本文主要是介绍盘点 gma 中为 矢量数据 设计的切片操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据切片是 Python 中非常实用的方法,Numpy、Pandas 等第三方库的切片操作为数据处理提供了不少便利。如果能对栅格/矢量数据进行切片,那会使地理数据处理也变得方便和快捷。
本文基于 gma 2.0.7 开始,盘点针对打开的 矢量数据(Layer) 的切片操作方法。
gma 网站:https://gma.luosgeo.com
PyPi 项目:https://pypi.org/project/gma/
示例数据(CTAmap):https://www.shengshixian.com/
矢量数据切片
from gma import io
Layer = io.ReadVector("2023年省级.shp")
一些基本方法
另存矢量图层
Layer.SaveAs('TestLY.shp', Format='ESRI Shapefile')
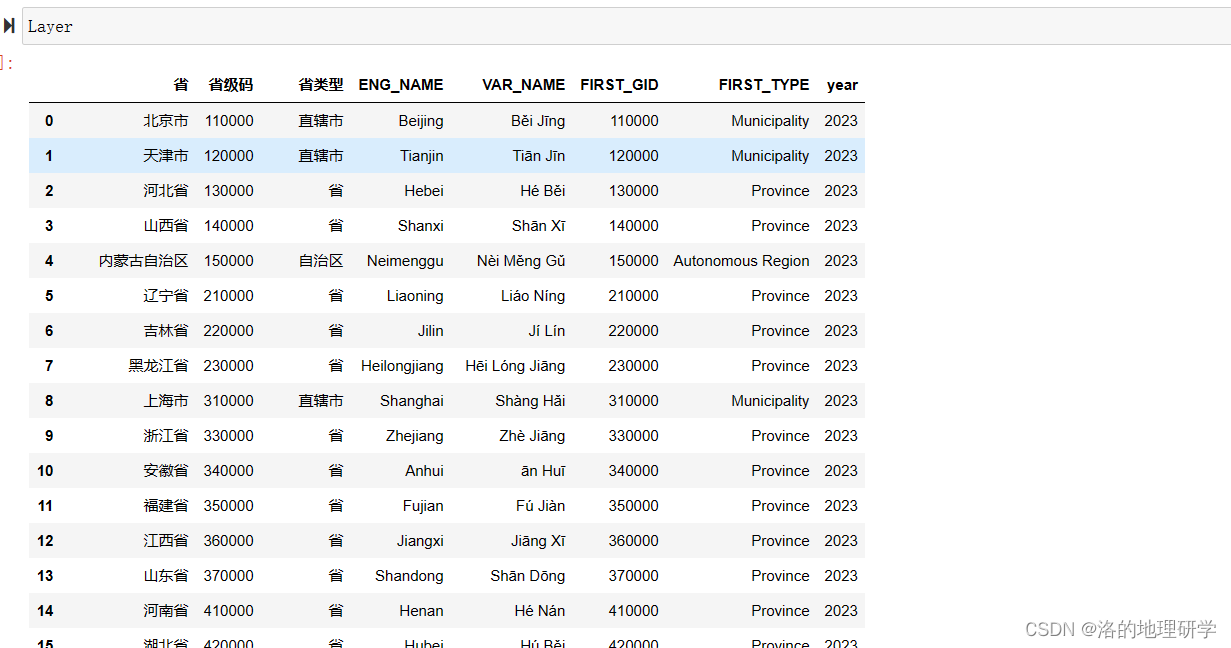
矢量属性表
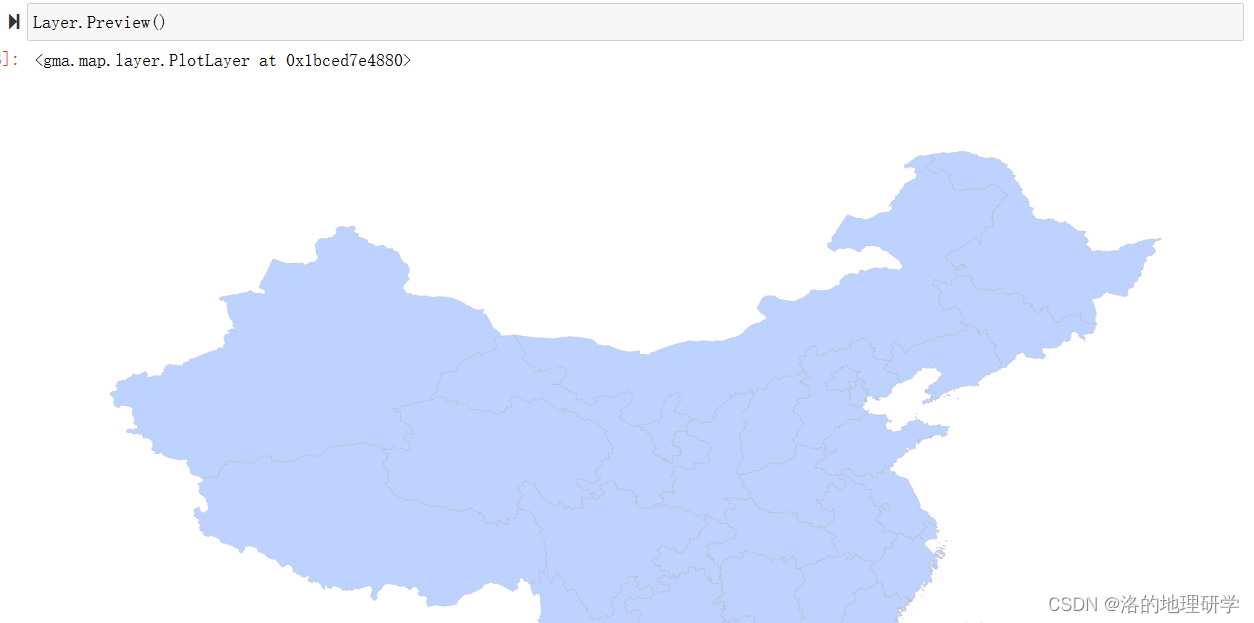
预览
切片方法说明
Layer[要素序号/序号列表或序号切片, 字段名/字段名列表] --> Layer
第一个参数:整数、整数型列表或切片器(slice),操作要素 Feature。
第二个参数:(字段名)字符串、字符串列表,操作字段。
