论文地址:2018_用于音频超分辨率的时频网络
博客作者:凌逆战
博客地址:https://www.cnblogs.com/LXP-Never/p/12345950.html
摘要
音频超分辨率(即带宽扩展)是提高音频信号时域分辨率的一项具有挑战性的任务。最近的一些深度学习方法通过将任务建模为时域或频域的回归问题,取得了令人满意的结果。在本文中,我们提出了一种新的模型体系结构——时频网络(TFNet,Time-Frequency Network),这是一种在时域和频域同时进行监控的深度神经网络。我们提出了一种新的模型体系结构,允许两个域共同优化。结果表明,我们的方法在数量和质量上都优于目前最先进的方法。
索引术语:带宽扩展,音频超分辨率,深度学习
1、引言
超分辨率(SR)是从低分辨率(LR)输入重建高分辨率(HR)数据的任务。这是一个具有挑战性的任务,因为它是ill-posed的性质,特别是当上采样因子很高的时候。通过处理SR问题,我们可以获得对数据先验的理解,并引导相关领域的改进,如压缩和生成建模。
近年来,图像超分辨率算法在计算机视觉领域得到了广泛的关注,并将SR建模为一种深度神经网络回归任务,取得了显著的成功。在这项工作中,我们探索了音频数据的类似SR任务(即学习从LR到HR音频帧的映射)。为了可视化重建,在图1中我们展示了LR输入、HR重建和ground truth的频谱图。
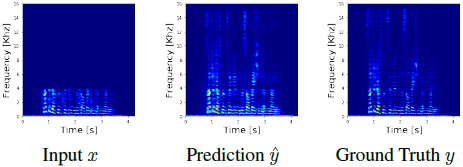
图1:LR输入(频率4kHz以上缺失),HR重构,HR ground truth。我们的方法成功地从LR音频信号中恢复了高频分量。
Li[1]等人提出了一种深度神经网络来学习频谱幅值从LR到HR的映射,完全忽略缺失的高频分量的相位。在[2]中,Kuleshov等人提出了一种深度神经网络来直接在时域中学习LR到HR的映射。虽然这些模型显示了有希望的结果,但每个模型都只在时域或频域工作,并侧重于信号的不同方面。目前也只有这两个人提供了代码。
为了充分利用时域和频域信息,我们提出了时频网络(TFNet),它是一种深度神经网络,可以选择何时将时域和频域信息用于音频SR。
乍一看,在频域和时域建模似乎是一个冗余的表示;从Parseval定理可知,预测误差的L2差异,无论是在频域还是在时域都是完全相同的。然而,从LR到HR在时域或频域的回归解决了一个非常不同的问题。在时域上,它类似于图像的超分辨率任务,将音频块从LR映射到HR。另一方面,频域SR与语意图像修复任务类似[3,4]。给定频谱的低频分量,输出高频分量,如图2所示。因此,为了充分利用这两种方法的优点,我们建议在时域和频域内对音频SR进行联合建模。
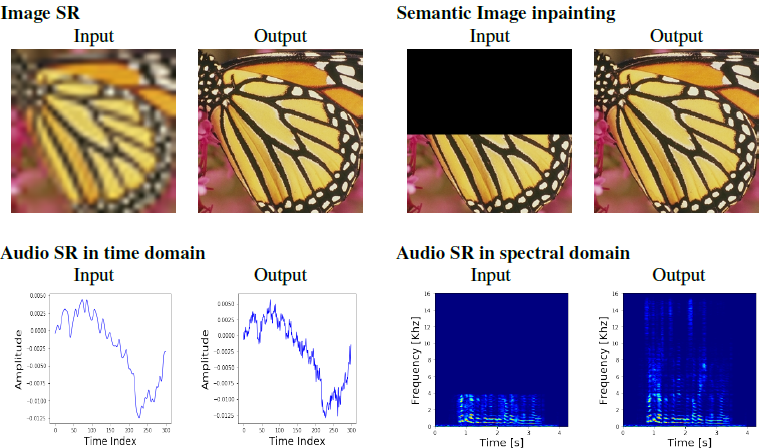
图2:图像SR的输入输出,语义图像修复,音频SR的时域和频域说明。时域中的音频SR类似于图像SR,其中LR输入中缺少“edges边”。另一方面,谱域音频SR可以看作是谱图的图像修复,即给定底层低频“图像”,对剩余图像进行预测。
2、相关工作
频带扩展
语音社区将音频超分辨任务作为带宽扩展进行研究。提出了利用低频[5]估计高频分量的各种方法。如线性映射[6,7]、混合模型[8,9,10]、神经网络[11,12,1,2]。
深度神经网络的单图像超分辨率
深度卷积神经网络(CNNs)是目前单图像超分辨率研究的最新进展。已经提出了许多体系结构[13,14,15]。这些模型都是完全卷积的,并带有早些时候的skip / redisual连接。
深度神经网络的语义图像修复
深度神经网络在语义图像修复任务中也表现出了较强的性能。利用CNNs,[3,4]证明了预测图像中掩蔽区域的可能性。与超级分辨率类似,这些模型也是完全卷积的。从这些模型中获得灵感,我们的深层网络架构也遵循类似的设计原则。
3、方法
我们将音频SR定义为回归任务,即预测HR音频帧,$y\in \mathbb{R}^L$,给定LR音频帧,$x\in \mathbb{R}^{L/R}$,其中$R$是下采样因子。
3.1 时频网络
