本文主要是介绍Robot Framework使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二,最基本流程
点击返回目录
2.1创建项目New Project
File->New Project

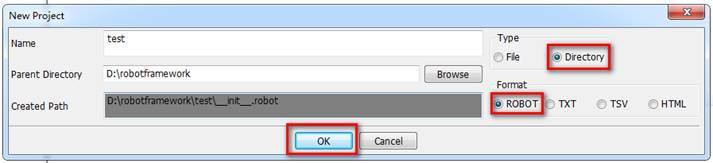
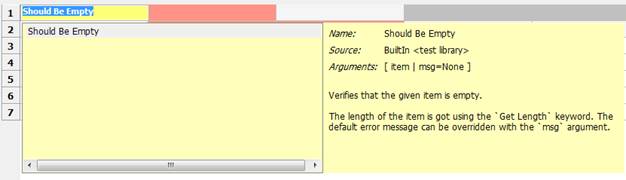
注:选择directory原因是,在directory的项目下可以创建测试套件,如果是tpye为file,则只能创建测试用例,这不利于用例的管理。
2.2创建测试套件New Suite
右键项目Test,点击New Suite。
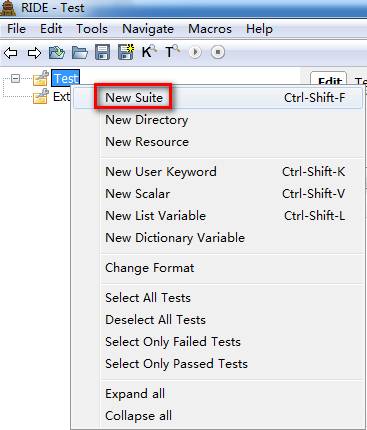

注:选择file原因是,在file的测试套件下可以创建测试用例,如果是tpye为directory,还得重新再继续建file的测试套件,才能创建测试用例,因为测试用例只能在file类型下创建。
2.3创建测试用例New Test Case
右键测试套件,点击New Test Case。
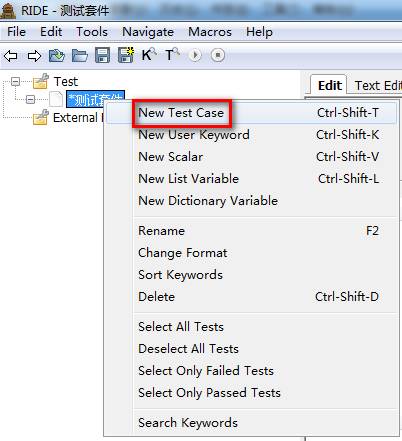

最终页面显示
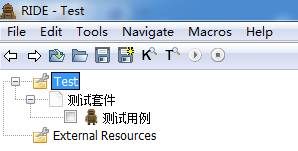
点击返回目录
3.1测试套件工作区说明
3.1.1测试套件Edit区
大体分成4个部分。
(1)加载外部文件
Library:加载测试库,主要是[PYTHON目录]\Lib\site-packages里的测试库。具体操作可查看博文下方的“4.2第三方库”。
Resource:加载资源,主要是你工程相关的资源文件。具体操作可查看博文下方的“5.2.5导入Resource”。
Variables:加载变量文件,不怎么用,可暂时忽略。
(2)定义内部变量
Add Scalar:定义变量。
Add List:定义列表型变量。
Add Dict:
(3)元数据定义
Add Metadata:定义元数据。
(4)settings
一般settings是隐藏的,点击settings按钮,则会显示。
Documentation:文档,每一项都有。可以给当前的对象加入文档说明。
Suite Setup指的是测试套件启动的时候就执行某个关键字。(例:我在Suite Setup设置了Sleep | 5sec,表示等待5秒,要注意关键字的参数要使用 | 分隔)
Suite Teardown指的是测试套件结束的时候就执行某个关键字。
Test Setup指的就是案例启动的时候执行某个关键字。
Test Teardown指的就是案例结束的时候执行某个关键字。
Test Template:测试模版,这是可以指定某个关键字为这个测试套件下所有TestCase的模版,这样所有的TestCase就只需要设置这个关键字的传入参数即可。
