本文主要是介绍OpenKG开源系列 | 轻量级知识图谱抽取开源工具OpenUE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

OpenKG地址:http://openkg.cn/tool/openue
GitHub地址:https://github.com/openkg-org/openue
Gitee地址:https://gitee.com/openkg/openue
OpenUE网站:http://openue.openkg.cn
论文地址:https://aclanthology.org/2020.emnlp-demos.1.pdf
开放许可协议:GPL 3.0
贡献者:浙江大学(张宁豫、谢辛、毕帧、王泽元、陈想、叶宏彬、余海阳、田玺、邓淑敏、郑国轴、陈华钧),阿里巴巴集团(陈漠沙、谭传奇、黄非)

知识图谱以结构化的形式描述真实世界中实体间的复杂关系,是人工智能的底层支撑。依托于行业数据和深度学习技术,知识图谱已被广泛应用于诸多产业核心的场景,因此催生了知识图谱构建需求。知识抽取可以从海量的文本或网页的原始数据中提取有价值的信息,最终以结构化的形式进行描述,是支撑知识图谱构建的主要任务之一。然而,由于知识的复杂性和异构性,不同的抽取任务需要设计不同的模型,在一定程度上影响了知识抽取的效率。本文开源了OpenUE工具,其提出了一个简单的思想,即大多数任务可以用一种通用的抽取范式来表示,实现了一个轻量级通用知识抽取工具。本工具的前一个版本已被自然语言处理顶级会议EMNLP2020录用为Demo论文。
本工具更新的内容如下:
1. 重新封装了全新的Pytorh训练测试接口,便于用户调用。
2. 基于通用抽取范式支持多种抽取任务,实现轻量级知识抽取。
3. 新增一键TorchServing功能,实现敏捷知识抽取服务部署。
OpenUE使开发人员可以训练自定义任务,并从文本中提取信息,支持研究人员快速进行模型验证。此外还提供了在线Demo演示,无需进行训练和部署,支持实时知识抽取,包括三元组知识抽取,槽填充和意图检测,事件抽取等。
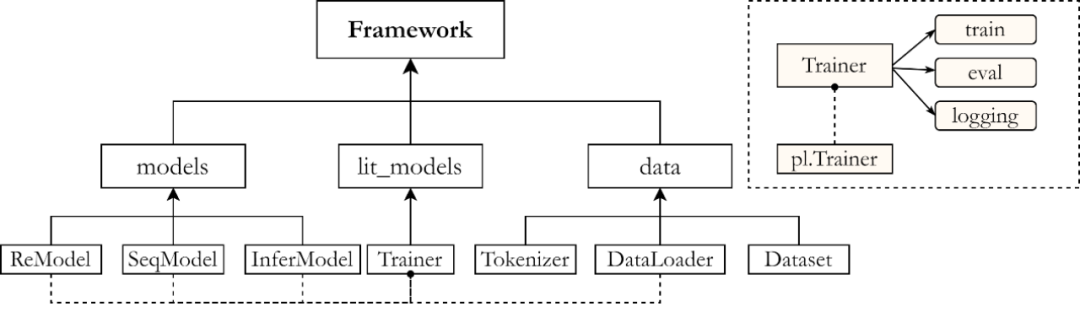
OpenUE架构图
1、应用场景
