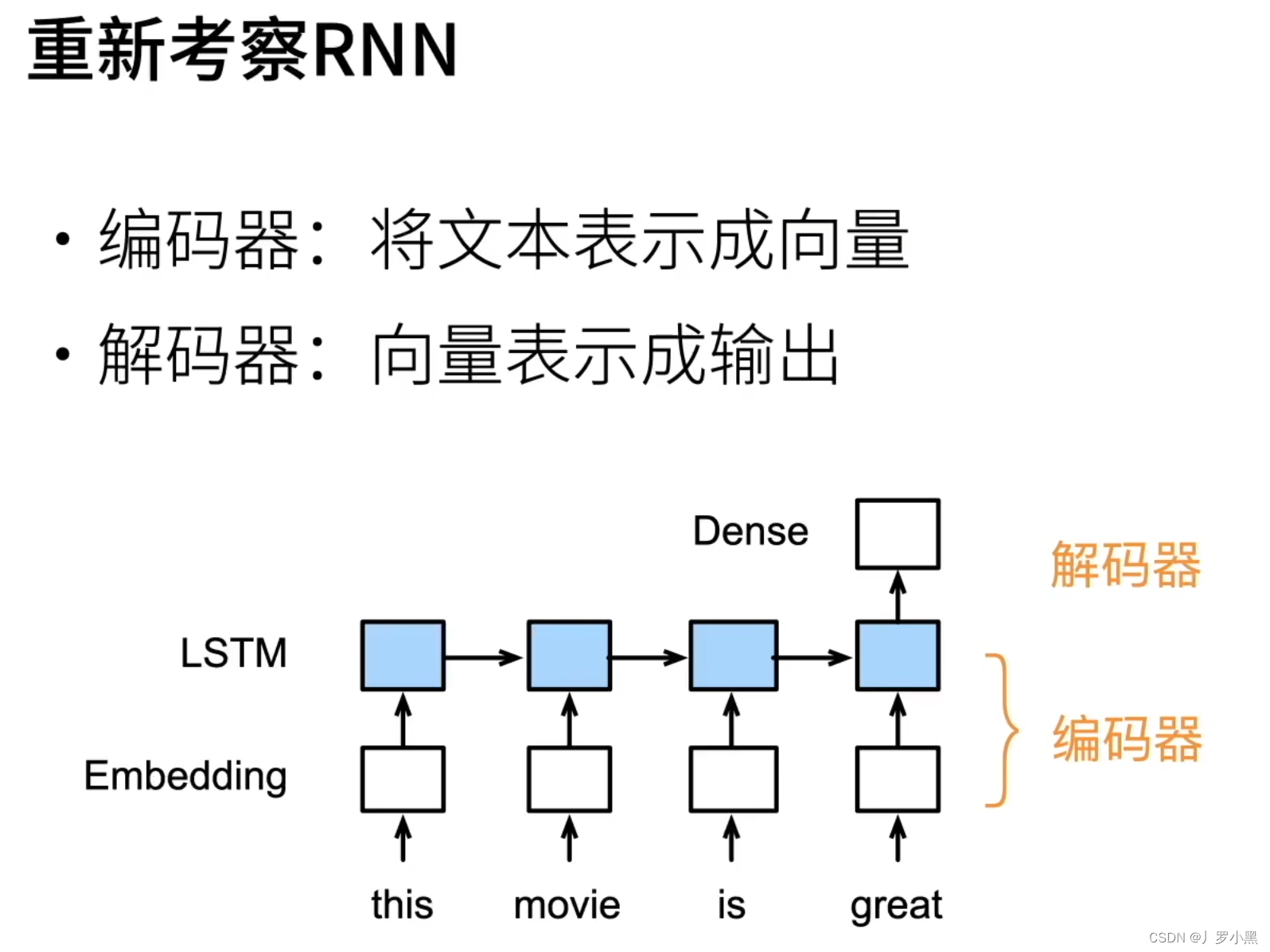
- RNN也可以表示为下图:
Seq2seq
- 序列到序列的模型:从一个句子生成到另一个句子
- 模型分为编码器、解码器两部分,其中,编码器可以是一个RNN,用来读取输入句子,解码器使用另外一个RNN来输出生成的句子
- 注意:由于在输入时,我们知道全部的输入句子,所以可以用两个