我们提出时频网络(TFNet),这是一个完全可微的网络,可以端到端的训练。如图3所示,设$\Theta $为模型中的所有参数,我们的模型由一个基于全卷积的编码器-解码器网络$H(x; \Theta )$构成。对于给定的LR输入x,H预测HR音频,重建$\hat{z}$和HR频谱幅度$\hat{m}$。利用我们提出的频谱融合层合成最终的输出。
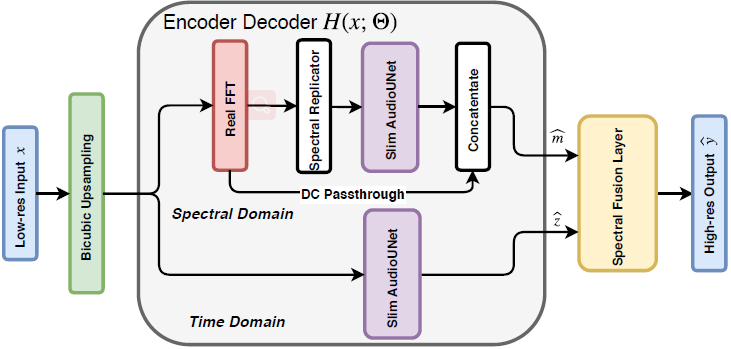
图3:时频网络结构。TFNet同时利用时域和频域来完成音频信号的重构,它包含一个明确建模重构频谱幅值的分支,而其他的分支建模重构时域音频。最后将这两个分支的输出与我们的频谱融合层相结合,合成高分辨率的输出。
频谱融合层
频谱融合层结合$\hat{z}$和$\hat{m}$输出最终的重建$\hat{y}$,如下图所示:
$$\begin{aligned} M=& w \odot|\mathscr{F}(\hat{z})|+(1-w) \odot \hat{m} \\ \hat{y} &=\mathscr{F}^{-1}\left(M e^{j \angle \mathscr{F}(\hat{z})}\right) \end{aligned}$$
其中$\mathscr{F}$表示傅里叶变换,$\odot$是元素的乘法运算,$w$是可训练参数。
这一层是可微的,可以端到端的训练。关键的优点是,该层可强制网络对波形的频谱幅度进行建模,而模型的其余部分可以在时域内建模相位。
我们对网络体系结构的设计是基于这样的观察:卷积层只能捕获局部关系,特别擅长捕获视觉特征。当我们利用短时傅里叶变换对赋值和相位进行可视化处理时,幅值明显的视觉结构,而相位没有,因此,我们只在谱域中对幅值进行建模。
频谱复制器
如前所述,卷积层通常捕获局部关系(即,输入-输出关系的范围受到感受野的限制)。这导致了一个问题,因为我们想要输出的高频分量依赖于输入的低频分量。例如,当向上采样4倍时,接受域至少需要为总频率bin的3/4,这将需要非常大的内核或许多层。为了解决接受域的问题,我们将可用的低频频谱复制到高频频谱中,高频频谱最初都是零,如图4所示。
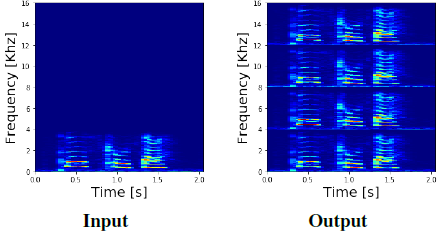
图4:在4x SR任务上的频谱复制层图解。低频分量被复制四次以替换零
损失函数
为了训练我们的网络,我们利用$l_2$重建损失和权重衰减。总的目标函数是最小化下面关于$\Theta $的损失函数
$$公式1:\mathcal{L}=\sum_{(x, y) \in \mathcal{D}}\|y-\hat{y}(x)\|_{2}+\lambda\|\Theta\|_{2}$$
其中$D$是所有(LR,HR)对的训练集,$\lambda $是正则化器的加权超参数,在我们的所有实验中选择为0:0001。
3.2、实现细节
预处理
对于训练,我们进行了沉默过滤以丢弃能量阈值为0.05以下的序列脉冲,计算结果A。我们发现这提高了训练的收敛性,并稳定了梯度。对于测试和评估,我们不过滤沉默。
网络架构
我们的网络由两个具有相似架构的分支组成;时域分支和频域分支。为了公平的比较,我们的网络遵循了AudioUNet[2]的架构设计模式,包括编码器和解码器块。为了保持模型大小大致相同,每个分支中的过滤器数量减半。我们的网络以8192段音频作为输入。
对于频域分支,我们对序列进行离散傅里叶变换(DFT)。由于所有的音频信号都是实数,所以我们抛弃了所有负相位的分量,得到了4097个傅立叶系数。最后,求这些系数的大小。
如前所述,输入的高频分量为零,因此使用频谱复制器,我们用低频分量的副本替换零值。具体来说,对于4x上采样,我们在1025到2048、2049到3072和3073到4096重复第1个分量到第1024个分量。第0个分量(直流分量)直接通过网络,最后融合。
训练细节
我们使用流行的Adam 优化器[16]来训练我们的网络。初始学习速率为$3e^{-5}$,采用多项式学习速率衰减调度,学习速率为0.5。我们所有的模特都经过了50万步的训练。
4、实验
数据集和准备