可以依次配置二个参数,被忽略的参数默认为全部
示例1:提取第5个要素
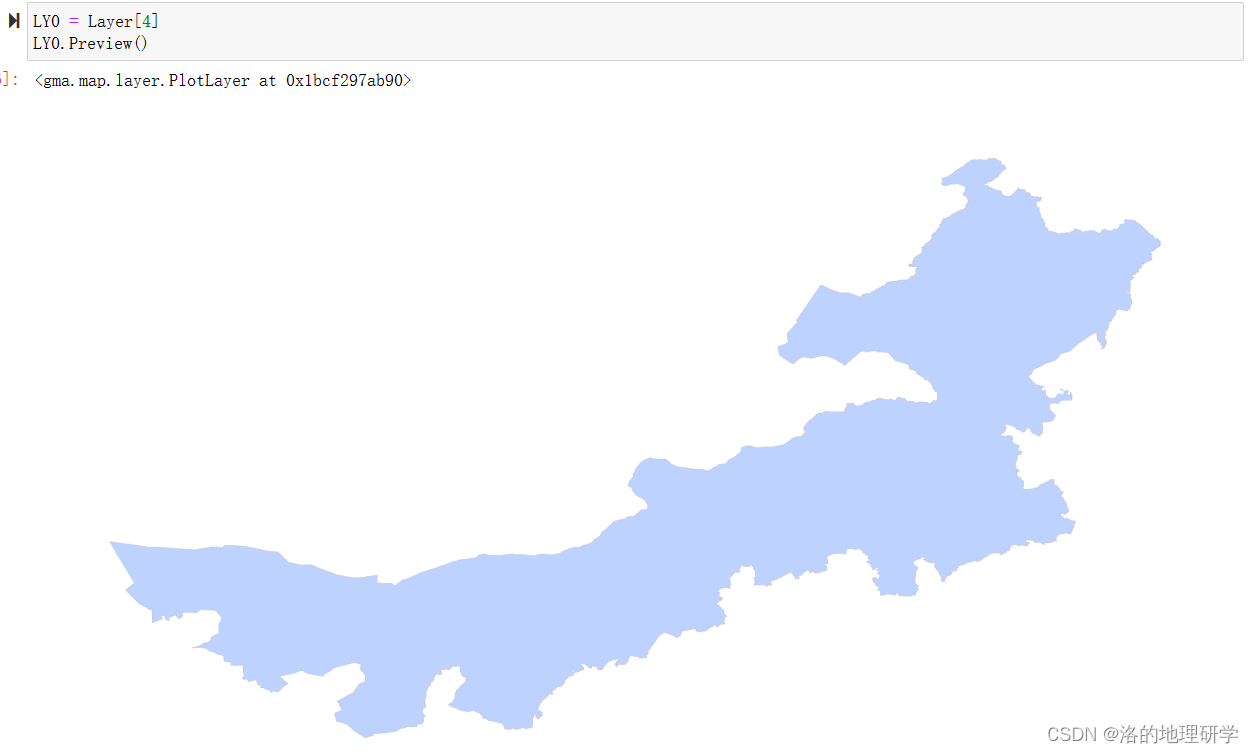
示例2:提取前5个要素
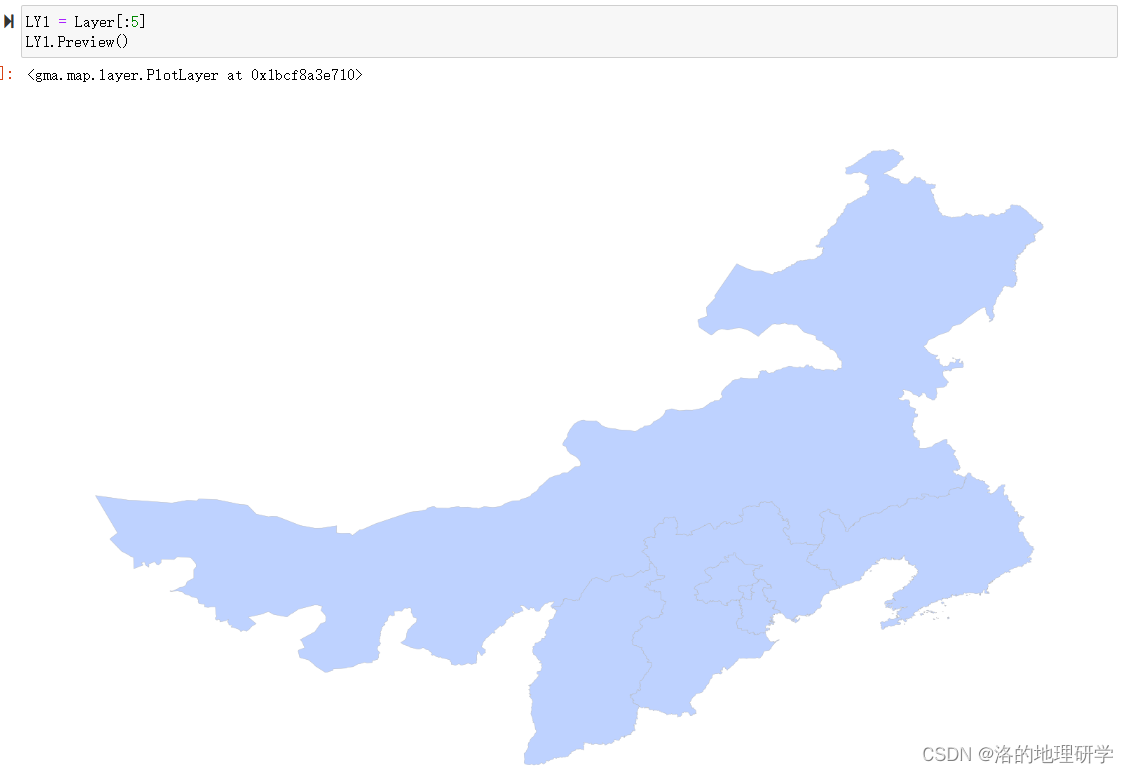
示例3:从第1个要素开始,每隔5个要素提取一个

示例4:保留1个字段
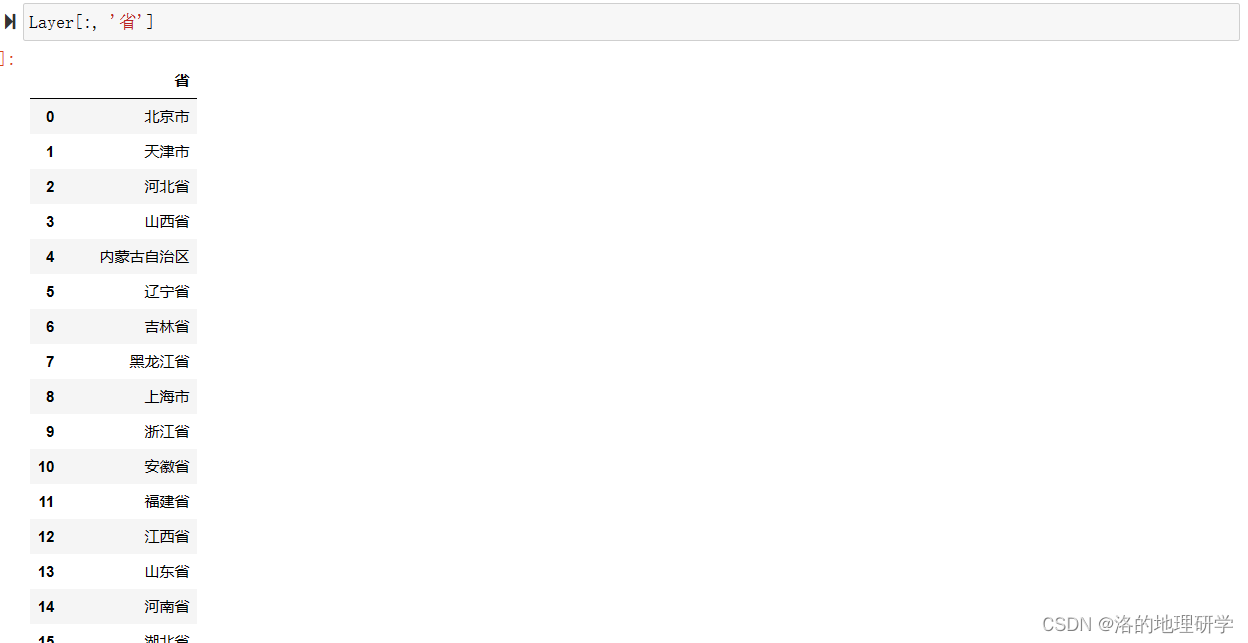
示例5:保留多个字段