Test Timeout:设置每一个测试案例的超时时间,只要超过这个时间就会失败,并停止案例运行。这是防止某些情况导致案例一直卡住不动,也不停止也不失败。
Force Tags:在文件型Suite这里还可以继续给子元素增加Force Tags,但是他不能删除父元素设置的tags。
Default Tags:默认标记,其实和Force Tags没啥区别的。
Arguments:传入参数。
Return Value:返回值。

3.1.2测试套件Text Edit区
测试套件测试用例文本信息。
3.1.3测试套件Run区
Execution Profile:选择运行方式,里面有pybot、jybot和custom script。默认pybot即可。
Start:运行案例。若该测试套件下的测试用例前无勾选,则默认执行该测试套件下所有的用例。若测试用例勾选,则执行该测试陶见下勾选的用例。
Stop:停止案例。
Report和Log: 报告和日志,要运行之后才能点击。他们的区别,报告更多是结果上的展示,日志更多是过程的记录,更多使用的还是日志。
Autosave: 自动保存,如果不勾选,在修改了案例之后如果没有保存的话,运行案例时会提示是否保存。勾选则在运行时自动保存了。
Arguments: pybot的参数(或者jybot等)。完整版的参数可以在doc命令行输入pybot.bat --help
Only Run Tests with these Tags: 只运行这些标记的测试案例。在case的setting里可以添加tag。
Skip Tests with these Tags: 跳过这些标记的测试案例。在case的setting里可以添加tag。

3.2测试用例工作区说明
3.2.1测试用例Edit区
(1)settings
Documentation:文档,每一项都有。可以给当前的对象加入文档说明。
Setup指的就是案例启动的时候执行某个关键字。
Teardown指的就是案例结束的时候执行某个关键字。
Tags:标记某个测试用例。在Run区中Only Run Tests with these Tags和Skip Tests with these Tags,会通过这个标志位来识别是否运行或跳过用例。
Timeout:设置每一个测试案例的超时时间,只要超过这个时间就会失败,并停止案例运行。这是防止某些情况导致案例一直卡住不动,也不停止也不失败。
Template:测试模版,这是可以指定某个关键字为这个测试套件下所有TestCase的模版,这样所有的TestCase就只需要设置这个关键字的传入参数即可。
(2)表格区
最重要的部分,编写测试用例。
第一列一般写的是关键词,关键词的来源包括BuiltIn库,第三方导入库,自己编写的导入库。详见博文下方关于库的说明:四,Robotframework库的介绍。
