本文主要是介绍CNN和Transformer再组合!UniFormer:新的主干网络!在六大视觉任务上大放光彩!...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者丨happy 转载自丨极市平台
导读
CNN与Transformer相互借鉴是必然趋势,但如何借鉴并扬长避短仍需进一步深入挖掘。本文的UniFormer提供了一个非常不错的思路,它将卷积与自注意力以transformer方式进行了统一构建UniFormer模块,并由此构建了UniFormer。最后,作者在不同视觉任务(包含图像分类、视频分类、目标检测、实例分割、语义分割、姿态估计)上验证了UniFormer的超优异特性,真可谓“一力降十会”。

论文链接:https://arxiv.org/abs/2201.09450
代码链接:https://github.com/Sense-X/UniFormer
Abstract
图像/视频数据中的局部冗余与复杂全局依赖关系使得从中学习具有判别能力的特征表达极具挑战性。CNN与ViTs(Vision Transformers)是两种主流的架构,CNN通过卷积有效的降低了局部冗余但有限的感受野使其无法捕获全局依赖关系,而ViT凭借自注意力可以捕获长距离依赖,但盲相似性比对会导致过高的冗余。
为解决上述问题,我们提出一种新的UniFormer(Unified transFormer),它能够将卷积与自注意力的优点通过transformer进行无缝集成。不同于经典的Transformer模块,UniFormer模块的相关性聚合在浅层与深层分别武装了局部全局token,解决了高效表达学习的冗余与依赖问题。
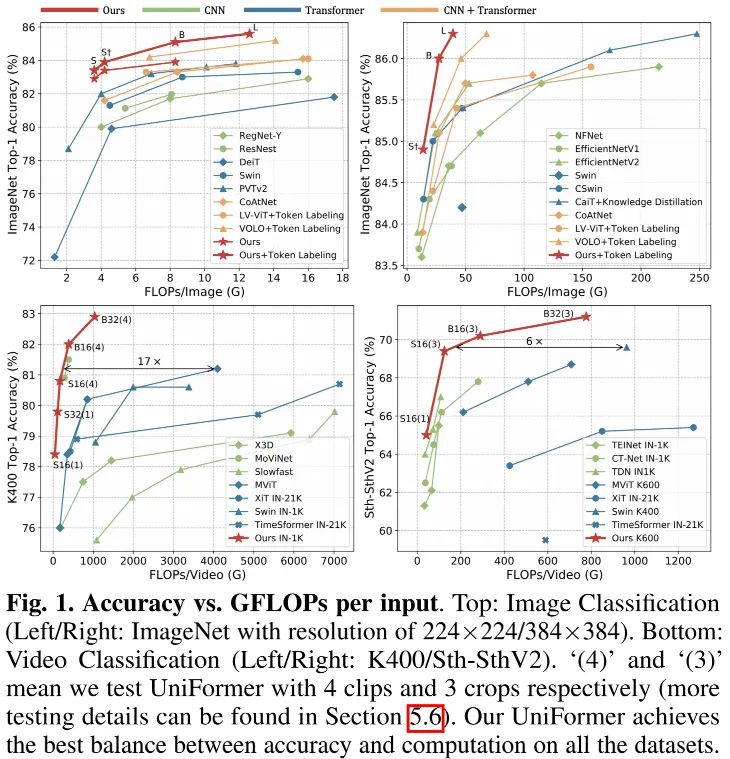
基于UniFormer模块,我们构建了一种新强力骨干并用于不同的视觉任务,包含图像与视频,分类与稠密预测。无需额外你训练数据,UniFormer在ImageNet数据及上取得了86.3%的精度;仅需ImageNet-1K预训练,它在诸多下游任务上取得了SOTA性能,比如Kinetics-400/600数据集上的82.9%/84.8%、Something-Something V1/V2数据集上的60.9%/71.2%、COCO检测任务上的53.8boxAP与46.4MaskAP、ADE20K分割任务上的50.8mIoU、COCO姿态估计上的77.4AP。
Method
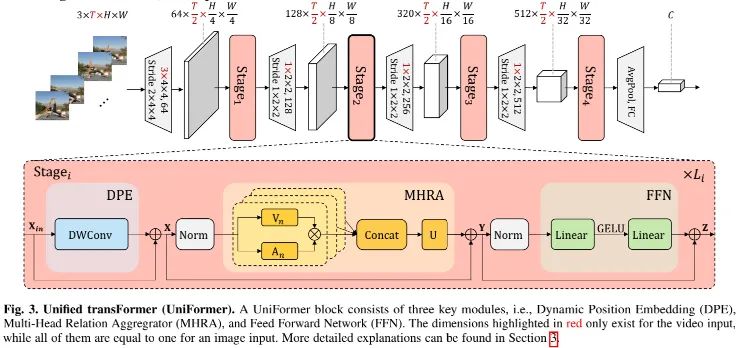
