本文主要是介绍【论文】Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory》(Hao Zhou,Tsinghua University,2017刊物不详)
本篇论文出自清华朱小燕老师团队(我猜一作周昊童鞋应该是黄民烈老师的博士生叭)。这篇文章是做NLP的师兄推荐的,聊天机器人作为NLP的一个比较新的方向,其相关研究可以从这篇论文开始扒起。论文分享按照以前组会的习惯整理的,先找到研究的动机和研究的贡献点,再看实现方法,再扫实验部分,最后做一个个人的小结。
本篇论文源码已经公开,Github地址:https://github.com/tuxchow/ecm
- Motivation:
(1)High-quality emotion-labeled data are difficult to obtain in a largescale corpus.
(2)It is difficult to consider emotions in a natural and coherent way because we need to balance grammaticality and expressions of emotions.
(3)Simply embedding emotion information in existing neural models, cannot produce desirable
emotional responses but just hard-to-perceive general expressions.
- Contribution
(1)It proposes to address the emotion factor in large-scale conversation generation.
(2)It proposes an end-to-end framework (called ECM) to incorporate the emotion influence in large-scale conversation generation.
(3)It shows that ECM can generate responses with higher content and emotion scores than the traditional seq2seq model.
-Method
ECM的整体框架如下:
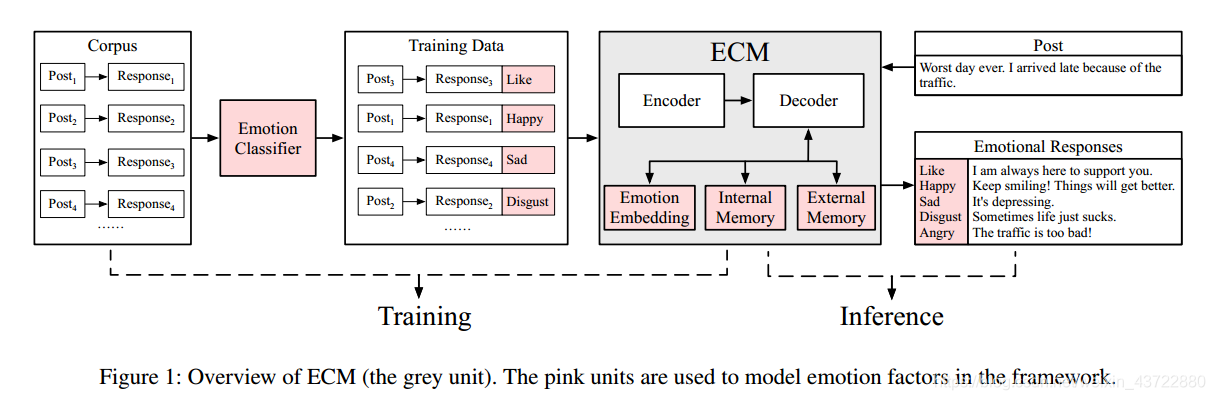 ECM需要实现的目标是:输入对话X(Post)——输出带有不同情感的回复(Responses)。例:
ECM需要实现的目标是:输入对话X(Post)——输出带有不同情感的回复(Responses)。例:
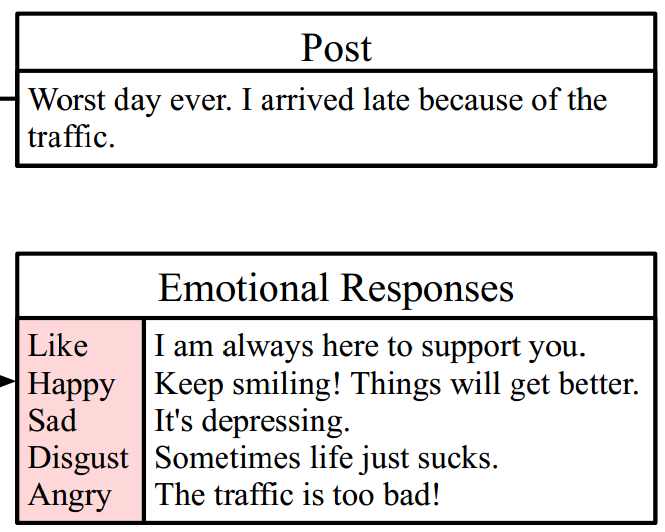
作者首先使用NLPCC数据集(情感分类数据集)训练了一个情感分类器,并用训练出来的情感分类器对STC会话数据集进行情感类别标注,标注后的数据集就是用来训练和测试ECM的数据集啦,也就是得到了框架中的Traning Data部分。
ECM有三个表达情感的模块:情感类别嵌入模块、内部记忆模块和外部记忆模块。三个模块均基于GRU结构。下面分别介绍三个模块如何实现:
(1)Emotion category embedding 情感类别嵌入模块
输入:编码器之前的状态S(t-1);情感类别Ve(标签);情境向量Ct;词嵌入向量e(yt-1).