1.1 实体三元组知识抽取
事实三元组抽取目的是为了从非结构化文本抽取实体以及实体间蕴含的关系。比如对于句子“巴黎被称为法国的浪漫之都”,三元组抽取应获得三元组<法国, 首都, 巴黎>,其中首都是巴黎和法国两个实体的关系。本工具使用了一种简单的思路,即首先对与句子的关系进行分类,然后进行序列标记以提取实体。
关系优先方法在真实场景中是很大帮助,因为大多数句子都包含NA关系(也就是没有关系)。因此OpenUE可以预先过滤掉没有关系的文本,提高计算效率。
1.2 事件知识抽取
从自然语言文本中抽取事件非常具有挑战性。当给定文档时,事件抽取系统需要识别具有特定类型的事件触发词以及包含的元素和角色。在真实场景中,OpenUE先对文档进行基于事件类型分类,进而并基于序列标注进行角色抽取。OpenUE集成了无需触发词检测的事件抽取功能。
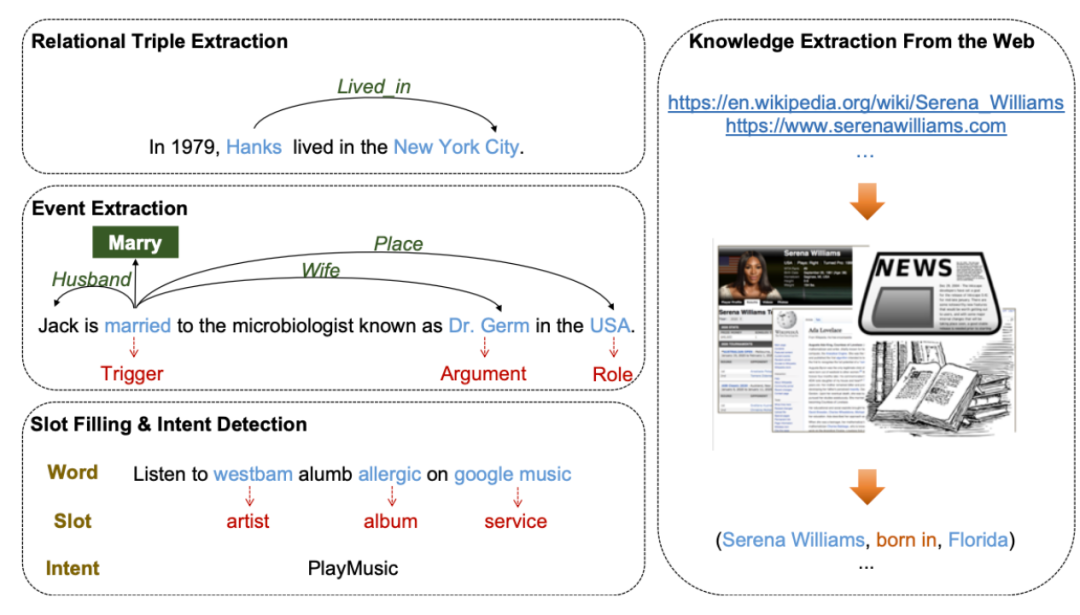
OpenUE应用举例
1.3 槽填充和意图知识抽取
自然语言理解(NLU)对于对话系统至关重要,它通常包括意图检测和槽填充两个任务,为用户话语形成语义解析。例如给定用户的话语,槽填充在单词级别上理解该文本,为指示特定单词分配相应的槽位类型,如下图所示。而意图检测在句子级别上进行,为整个句子打上意图标签。槽填充和意图检测依赖于token级别和句子级别的理解, OpenUE也集成了该任务。
演示系统
2、模块设计
OpenUE新版本主要分为三个模块,models、lit_models和data模块。
models 模块
其存放了主要的三个模型代码实现,针对整句的分类(关系)模型,针对已知句子类别的序列标注模型,还有将前两者整合起来的推理验证模型。其主要基于transformers库中的已定义好的预训练模型。
lit_models 模块
其中的代码主要继承自pytorch_lightning.Trainer。其可以自动构建单卡,多卡,GPU,TPU等不同硬件下的模型训练。我们在其中定义了training_steps和validation_step即可自动构建训练逻辑进行训练。OpenUe硬件不敏感,用户可以使用多种不同环境下调用OpenUE训练模块。
data 模块