RNN做双向,但是解码器是生成模型,不能看到完整的句子,所以不能做双向
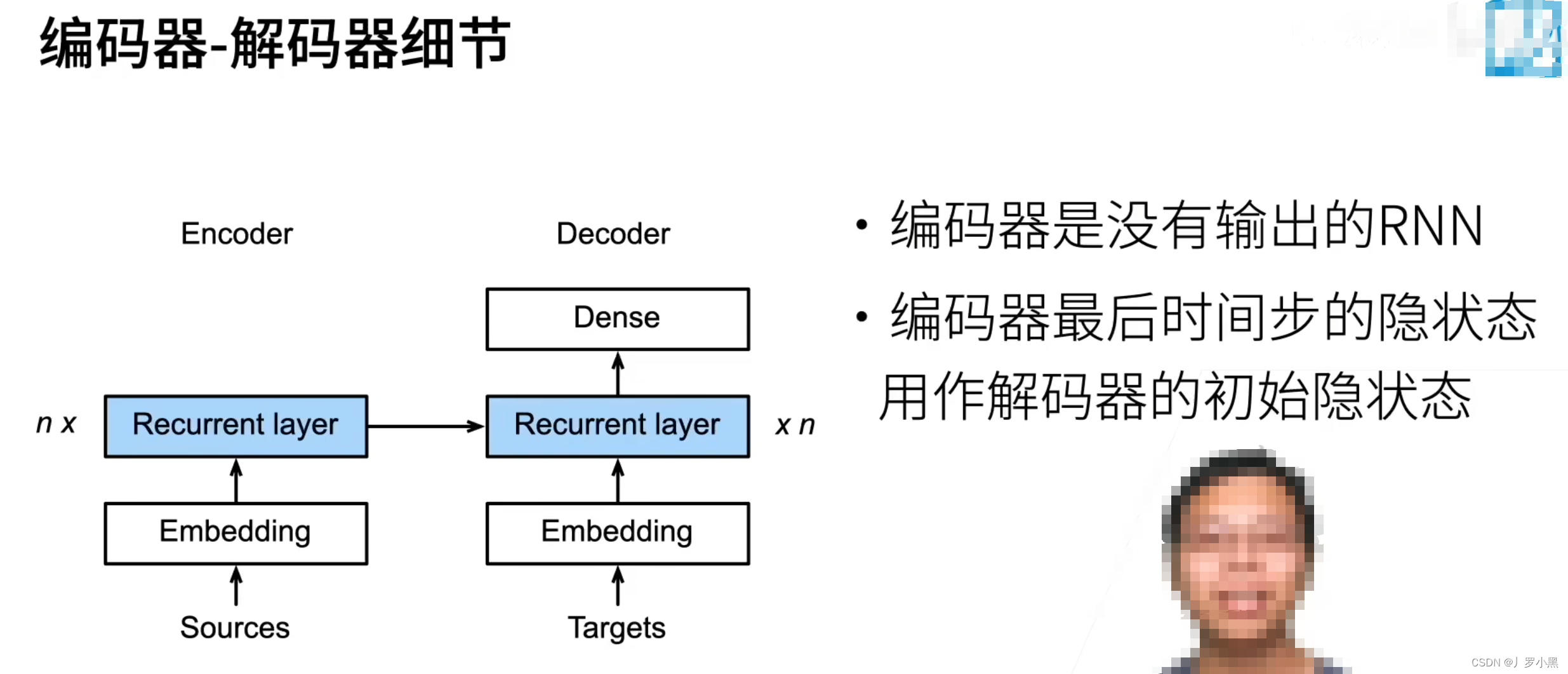
- 注意:在编码器层,通过开始<bos>、结束<eos>来控制编码器的输出
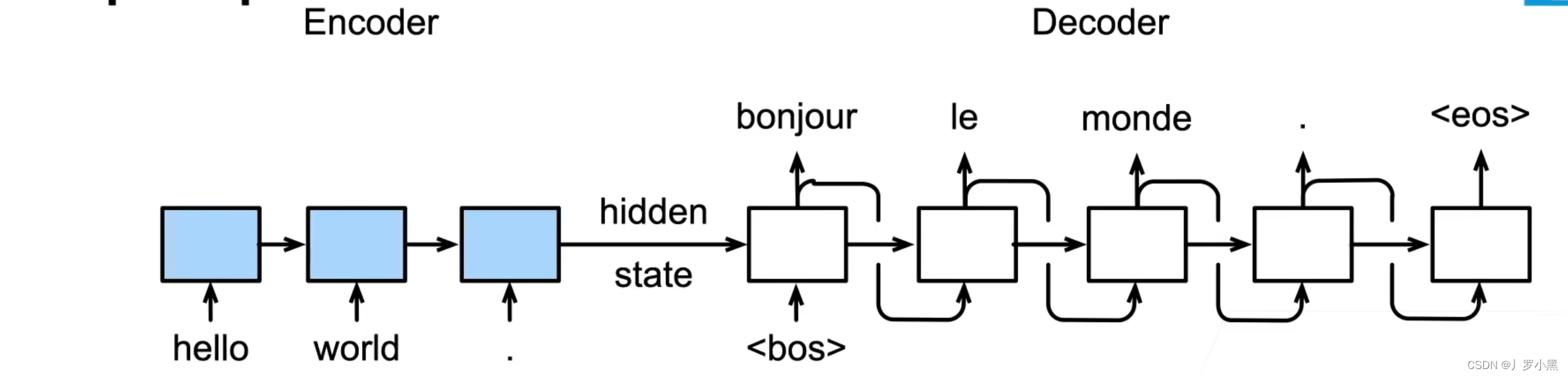