输出:编码器当前的状态S(t).
函数:GRU(门控循环单元)
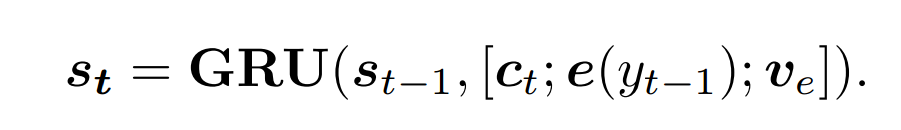
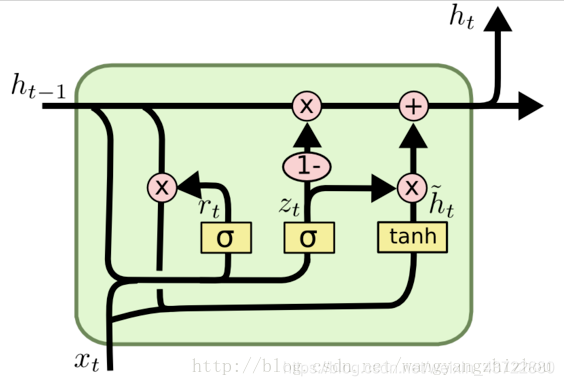
#GRU长这样:(文末有补充的一些资料,差不多够了解GPU的基本知识了)
(2)Internal Memory 内部记忆模块
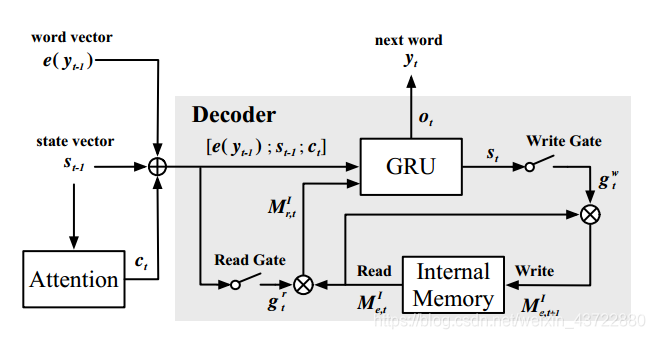
输入:编码器之前的状态S(t-1);情境向量Ct;词嵌入向量e(yt-1).
输出:下一个词汇Yt.
过程计算如下:
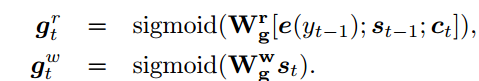
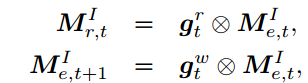
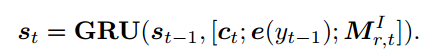
Internal Memory模块实际上是一个6*256的矩阵,记住的值为矩阵M,用来模拟情绪变化。这里个人理解的是一种情绪衰减,在表达一个句子的时候,表达的情感程度会随着句子的表达而减少,当句子表达完了,应用在这个句子上的情感也变成了0。而实现这种机制的方式就是上面第3~4个公式,即矩阵与sigmoid函数相乘(sigmoid函数值在0-1之间)。
(3)External Memory 外部记忆模块
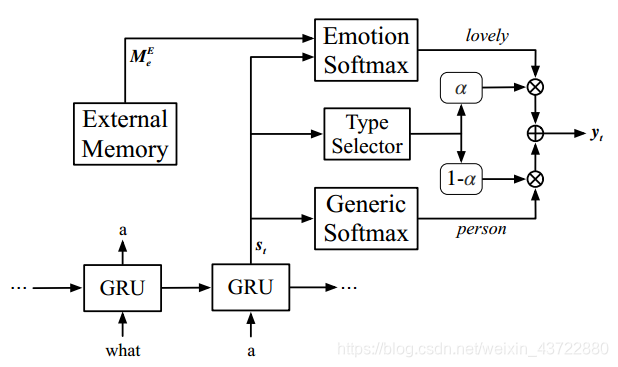
外部记忆模块的一个中心任务就是需要平衡语法和情感,从而得到有效的表达。
输入:编码器当前的状态S(t)
输出:下一个词汇Yt.
