本文主要是介绍深度学习——keras中的Sequential和Functional API,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

大家好,上期推文介绍了Keras的一些特点和一些基本的知识点,不知道大家在平时的时间有没有自己学习一下深度学习相关的知识,或者机器学习相关的知识呢?有这些的预备知识对于学这个专题还是有帮助的。
本期内容我们先来聊一聊Keras中模型的种类,也就是来聊聊Sequential模型与Functional模型,即序贯模型和函数式模型,我们一个个来看。
一、Sequential模型
神经网络模型是一种将信息朝着某一个方向进行传递的模型,方向性的传递形式就很适合以一种顺序(序贯)的数据结构来进行表示,有一种“一条路走到黑”的感觉。在工程项目中使用序贯模型可以解决很多的实际需求,它的主要特点如下:
-
简单的线性结构
-
从开始到结束的结构顺序
-
没有分叉结构
-
多个网络层(输入层,隐层,激活层等等)的线性堆叠
不要觉得它简单功能就不强大,要知道全连接神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等网络都可以使用Sequential Model来进行构建。其构建
模型通常分为五个步骤: 1.定义模型 2.定义优化目标 3.输入数据 4.训练模型 5.评估模型的性能
这里要提醒的是,大家在学习Keras中的时候要有层(layers)的概念。如卷积层,池化层,全连接层,LSTM层等等。在Keras中我们构建模型可以直接使用这些层来构建一个目标神经网络。接下来我们简单的来说说这几个步骤:
1.1 定义模型
可以通过向Sequential模型传递一个层的列表来构造该模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([Dense(32, input_shape=(784,)),Activation('relu'),Dense(10),Activation('softmax'),])上述代码是使用层的列表来构建Sequential模型的,其中堆叠了四层:
第一层是全连接层,神经元个数为32,input_shape=(784,);
第二层是激活层,激活函数为relu;
第三层是全连接层,神经元个数为10;
第二层是激活层,激活函数为softmax;
当然了,我们也可以使用add()方法进行层的堆叠:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))个人比较喜欢第二种方式,十分简单
大家可能有一个疑问,在第一层使用了input_shape,其他层却没有传入这个参数,这是为什么呢?这是因为:后面的各个层可以自动的推导出中间数据的shape,因此就不用传参了。
1.2 定义优化目标
我们知道不同种类的任务有不同的优化目标,也就存在要使用不同的优化器(Optimizer)、损失函数(Loss)和评估标准(Metrics)。在实际的项目工程中,多分类的损失函数我们一般选择categorical_crossentropy,回归问题常用MSE损失函数。
其实这个定义优化目标的过程是整个构建模型中最重要的部分,因为在这部分我们要选择优化器和损失函数。通过选择的优化器和损失函数来对模型中的参数进行计算和更新。在Keras中我们是使用compile()方法来完成:
# 多分类问题
model.compile(optimizer='rmsprop',loss='categorical_crossentropy',metrics=['accuracy'])
# 回归问题
model.compile(optimizer='rmsprop',loss='mse')1.3 输入数据和训练模型
定义优化目标以后就需要进行数据的输入了,在Keras中是使用fit()方法将数据传递到构建的模型当中的。fit()方法具有较多的参数,其返回值是一个History类对象,这个对象包含两个属性,分别为epoch和history,epoch为训练轮数,history字典类型,包含val_loss,val_acc,loss,acc四个key值。