- 编码器层的输出是不会作为模型的输出,相反它最后一层的输出作为编码器层输入的一部分,和编码器层额外的输入合并,整体作为编码器层的输入,即编码器层的最后隐藏状态,作为解码器的初始隐藏状态,如下:
Transformer的框架概述
- NLP中预训练的目的:为了生成词向量
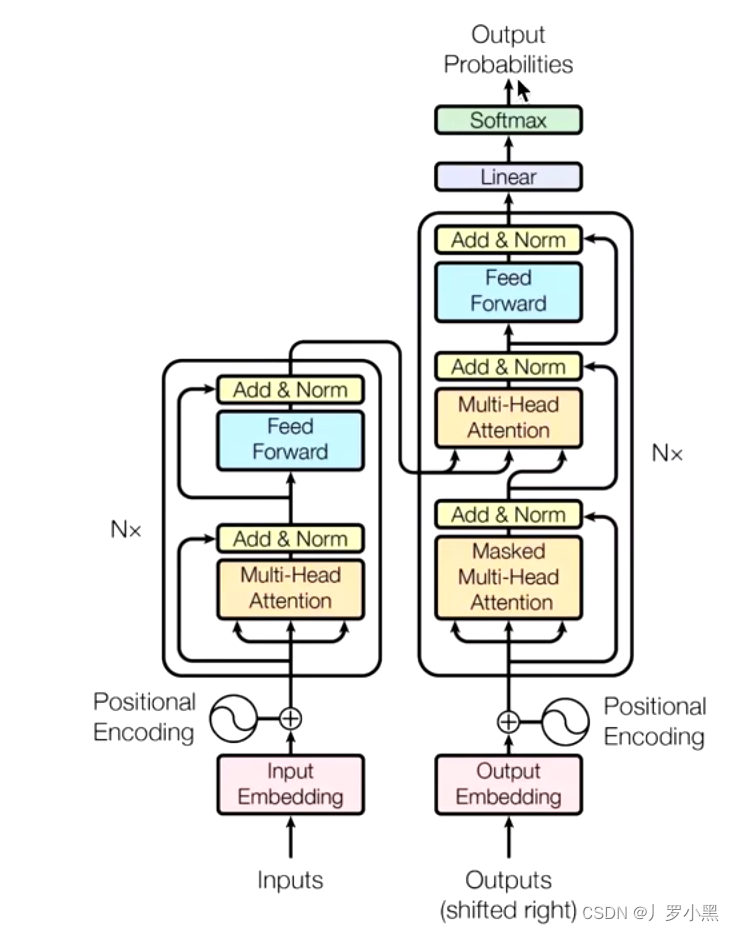
- Transformer采用了seq2seq(序列到序列)的模型,整体框架如下:
- seq2seq的模型基本都分为编码器层和解码器层,即从编码器到解码器的结构
- seq2seq的模型基本都分为编码器层和解码器层,即从编码器到解码器的结构
使用机器翻译的场景来解释
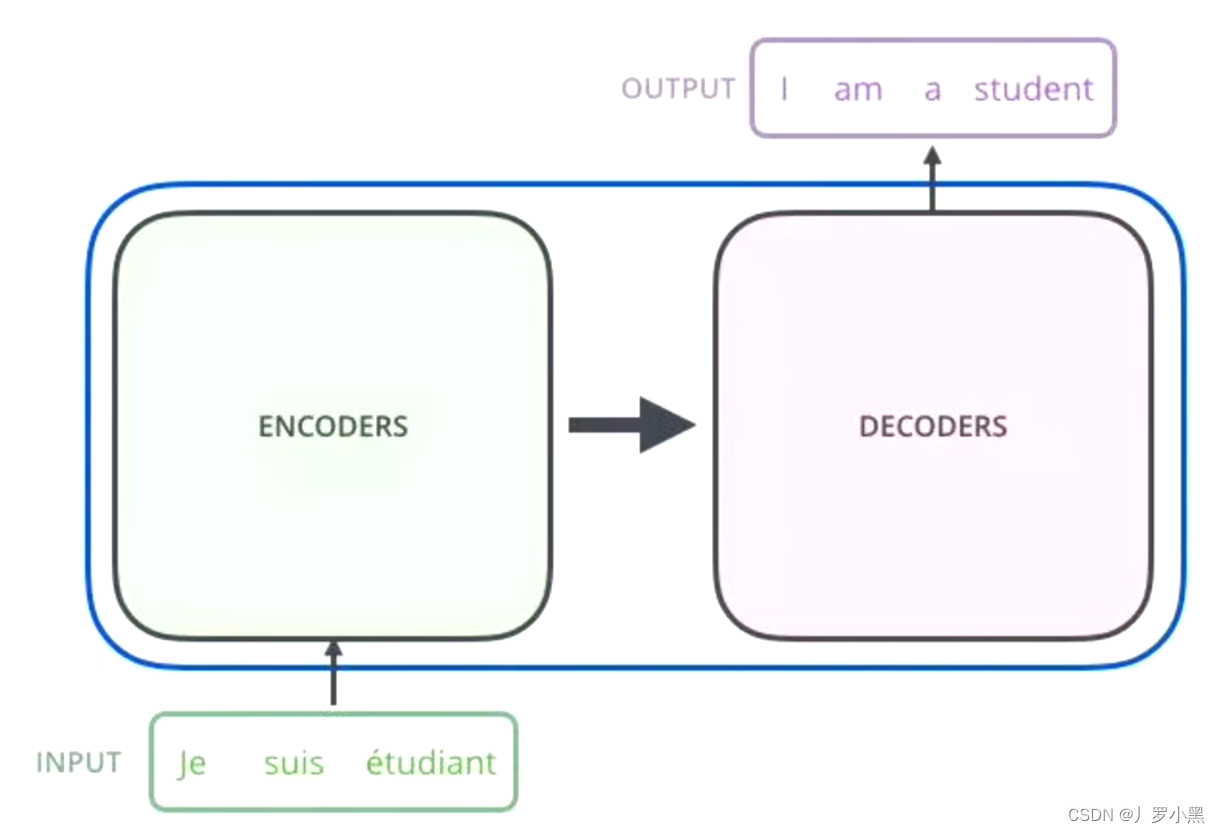
- 在机器翻译的场景中:
- 编码器层:把输入变成一个词向量