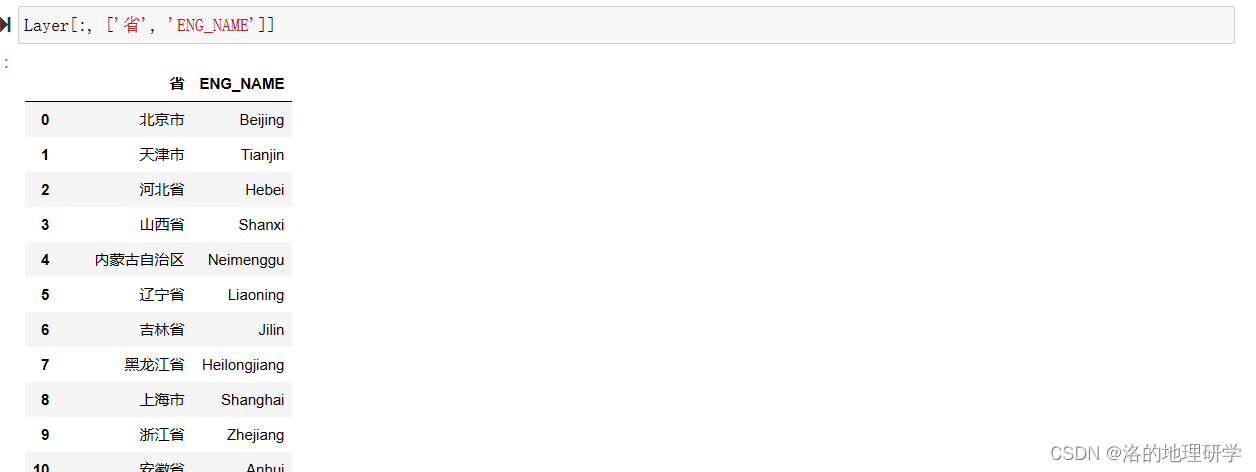
示例6:提取前5个要素,并保留“省”字段
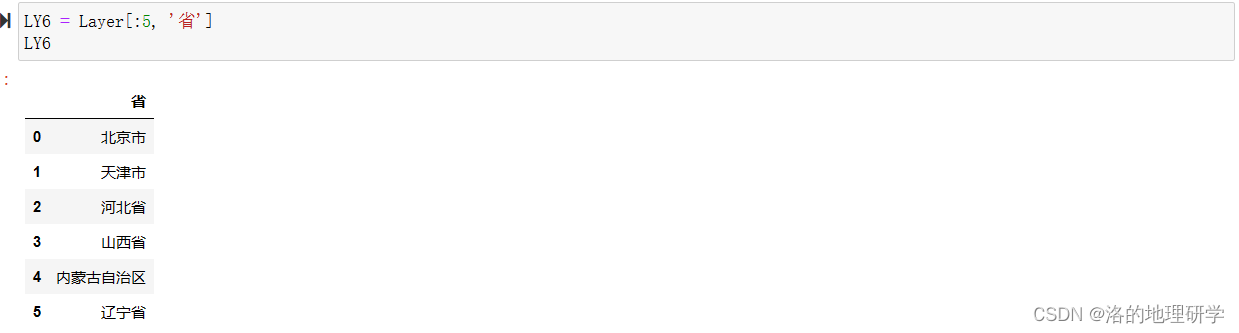
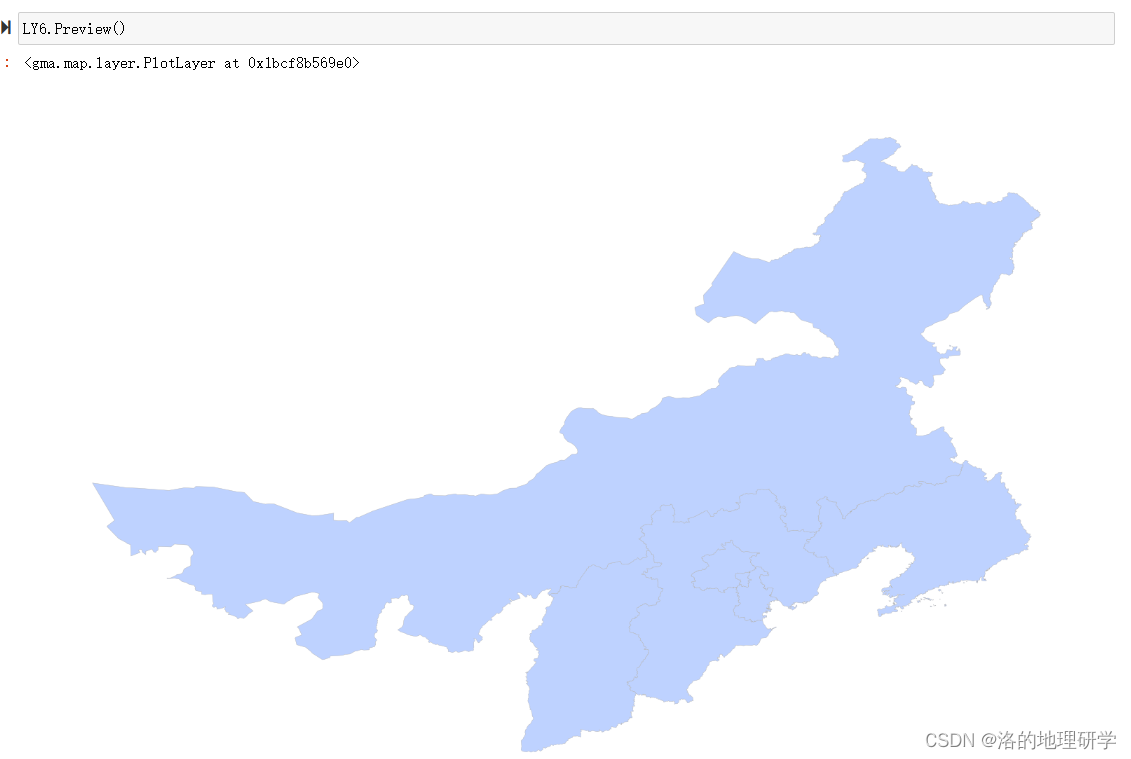
这篇关于盘点 gma 中为 矢量数据 设计的切片操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