使用技巧:
通过ctrl+alt+space可以自动带出相关关键字。以及相关用法,里边有对入参的说明。
Ctrl+鼠标悬浮(即鼠标在某个关键字上),可以直接显示关键字的相关用法。
第二三四五列,一般是入参,红色的表示必填的入参。浅灰色表示选填的入参。深灰色表示无需填写。

输入sho再同时按住ctrl+alt+space键,则可以自动带出相关关键字,以及选中关键字的用法。
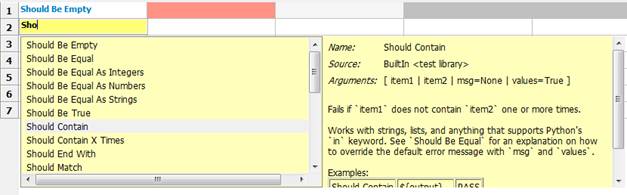
对于已输入的关键字,忘了其用法,可以点击输入框再同时按住ctrl+alt+space键,即可查看该关键字的用法。
3.2.2测试用例Text Edit区
同测试套件。
3.2.3测试用例Run区
同测试套件。
点击返回目录
4.1BuiltIn内建库
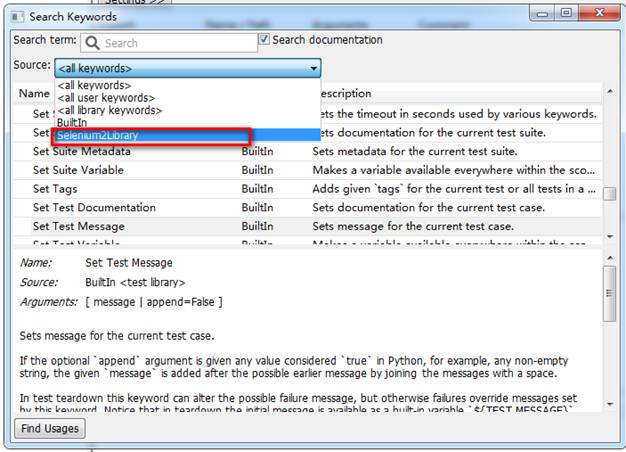
首先先介绍下robotframework的库,通过点击F5快捷键。目前只有内建的库BuiltIn,关于内建的库BuiltIn的关键字说明请查看另外一篇博文:学习Robot Framework必须掌握的库—-BuiltIn库。
注:其实关键字就是方法名函数名而已。
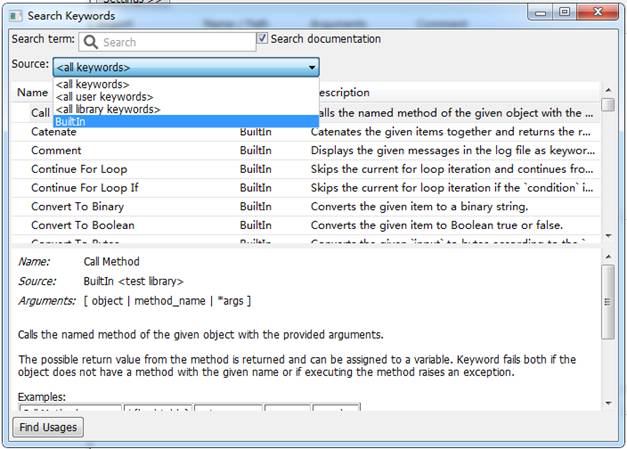
只有内建的库往往还不能满足需求,还可以导入第三方库,如操作页面的Selenium2Library。
第三方库,主要是[PYTHON目录]\Lib\site-packages里的库,一般安装的库会在此目录下。Selenium2Library库的安装也可以详看笔者的另外一篇博文:Robot Framework的环境搭建。博文中有说明Selenium2Library库的安装。
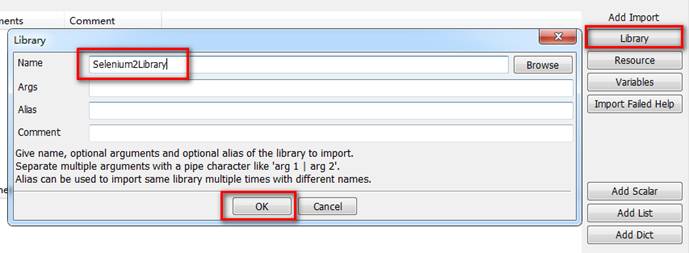
在测试套件下的工作区的右方,点击Library,在弹出框的name栏输入“Selenium2Library”,点击OK即可。
当工作区的Library那一行黑色显示,说明导入成功(如果显示红色说明导入不成功,可自行百度解决)。
点击F5快捷键查看,可查看多了一个Selenium2Library的库。
4.3导入自己编写的库
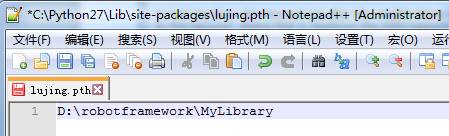
比如说有些功能想自己编写,比如说如下代码,想要导入实现校验url的功能,文件名为Myimport.py(文件名随意取的,最好是英文的),该文件保存在D:\robotframework\MyLibrary,此时需要将该路径添加到[PYTHON目录]\Lib\site-packages下的后缀名为pth的文件(文件名随意取的,最好是英文的)中。
# -*- coding:utf-8 -*-
"""
自己编写,验证获得一个URL地址的扩展名。
"""
import re