- 解码器层:得到编码器层输出的词向量后,生成翻译的结果
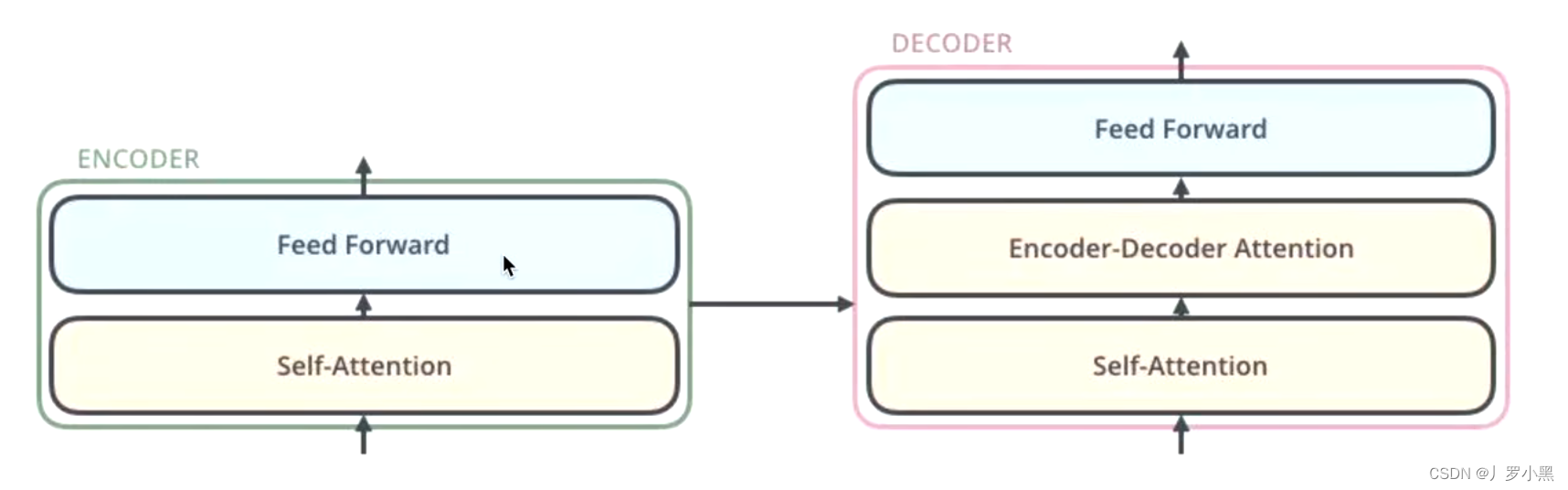
- 同时,N * 的意思是:编码器层里面又有N个小编码器(默认N=6),一个编码器可以看作Self-Attention,而Self-Attention会对词向量做增强,经过6个编码器,那就是增强了6次
- 编码器层最后的输出会分别给6个解码器