过程计算:
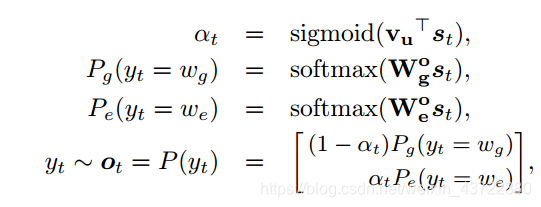
不难看出,外部记忆模块需要实现的是情感类词汇与通用名词的一个拼接。由结构图可以看出,前面两个GRU单元已经生成了部分句子“What a”,External memory需要配合生成下一个输出的词汇(通用名词)的情感词。其中,通用词和情感词分别是从两个词库——通用词库和情感词库里面挑出来生成的。External memory是一个包含以上所说的通用词与情感词的一个长度为40000的词表。
两个softmax很清楚了,分别用来生成情感词和通用词,但是类型选择器(Type Selector)描述不是很清楚,用于计算a的公式中的向量Vu并没有相关说明,猜测是描述External Memeory的词表的概率向量。a本身也是概率值,这个概率值将会在最后用来挑选出各类情感中概率最高的答句作为最终输出。
另外,感觉图有点问题,External Memeory既然是包含通用词和情感词的词表,按道理来说应该不仅是连接Emotion Softmax,还应该连上Generic Softmax才对。
(4)Loss
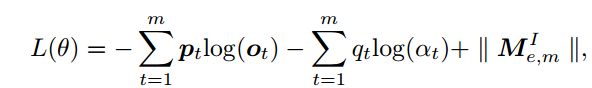
Loss由两部分组成,一个是内部记忆模块的衰减矩阵的正则化项,另一个是外部记忆模块的情感/通用的选择项。因为ECM不仅需要表达情感,还需要平衡句子的语法和情感。
最后,以上三个部分不是必须都有的,去掉任何一个模块系统仍能工作,但是会降低准确率。个人理解三个部分相当于加在ECM的不同部分,所以既不是串联也不是并联。
- Experiment
实验对比了ECM与Seq2Seq及Emb生成句子的复杂度和准确度。结果相对比较好。因为是EmotionalChattingMachine的首要提出者,所以能比的研究也很少。
实验结果不贴了,大家自行看论文就好。
- Summary
这篇论文花了大概2天多的时间去细读,这个框架还是非常Nice的,内外部记忆设计十分巧妙。自己刚开始接触这个领域,没有办法评价,所以各位看官参考即可。
最后,文末是自己在读论文过程中补充的一些知识,因为每个人基础不同,所以对于不同人来说补充资料可能过多也可能过少,大家参考看看即可。
- Knowledge supplement
1、Encoder-decoder framework
(1)Paper :https://arxiv.org/abs/1704.01074
(2)参考地址:https://blog.csdn.net/program_developer/article/details/78752680
(3)seq2seq参考地址:https://www.jianshu.com/p/1c6b1b0cd202
2、GRU神经网络(LSTM的一种变形结构)
参考地址:https://blog.csdn.net/wangyangzhizhou/article/details/77332582
3、beam search —集束搜索
参考地址:https://blog.csdn.net/qq_16234613/article/details/83012046
4、Ablation tests—消融实验
参考地址:https://www.zhihu.com/question/291655038
5、Fleiss’ kappa 分析和Kappa系数
参考地址1:https://blog.csdn.net/qq_31113079/article/details/76216611
参考地址2:https://blog.csdn.net/xtingjie/article/details/72803029
参考地址3:https://blog.csdn.net/g863402758/article/details/62037564
这篇关于【论文】Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