def Matchurl(str0):
u'''
验证url的有效性
'''
str1=re.split("[.]",str0)
listt = ['php','html','asp','jsp']
if str1[-1] in listt:
return "TRUE"
else:
return "FAIL"
if __name__=='__main__':
str_input='hehe.php'
print (matchurl(str_input))
然后重启ride,在测试套件的工作区的右方,点击Library,在弹出框的name栏输入“Myimport”,点击OK即可。
点击F5,即可看到导入自己编写的库。
注意,在Myimport.py文件中编写函数描述时,前面要加u,否则F5查看时,会乱码。
注意,在Myimport.py文件中函数命名为MatchUrl和Match_Url,在ride中都会解析为Match Url。

五,用例编写及执行
点击返回目录
5.1编写百度搜索的测试案例。
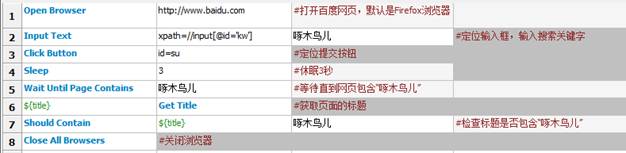
关于selenium2Library的关键字使用,可自行百度“robot framework的selenium2Library的操作手册”,网上大把说明。
这里提一句,关于定位元素,可以通过id,name,xpath,link,css,tag等定位。
Id定位:id=kw
Name定位:name=wd
Xpath定位:xpath=//input[@id='kw']
Link定位:link=link_text
Css定位:css=#kw
Tag定位:tag=input
具体定位方式跟selenium的如出一辙,可以查看笔者另外一篇博文:Selenuim+Python之元素定位总结及实例说明。
5.2分层方法-案例层和流程层分离
如果想改变输入框的输入词,则需要不停的复制case,为了减少冗余,可以做一个简单的分层,把搜索流程剥离成一个关键字,然后再不同的case中调用这个关键字,然后传递不同的参数,以进行不同数据在同一流程下测试。
那如何分层呢?
5.2.1创建User Keyword
先选中case中所有的脚本,右键选择Extract Keyword。
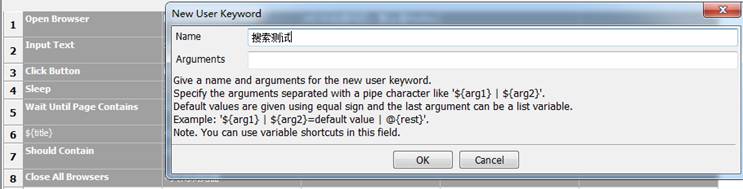
此时左边区域会出现“搜索测试”User Keyword,该User Keyword在测试套件下,一般测试套件不放置User Keyword,建议User Keyword放置在Resource下。
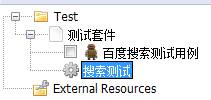
5.2.2创建Resource
如果存在可以不需要创建。
右键项目Test,点击New Resource。
我这里新建的Resource叫做MyResource.txt.