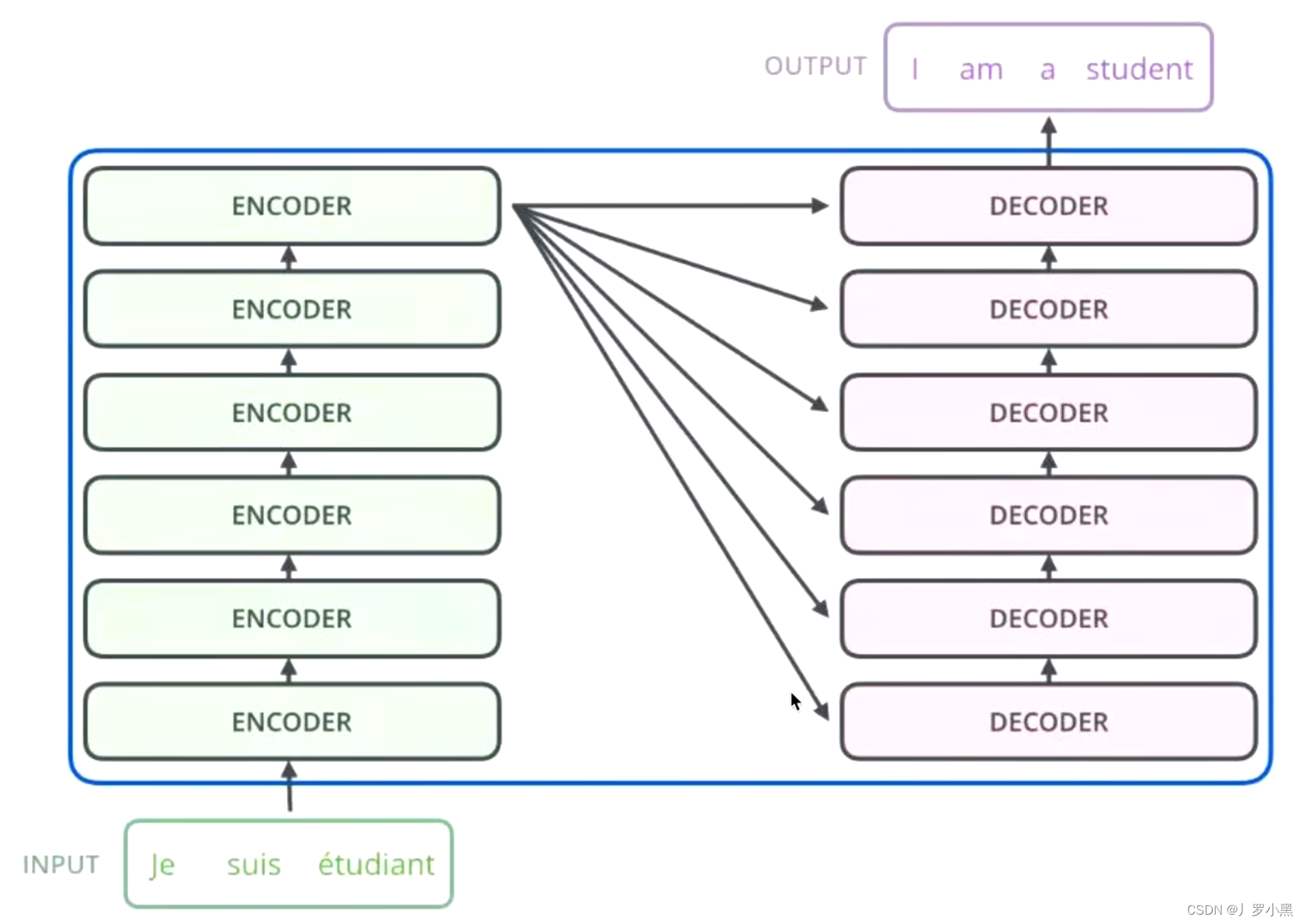
- 因此,Transformer的关键就在于编码器和解码器,如下:
这篇关于Transformer的前世今生 day09(Transformer的框架概述)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