data中存放了针对不同数据集进行不同预处理的代码。使用了transformers库中的tokenizer先对数据进行分词处理再根据不同需要将数据变成用户需要的feature。
3、支持数据
中文关系抽取:ske数据集是基于schema的中文信息抽取数据集,其包含超过19万中文句子及50个已定义好的schema。数据集中的句子来自百度百科、百度贴吧和百度信息流文本。数据集划分为17万训练集,1万验证集和1万测试集。
英文关系抽取:webnlg数据集由大量的来自网络的自然语言文本和其包含的事实的三元组(实体和实体之间的关系)组成。数据集有246个关系,并包含了12,863个三元组。
事件抽取:句子级事件抽取DuEE1.0。该任务的目标是对于给定的自然语言句子,根据预先指定的事件类型和论元角色,识别句子中所有目标事件类型的事件,并根据相应的论元角色集合抽取事件所对应的论元。其中目标事件类型 (event_type) 和论元角色 (role) 限定了抽取的范围,例如 (event_type:胜负,role:时间,胜者,败者,赛事名称)、(event_type:夺冠,role:夺冠事件,夺冠赛事,冠军)。其中训练集11908条,测试集3488条。OpenUE先对句子进行事件类型判断,然后根据抽取的类型和句子进行角色识别。
自然语言理解:SMP-2017 数据集。OpenUE处理自然语言理解任务时候分为两个步骤:先意图识别,之后将意图相关的槽位识别出来。其可以识别多种意图如app,电影,音乐等。
医疗三元组关系抽取:中文医疗信息处理基准CBLUE中CMeIE:给定Schema和文本,例如(“subject_type”:“疾病”,“谓词”:“药物治疗”,“object_type”:“药物”),该任务要求系统自动抽取句子中的所有三元组 = [(S1, P1, O1), (S2, P2, O2) ...]。该数据集预定义了 53 个 关系,包括 10 种属关系,43 种其他子关系。OpenUE采用和通用领域相同的方式处理医疗三元组。
4、基本用法
在使用openue工具训练需要先载入我们预先设定好的config文件,存放在github仓库中config目录下。
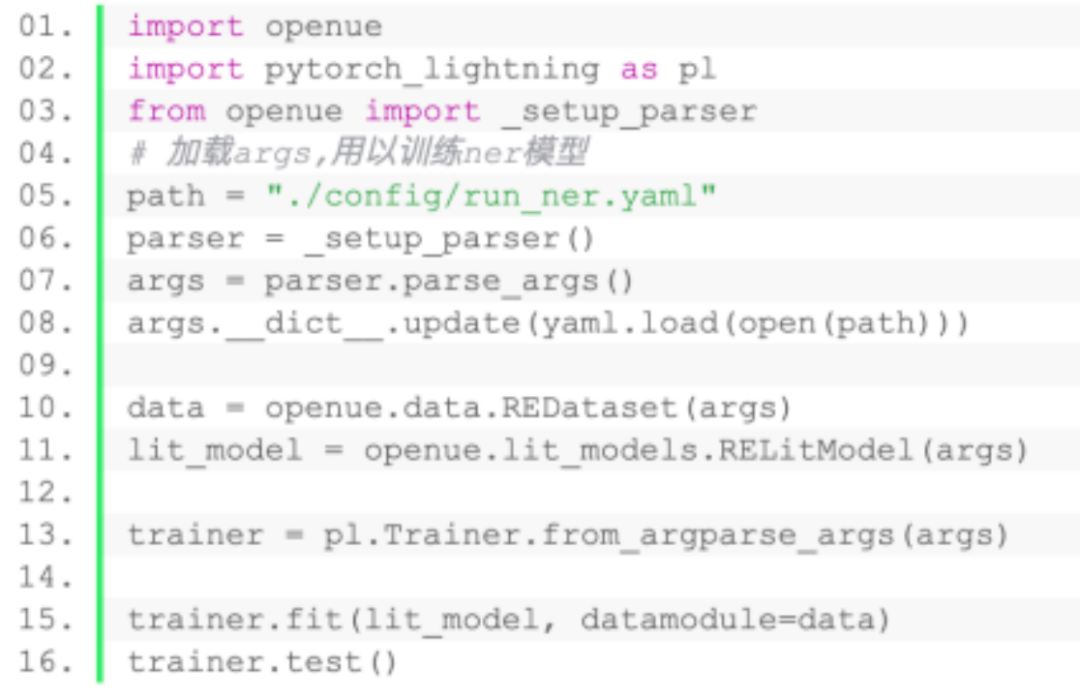
快速上手
配置Anaconda环境