上图给出了本文所提UniFormer架构示意图,为简单起见,我们以T帧的视频输入作为示例。注:图中标红的维度仅作用于视频输入,其他维度对于图像和视频输入相同。
具体来说,UniFormer模块包含三个关键模块:
Dynamic Position Embedding,DPE
Multi-Head Relation Aggregator,MHRA
Feed-Forward Network,FFN
对于输入,我们首先引入DPE将位置信息动态集成进所有tokens,它适用于任意输入分辨率,可充分利用token顺序进行更好视觉识别,可描述如下:
然后,我们采用MHRA通过探索上下文token与相关性学习对每个token进行增强,描述如下:
最后,类似ViTs,我们添加FFN进一步增强token,可描述如下:
Multi-head Relation Attention
正如前面所提到:CNN与ViTs分别聚焦于解决局部冗余与全局依赖,导致了次优性能、不必要的计算冗余。为解决上述问题,我们引入了一种广义相关性聚合(Relation Aggregator, RA),它将卷积与自注意力统一为token相关学习。通过在浅层与深层设计局部与全局token affinity,它能够取得更高效&有效的表达学习能力。具体来说,MHRA以多头方式探索token相关性:
对于输入,我们首先将其reshape为token序列。表示RA的第n个头,表示可学习参数矩阵用于N个头聚合。每个RA包含token上下文编码与token亲和学习。我们通过线性变换将原始token编码为上下文token,然后RA可以通过token相关性矩阵An对token进行上下文信息聚合。
Local MHRA

如上图所示,尽管已有ViTs在所有token之间比较相似性,但他们最终学习了局部表达。这种自注意力冗余设计带来巨大的计算消耗。除了该发现外,我们建议在近邻之间学习token相关性,这与卷积滤波器的设计相似。因此,我们在浅层设计了局部相关性参数矩阵。具体来说,给定输入token ,局部RA在小范围内进行token间相关性计算:
由于浅层的视觉内容近邻变化很小,所以没有必要让上述相关性矩阵存在数据依赖性。因此,我们采用可学习参数矩阵描述上述局部token相关性,它仅依赖于相对位置信息。
Global MHRA
在深层,长距离相关性探索非常重要,它具有与自注意力相似的思想。因此,我们从全局视角设计了token相关性矩阵:
Dynamic Position Embedding
位置信息对于描述视觉表达非常重要。已有ViTs通过绝对/相对位置嵌入方式进行编码,但均存在一定的不灵活性。为改善灵活性,我们采用了如下动态位置嵌入:
其中DWConv表示zero-padding深度卷积。该设计主要基于以下三点考量:
深度卷积对于任意输入分辨率友好;
深度卷积极为轻量,是计算量-均衡均衡的重要因子;
zero-padding有助于token具有绝对位置感知性。
Framework

接下来,我们将针对不同下游任务进行架构设计,包含图像分类、视频分类、目标检测、语义分割、人体姿态估计等。相关架构示意图可参见上图。
Image Classification
前面的Figure3给出了用于图像/视频分类的架构示意图,它包含四个阶段。具体来说,我们在前两个阶段采用局部UniFormer模块以降低计算冗余;在后两个阶段采用全局UniFormer模块以学习长距离token依赖。
对于局部UniFormer模块,MHRA配置为PWConv-DWConv-PWConv(其中DWConv的尺寸为);对于全局UniFormer模块,MHRA配置为多头自注意力。对于两种UniFormer,DPE均为DWConv,尺寸为;FFN的扩展比例为4。
此外,我们对卷积使用BN,对自注意力使用LN。对于特征下采样,我们在第一阶段使用尺寸和stride均为的卷积;对于其他卷积则采用尺寸和stride为的卷积。除此之外,下采样卷积后接LN。最后,采用GAP与全连接层进行分类。为满足不同计算需求,我们设计了三种复杂度的模型,见下表。

Video Classification
基于前述图像分类的2D骨干,我们可以轻易的将其扩展为用于视频分类的3D骨干。不失一般性,我们调整Small与Base进行空时建模。具体来说,模型架构仍保持四个阶段不变。不同之处在于:所有2D卷积替换为3D卷积。DPE与局部MHRA中的DWConv滤波器尺寸为。特别的,我们在第一阶段之前需要进行空时维度下采样,此时的卷积滤波器与stride分别为。对于其他阶段,我们仅仅进行空间维度下采样,因此其他阶段的下采样卷积滤波器维度为。
在全局UniFormer模块中,我们从3D视角采用空时注意力学习token相关性。而已有Video Transformer则进行空域与时序拆分以降低计算量、缓解过拟合,这无疑会弱化空时相关性。此外,由于所提局部UniFormer模块可以极大节省计算量,故所提所提UniFormer可以更高效且有效的进行视频表达学习。
Dense Prediction
稠密预测任务有助于验证所提识别骨干架构的泛化性。因此,我们将UniFormer骨干使用多个主流稠密任务,包含目标检测、实例分割、语义分割以及人体姿态估计。
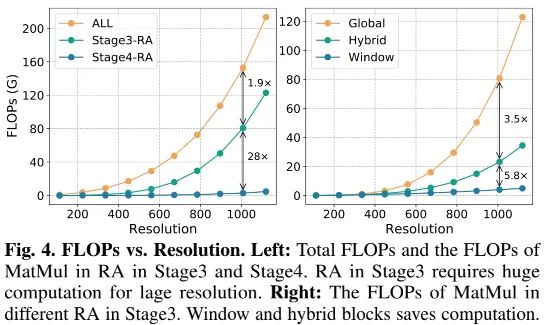