大家可以查看到这些参数的具体含义。一般情况下我们使用的参数主要有:x, y, batch_size,epochs,verbose,validation_split, validation_data等。如:
model.fit(X_train, y_train, epochs=10, batch_size=64, verbose=1, validation_split=0.05)上述代码表示我们输入了X_train, y_train训练集数据,迭代次数为10,数据批次大小为64,verbose = 1表示输出进度条记录,validation_split=0.05表示从训练集中取出0.05比例的数据作为验证集。
1.4 评估模型性能
fit()之后就是在测试数据集上对我们的数据进行验证了,在Keras中我们可以这样来进行模型的评估:
score = model.evaluate(X_test, y_test, batch_size = 64)这个模型的评估方法使用很简单。大家可以看上篇推文,推文中的手写字体识别模型就是使用Sequential模型来搭建的,代码我也贴一下:
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Dense,Activation
path = r'C:\Users\LEGION\Desktop\datasets\mnist.npz'
(X_train, y_train), (X_test, y_test) = mnist.load_data(path)X_train = X_train.reshape(len(X_train),-1)
X_test = X_test.reshape(len(X_test), -1)
X_train = X_train.astype('float32')/255
X_test = X_test.astype('float32')/255y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)model = Sequential()
model.add(Dense(512, input_shape=(28*28,),activation='relu'))
model.add(Dense(10,activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=10, batch_size=64, verbose=1, validation_split=0.05)
loss, accuracy = model.evaluate(X_test, y_test)
Testloss, Testaccuracy = model.evaluate(X_test, y_test)
print('Testloss:', Testloss)
print('Testaccuracy:', Testaccuracy)二、Functional模型
接下来我们来看一下Functional模型。函数式模型称作Functional,仔细研究发现其类名是Model,因此有时候也用Model来代表函数式模型,即Model模型。
我们知道Sequential模型类似一条路走到㡳的结构,如VGG也是一条路走到㡳的模型。那么在实际的工程项目中,如果我们的目标是多个输出或者非循环有向模型,此时我们就应该选择使用函数式模型来构建。
函数式模型是最广泛的一类模型,Sequential模型是它的特例,下图给出了几种模型的简单示例:
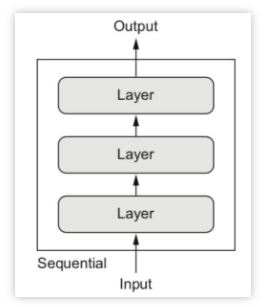
Sequential模型示例
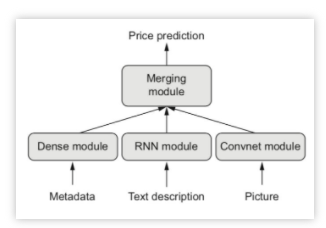
多输入单输出Functional模型的示例
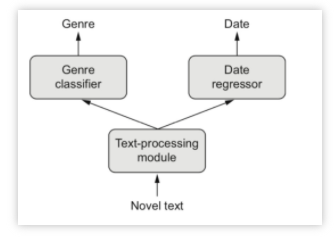
单输入多输出Functional模型的示例
Keras 的函数式模型把层(layers)当作函数来使用,接收张量并返回张量。
我们先使用函数式模型来实现一个序贯模型(全连接网络模型):
from keras import Input
from keras import layers
from keras import models# 构建输入层的张量
input_tensor = Input(shape=(16,))
# 将输入层的返回的input_tensor作为参数输入到第一层网络的Dense中
dense_1 = layers.Dense(32, activation='relu')(input_tensor)
# 将第一层的返回的dense_1作为参数输入到第二层的Dense中
dense_2 = layers.Dense(64, activation='relu')(dense_1)
# 最后一层来构建输出层,并使用10个神经元来进行分类
output_tensor = layers.Dense(10, activation='softmax')(dense_2)
# 将输入层和输出层的张量输入模型中
model = models.Model(input_tensor, output_tensor)# 显示模型的相关信息
model.summary()上述模型的网络结构示意图如下:

我们从图中可以了解到每一层的输出形状,参数情况。
那么基于Functional模型构建过程一般的步骤如下:
-
首先使用Keras的Input()方法来构建输入层,该层一般不含可输入的参数。
-
将输入层返回的张量继续输入到下一层,如果还有下一层,继续此操作
-
将输入层和输出层的张量输入模型中
上述代码只是使用函数式模型来构建一个非常简单的全连接网络。我们还未实现多输入单输出,单输入多输出和多输入多输出的模型,后期打算一个种类使用一期推文来进行详细的介绍。大家可以先学一下机器学习中的多模型融合相关的技术,这对于后期的学习十分有利。
三、总结
想必大家也已经知道了一些Sequential顺序模型和Functional模型相关的知识。对于Sequential而言掌握它是很容易的,大家或许对于函数式模型还不是很熟悉,但是没关系,后续我们会详细的探究不同输入和输出形式的函数式模型,到时候也会结合实例来进行阐述。
这篇关于深度学习——keras中的Sequential和Functional API的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