开发者模式使用openue

使用方式
数据格式为json文件,具体例子如下。
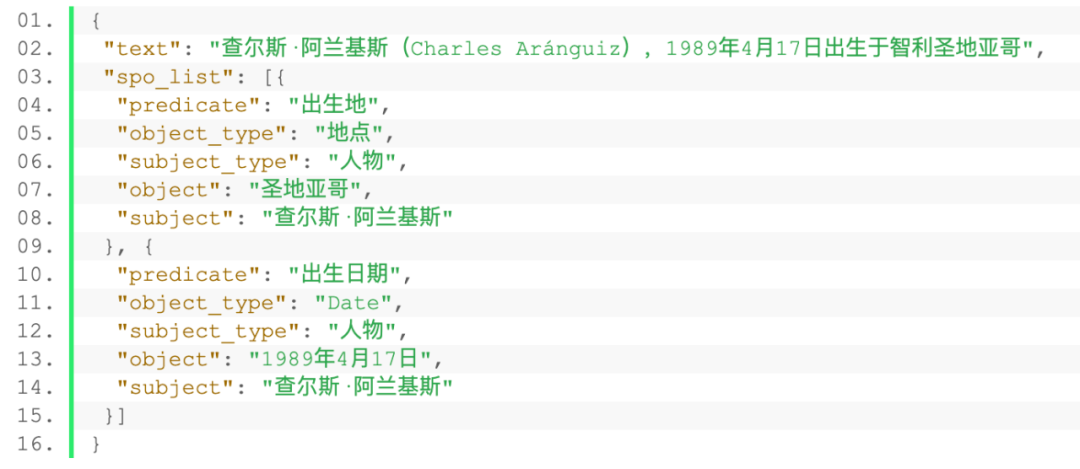
输入输出
样例输入和模型输出,模型输出N个(s,p,o)三元组。

将数据存放在./dataset/目录下之后进行训练。如目录为空,运行以下脚本,将自动下载ske数据集和预训练模型并开始训练,过程中请保持网络畅通以免模型和数据下载失败。
Notebook快速开始
ske 数据集训练notebook使用中文数据集作为例子具体介绍了如何使用openue中的lit_models、models和data。方便用户构建自己的训练逻辑。
若想直接使用shell命令进行模型训练,请依次运行以下命令,将自动下载数据集并训练命名实体识别模型和关系分类模型。

训练过程
1.在配置完成后,用户输入./scripts/run_seq.sh ,该脚本将进行加入特殊label token,以及对数据集的处理。
2.之后进行训练验证和测试,OpenUE会输出在测试集上的分数,这里我们只使用了一个batch作为演示,所以test分数较为随机。
模型部署
1.下载torchserve-docker
首先根据以下步骤下载配置好torchserve-docker。
https://github.com/pytorch/serve/blob/master/docker/README.md
2.创建模型对应的handler类
我们已经在deploy文件夹下放置了对应的部署类handler_seq.py和handler_ner.py。
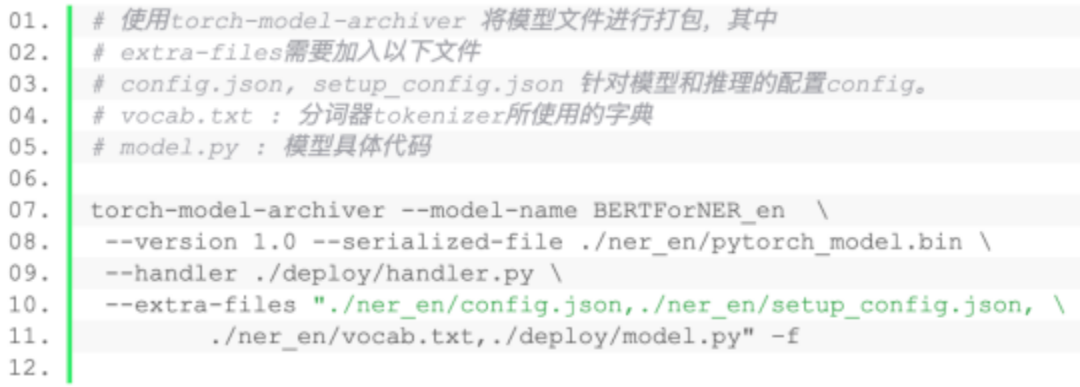
之后将打包好的.mar文件加入到model-store文件夹下,并使用curl命令将打包的文件部署到docker中。
3.模型推理代码示例

5、小结和展望
OpenUE提供了一种简单的思路,可以用一种格式表示许多NLP抽取任务,提供了通用抽取的原型模型实现,并开源了一个可扩展的工具包。我们将持续维护该工具并不断开发和支持新的数据集和功能。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
这篇关于OpenKG开源系列 | 轻量级知识图谱抽取开源工具OpenUE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







