本文主要是介绍论文笔记:Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总所周知,许多对话系统的回复都比较单调或中性,降低了对话体验。而且,情感智能是人工智能至关重要的一部分,它能够感知,识别,理解用户的情感,并依此调节自身情感,给出符合情绪的表达。
该篇论文设计了一个情绪化的对话生成模型。该模型应用于开放领域对话系统,可以将情绪信息引入到对话生成模型中,根据情绪类别生成相应回复语句。模型接受单轮的对话上文,即可生成基于不同情绪类别的对话下文(也可以增加输入指定的情绪类别生成相应的单一情绪的回复下文)。
该模型使用了三个不同的机制来分别处理大规模对话生成任务中的情绪。分别为:
1、emotion embed:通过嵌入情感类别来模拟情绪表达的高级抽象。
2、internal emotion memory:捕捉内部隐含情绪状态的改变。
3、external emotion memory:使用带有外部情感词汇的明确的情感表达。
一、引言
在处理大规模对话生成任务的情绪因素问题上,主要面临三个调整:
1、情绪标注是一个非常主观的任务,因此情感分类比较困难。
2、很难以自然和连贯的方式考虑情绪,因为我们需要平衡语法和情绪表达。
3、仅仅用现有的神经模型来嵌入情感信息,不仅无法得到理想的回复,而且难以察觉一般表达式中的情绪。因为有些句子中的情绪相当含蓄,模糊或隐藏的很深。
为了使句子中的情绪表达更自然和连贯,作者设计了一个sequence-to-sequence模型,该模型采用了用于情感表达生成的新机制:
1、动态平衡语法和情感的内部情绪状态
2、帮助产生更明确的情感表达的外部情感记忆
该模型特点:该模型是数据驱动的,不依赖任何语言工具和定制化的参数;能建模输入post和response之间的多种情感交互。
情绪的感知与表达能力在对话领域中起到了至关重要的作用。Emotional Chatting Machine (ECM) 模型,将情绪信息引入到对话生成模型中,提升了对话中对情绪的表达能力并且使得生成的对话更为恰当,下图为本模型的总体框架:

ECM 的基础架构为 Encoder-Decoder 结构,在此基础上,为了引入可控的情感信息辅助生成,作者在 Decoder 部分加入了 Emotion Embedding, Internal Memory, External Memory 三个模块进行情绪的高维表示、内部状态建模以及生成情绪词的建模。这些模块可以在代码中进行使用和删去,以进行不同模块的训练和测试。
二、情绪分类器
为了获得大规模的有标签的情绪数据集,论文作者先利用人工标注的数据集(NLPCC2013 and NLPCC2014 dataset)训练了多个情感分类器,选择了其中效果最好的Bi-LSTM分类器。然后利用该分类器去标注STC数据集(Shang,Lu,and Li 2015),得到6类情感数据集。
该论文要解决的核心问题是:在给定一个post和response情感类别的情况下生成一个情绪化的回复。
有多种方式可以选择回复的情绪类别:给定聊天机器人个性化的知识和许多背景知识;另一种方法是使用训练数据为给定post中的情绪找到最频繁的响应情绪类别,并将其用作响应情绪
三、Emotion Category Embedding
在响应生成中对情绪进行建模的最直观方法是将要生成的响应的情绪类别作为附加输入。
对于每个情感类别e,随机初始化情感类别的向量。将
和词嵌入
和上下文向量
一起输入decoder中更新decoder的状态
。
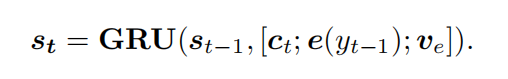
四、Internal Memory
情感类别嵌入在生成过程中不会改变,这可能会牺牲句子的语法正确性。
在decoder过程开始前,每个类别都有一个内部情绪状态。在每一步,情绪状态都会衰减一定量。一旦decoder完成,情绪状态量应该衰减到0,表示情感是被完全表达的。

五、External Memory
内部情绪状态的变化与单词之间的相关性是隐含的,而不是直接可观察的。
句子中包含的情绪词的不同导致句子情绪表达也不同。例如:lovely和awesome相比于普通词person和day,有着更强的情绪表达。external memory模块通过给情绪词和普通词分配不同的产生概率来明确的建模情绪表达。

六、评估
ECM模型与基准模型在自动评价方法的实验结果如下:

ECM与基准模型对话样例如下:

总结:
该篇论文给我的启发就是智能的对话系统必须是带有情绪的,能针对不同的情绪给出不同的回复。在该任务中的一个难点就是情绪数据的标注问题,一千个人就有一千个哈姆雷特,每个人对同一句话的情感感受是不同的,这对分类器的性能影响很大。其次,该模型只是用于生产不同的情绪表达,但是并没有讨论最终该返回哪个情绪表达给用户。
这篇关于论文笔记:Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