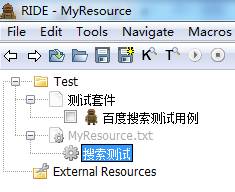
5.2.3将User Keyword移至MyResource下。
5.2.4User Keyword入参设置
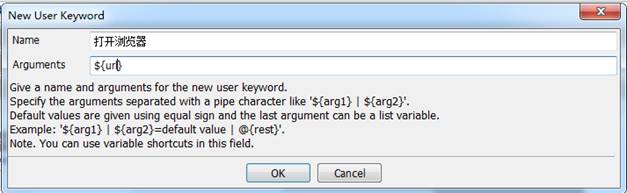
由于搜索数据可变,将其作为入参,变量用${}表示,在settings的Arguments设置,若是有多个入参,那么用|分隔,如${入参1}|${入参1}

需要在测试套件中导入Resource,才能使用该Resource下的User Keyword。这一步别忘了哦。如果之前导入过,则忽略。
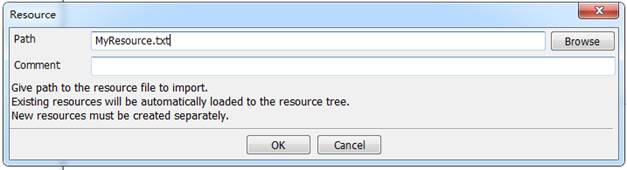
在测试套件下的工作区的右方,点击Resource,在弹出框的name栏输入“MyResource.txt”,点击OK即可。
当工作区的Resource那一行蓝色显示,说明导入成功(如果显示红色说明导入不成功,可自行百度解决)。
点击F5快捷键查看,可查看多了一个MyResource.txt的库。
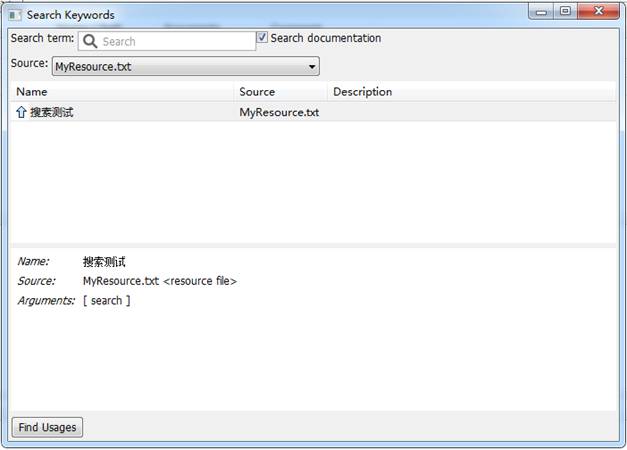
5.2.6查看测试用例
会发现原来的一串表格代码编程“搜索测试”User Keyword,且还有个必须输入的入参。