由于大多稠密预测的输入分辨率比较高(比如COCO检测上的),直接使用该骨干会导致具体计算量。为此,我们对不同下游任务调整全局UniFormer模块。上图给出了分辨率与计算量之间的关系,很明显:阶段3的RA占据了大量的计算量,甚至高达50%,而阶段4的结算量仅为阶段3的1/28。因此,我们主要聚焦于修改阶段3的RA。
受启发于Swin Transformer,我们在预定于窗口(而非全局图像范围)内执行全局MHRA。这种处理方式可以大幅降低计算量,但它不可避免会降低模型性能。为弥补该差距,我们在阶段即同时集成窗口形式与全局形式UniFormer,每个混合组包含三个窗口模块与1个全局模块。
基于上述设计,我们将引入用于不同稠密任务的定制骨干:
目标检测与实例分割:在阶段3采用混合模块;
姿态估计:由于输入较小,仍采用全局模块;
语义分割:由于测试时分辨率更大,故训练时采用全局模块,测试时采用混合模块。这种设计可以保持训练效率,同时可以提升测试性能。
Experiments
关于训练细节方面信息,我们就直接略过,直接上结果咯。
Image Classification
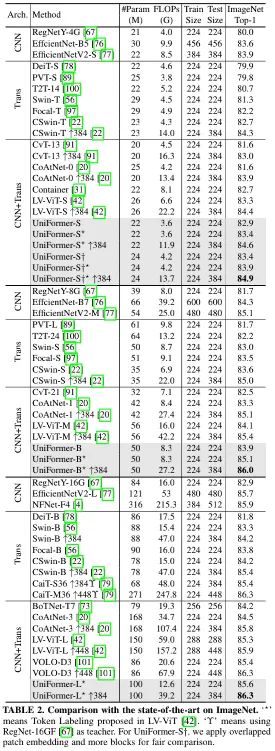
上表给出了ImageNet数据上的性能对比,从中可以看到:
在不同计算约束下,所提UniFormer均超越了其他CNN与ViTs;
UniFormer-S取得了83.4%的精度且仅需4.2G FLOPs,分别以3.4%、2.1%、0.7%、1.8%超越了RegNetY-4G、Swin-T、CSwin-T以及CoAtNet;
引入了Token Labeling机制后,所提方案性能进一步提升到了86.3%,与VOLO性能相同且计算量少43%。
Video Classification
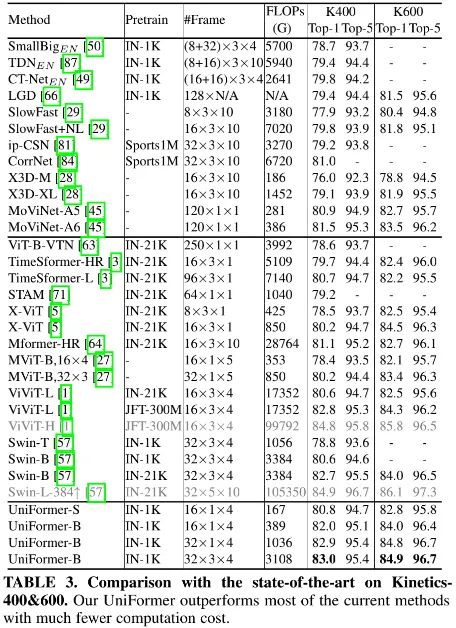
上表给出了Kinetics-400&600数据集上的性能,可以看到:
相比SlowFast,Uniformer-S均取得了1%指标提升且计算量少42x;
相比MoViNet,所提方案能取得了0.5%性能提升(82.0% vs 81.5%),同时输入帧数更少(16fx4 vs 120f);
仅用ImageNet-1K预训练,UniFormer-B超越了大部分现有采用更大数据集预训练的性能。比如相比ViViT-L(JFT-300M预训练)、Swin-B(ImageNet-21K预训练),UniFormerB取得了相当的性能,而计算量在两个数据集上分别少16.7x和3.3x。
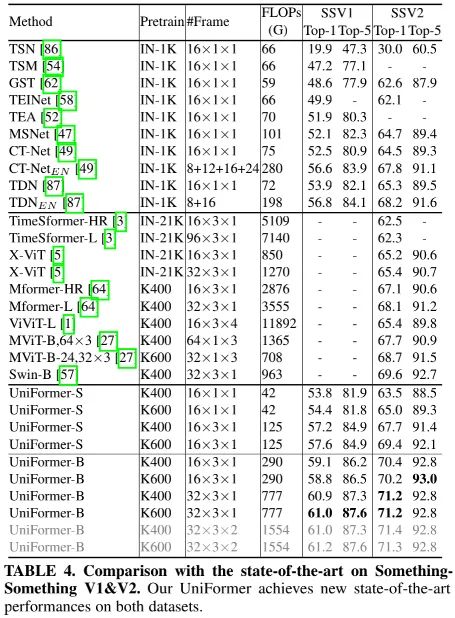