我们在两个数据集上评估我们的方法:VCTK数据集[17]和Piano数据集[18]。
VCTK数据集包含来自109个以英语为母语的人的语音数据。每个说话人会读出大约400个不同的句子,每个说话人的句子也不同,总共有44个小时的语音数据。
根据之前的工作[2],我们将数据分为88%的培训6%的验证和6%的测试,没有说话人重叠。
对于数据集中的每个文件,我们通过以目标较低采样率的奈奎斯特速率执行带截止频率的低通滤波器,将音频重采样到较低的采样率。然后通过双三次插值将LR序列向上采样到原始速率。为了编制训练(LR, HR)对,我们从重采样信号及其对应的原始信号中提取了8192个重叠度为75%的样本长度子序列。
对于采样速率为16kHz的VCTK数据集,它对应的子序列约为500ms,每个子序列的起始距离为125ms。剩下的50%的序列会被丢弃,因为得到的数据集太大,无法有效地训练。
此外,为了了解模型的性能是否会受到数据多样性的影响,我们建立了一个新的数据集(VCTKs),它只包含说话者VCTK的一个子集。这包括大约30分钟的演讲。音频数据以16kHz的采样率提供。
钢琴数据集包含10小时的贝多芬奏鸣曲,采样率为16kHz。由于音乐的重复性,我们在文件级别上对Piano数据集进行了分割以进行公平的评估。
评估
为了进行评价,我们计算了信噪比(SNR)和对数谱距离(LSD)的相似性度量。
在时域内,信噪比捕获了预测和fround-truth数据之间的加权差。另一方面,LSD在频域[19]捕获预测与fround-truth之间的差异。
$$公式2:\mathrm{LSD}(y, \hat{y})=\frac{10}{L} \sum_{l=1}^{L}\left\|\log _{10} \mathscr{F}\left(y_{l}\right)-\log _{10} \mathscr{F}\left(\hat{y}_{l}\right)\right\|_{2}$$
其中下标$l$表示音频短窗口段的索引。
结果
根据表1中[1,2]的结果,我们将我们的方法与三个不同的基线、一个简单的双三次插值和两个深度网络方法进行了比较。特别地,我们实验了不同的下采样率,从4x开始,在这里质量的下降变得清晰可见。对于VCTK,我们的方法在4倍上采样的情况下比基线方法的信噪比大约高出1.5dB。8倍上采样甚至比基线 6倍上采样结果高1.5dB SNR。在Piano数据集上,我们的方法性能与基线方法相当。需要注意的是,在[2]中的参数数量与我们的模型相同;这进一步证明了我们的model架构在表达上更加有效。
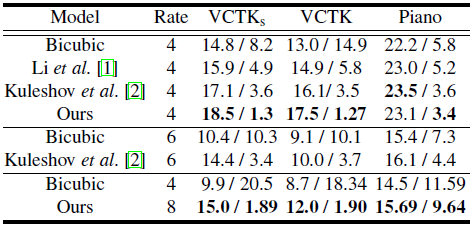
表1:对不同上采样率下的测试集进行定量比较。左/右结果为信噪比/LSD。
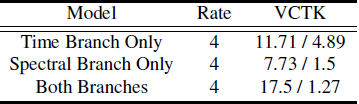
表2:消融研究,评估时域和谱域各分支的性能。左/右结果为信噪比/LSD。
细节分析
此外,为了确认我们的网络架构同时利用了时域和频域,我们进行了消融(ablation)研究。我们通过移除时域或频域分支来评估模型性能,如表2所示。对于谱支,我们假设重构时高频分量为零相位。
5、结论与未来工作
本文提出了一种时频网络(TFNet),这是一种深度卷积神经网络,利用时域和频域来实现音频的超分辨。与现有方法相比,我们的新型频谱复制和融合层具有更好的性能。最后,TFNet已经证明了具有冗余表示有助于对音频信号进行建模。我们认为该方法的经验结果是有趣的和有前途的,这为进一步的理论和数值分析提供了依据。此外,我们希望将此观察推广到其他音频任务,例如音频生成,目前最先进的WaveNet[20]是一种时域方法。
文献
[1] Kehuang Li, Zhen Huang, Yong Xu, and Chin-Hui Lee,“Dnn-based speech bandwidth expansion and its application to adding high-frequency missing features for automatic speech recognition of narrowband speech,” in Proc. INTERSPEECH, 2015.