这样可以轻松的添加多个测试案例了。

5.3分层方法-流程层和元素层分离
将搜索测试中的内容继续分层,将底层的关键字继续拆分。
5.3.1创建Resource
如果存在可以不需要创建。
右键项目Test,点击New Resource。
我这里新建的Resource叫做ElementResource.txt。
创建之后,记得在MyResource.txt工作区下,导入ElementResource.txt资源哦。如何导入,详见“5.2.5导入Resource”。
5.3.2创建User Keyword
选中Open Browser那一行,右键选择Extract Keyword。
5.3.3将User Keyword移至ElementResource.txt下。
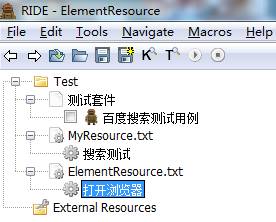
5.3.4将“打开浏览器”的入参值由“http://www.baidu.com”改为${url}
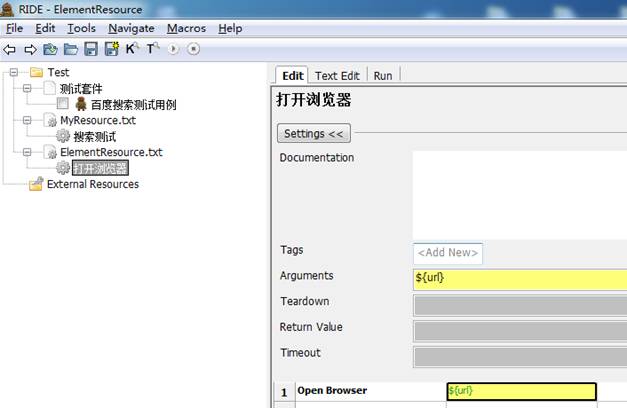
此时,搜索测试中,打开浏览器的入参输入框显示红色,说明必须有一个入参,可以填写“http://www.baidu.com”。
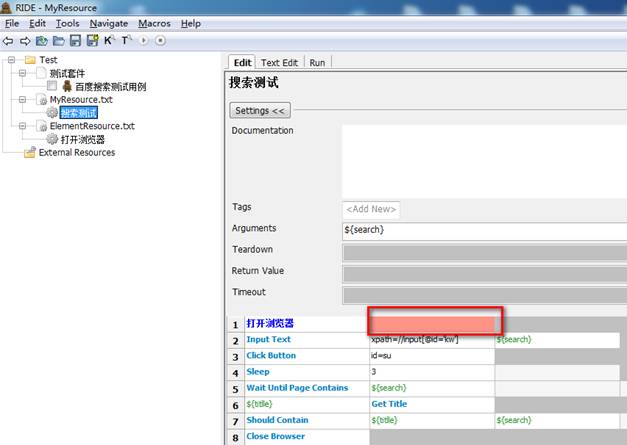
5.3.5剩余关键字