上表为Something-Something数据集上的性能对比,可以看到:
UniFormer-S仅需42GFLOPs取得了54.4%/65.0%的优秀指标;
最佳模型UniFormer-B取得了61.0%/71.2%的SOTA指标。
Object Detection & Instance Segmentation
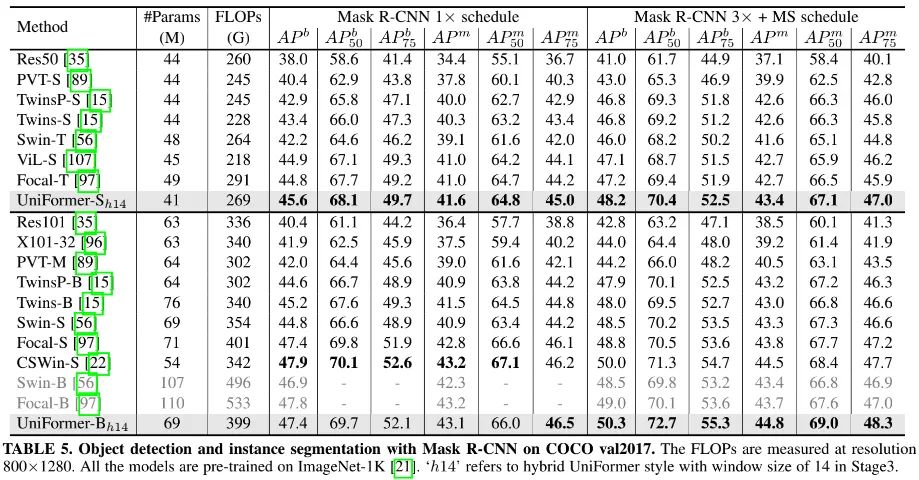
上表给出了COCO检测与分割任务上的性能对比,基础框架为Mask R-CNN,可以看到:
UniFormer取得了优于所有CNN与ViTs的性能;
相比ResNet,所提UniFormer取得了7.0-7.6box mAP与6.7-7.2mask mAP指标提升;
相比SwinT,所提UniFormer取得了2.6-3.4box mAP与2.2-2.5mask mAP指标提升;
当采用更好训练机制时,UniFormer-B以0.3box mAP和0.3mask mAP超越了CSwin-S、Swin-B、Focal-B等方案。
Semantic Segmentation
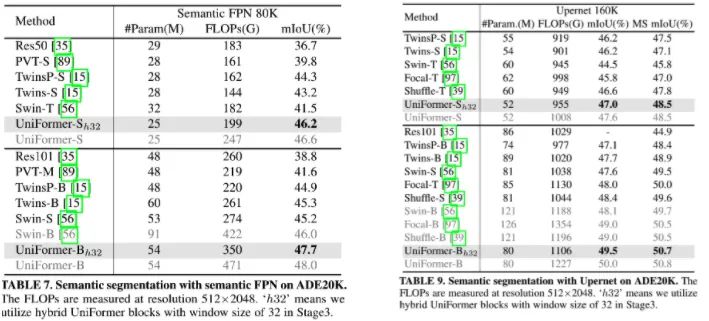
上表给出了ADE20K数据集上的性能对比,可以看到:
基于SemanticFPN框架时,相比SwinT,UniFormer-S/B取得了4.7/2.5mIoU指标提升;
基于UperNet框架时,UniFormer的性能提升2.5/1.9mIoU、2.7/1.2MS mIoU。
Pose Estimation
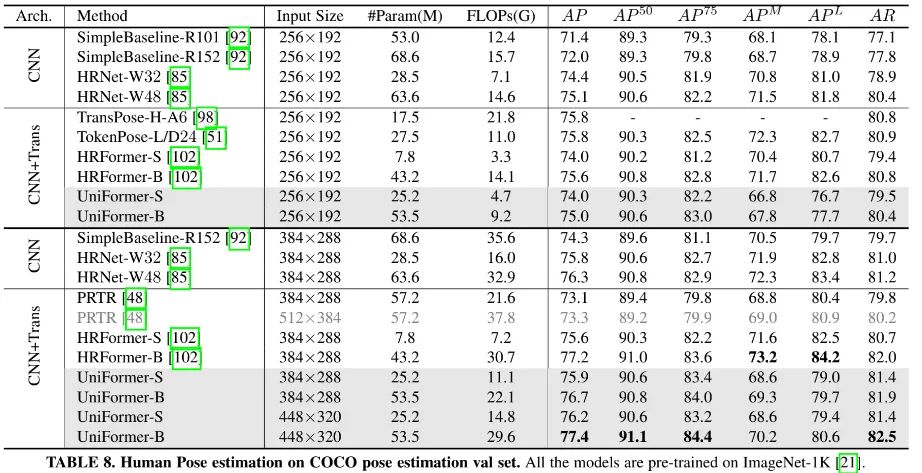
上表给出了COCO姿态估计任务上的性能对比,可以看到:
相比SOTA CNN方案,所提UniFormer与0.4%AP指标差偶尔了HRNet-W48,同时参数量与FLOPs更低;
相比当前最佳HRFormer,UniFormer-B以0.2%AP指标超出,同时FLOPs更低。
没有图示的paper是没有灵魂的,最后就补充个图示效果以供参考。
UniFormer论文和代码下载后台回复:UniFormer,即可下载论文和代码ICCV和CVPR 2021论文和代码下载后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号整理不易,请点赞和在看
这篇关于CNN和Transformer再组合!UniFormer:新的主干网络!在六大视觉任务上大放光彩!...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