剩余关键字重复5.3.2-5.3.4操作。
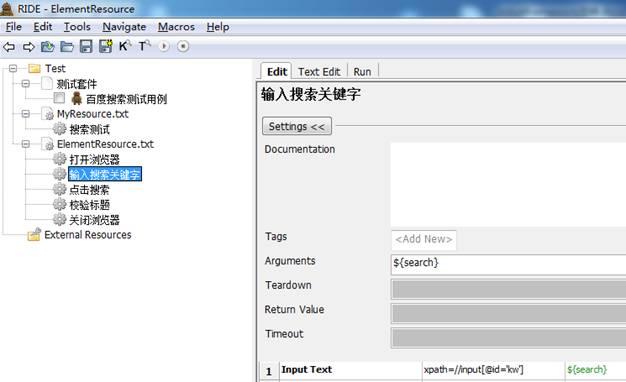
输入搜索关键字
点击搜索
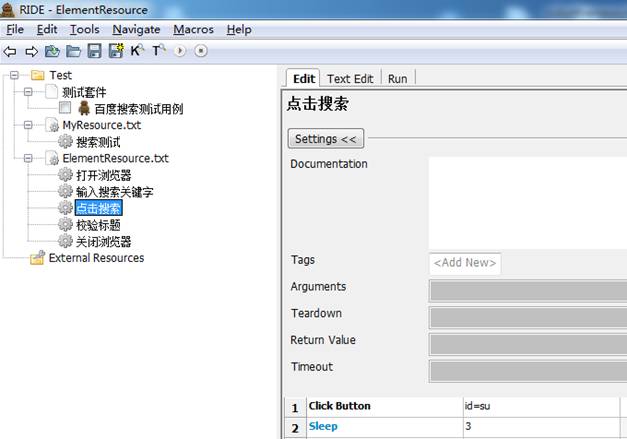
校验标题
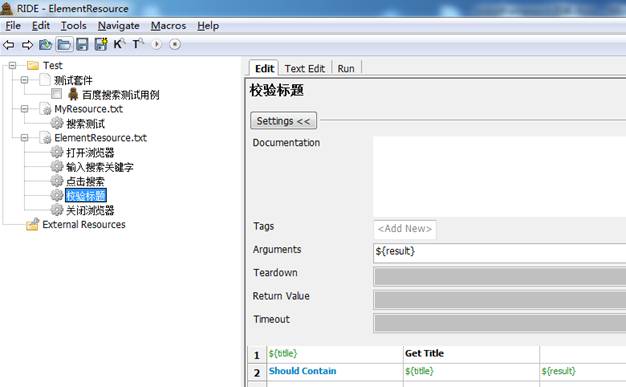
关闭浏览器
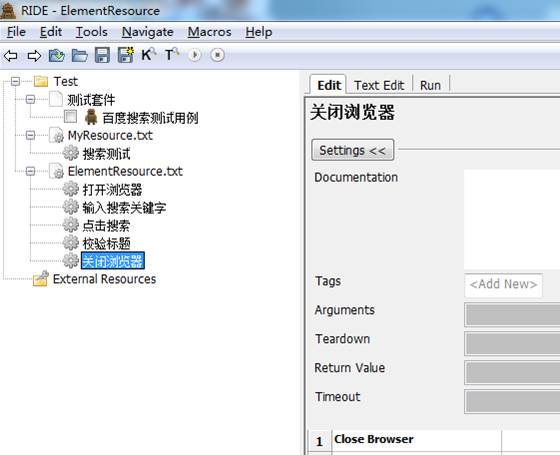
而此时搜索测试页面如下:
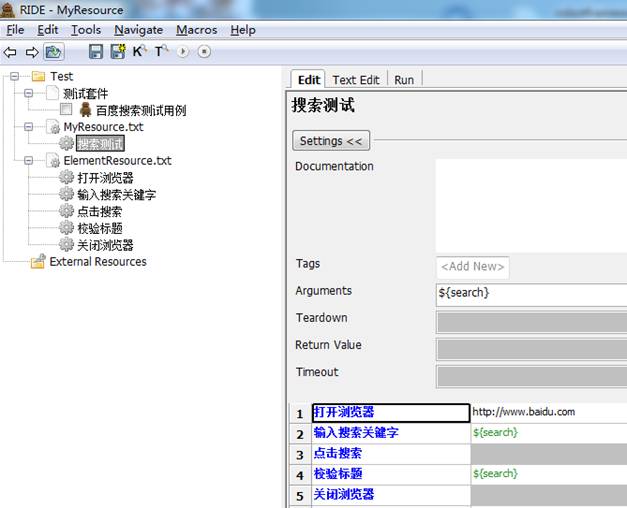
5.4运行测试用例
选中需要运行的用例,点击运行按钮。
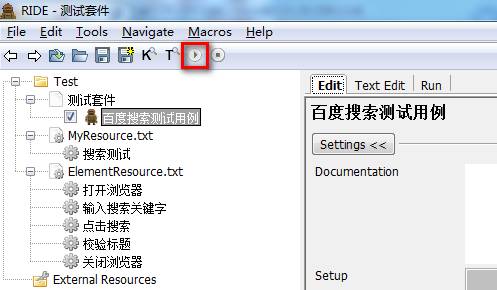
可以在Run区查看到用例执行情况。
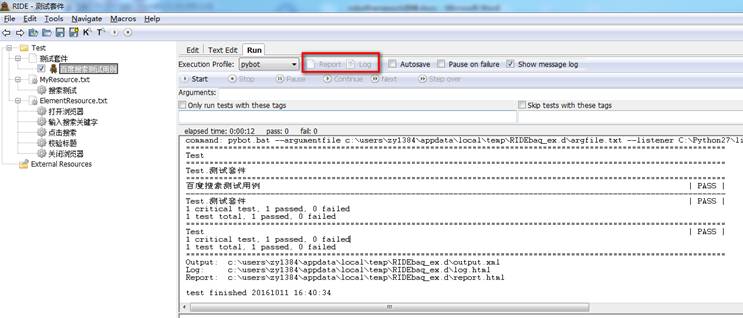
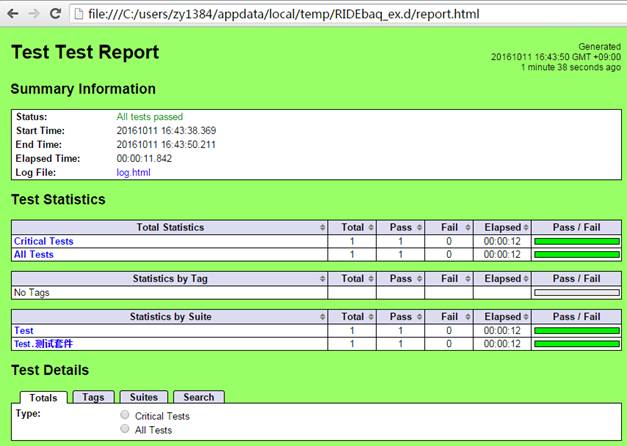
点击Report(或者直接复制下方的url),可以查看到测试报告,绿底表示测试通过。
点击Log(或者直接复制下方的url)。

这篇关于Robot Framework使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