[2] Volodymyr Kuleshov, S Zayd Enam, and Stefano Ermon,“Audio super-resolution using neural networks,”, 2017.
[3] Deepak Pathak, Philipp Kr¨ahenb¨uhl, Jeff Donahue,Trevor Darrell, and Alexei Efros, “Context encoders:Feature learning by inpainting,” in Computer Vision and Pattern Recognition (CVPR), 2016.
[4] Raymond A. Yeh, Chen Chen, Teck Yian Lim,Schwing Alexander G., Mark Hasegawa-Johnson, and Minh N. Do, “Semantic image inpainting with deep generative models,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, equal contribution.
[5] Bernd Iser and Gerhard Schmidt, “Bandwidth extension of telephony speech,” Speech and Audio Processing in Adverse Environments, pp. 135–184, 2008.
[6] Yoshihisa Nakatoh, Mineo Tsushima, and Takeshi Norimatsu,“Generation of broadband speech from narrowband speech using piecewise linear mapping,” in Fifth European Conference on Speech Communication and Technology, 1997.
[7] Yoshihisa Nakatoh, Mineo Tsushima, and Takeshi Norimatsu,“Generation of broadband speech from narrowband speech based on linear mapping,” Electronics and Communications in Japan (Part II: Electronics), vol. 85,no. 8, pp. 44–53, 2002.
[8] Geun-Bae Song and Pavel Martynovich, “A study of hmm-based bandwidth extension of speech signals,” Signal Processing, vol. 89, no. 10, pp. 2036–2044, 2009.
[9] Hyunson Seo, Hong-Goo Kang, and Frank Soong, “A maximum a posterior-based reconstruction approach to speech bandwidth expansion in noise,” in Acoustics,Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE, 2014, pp. 6087–6091.
[10] Saeed Vaseghi, Esfandiar Zavarehei, and Qin Yan, “Speech bandwidth extension: Extrapolations of spectral envelop and harmonicity quality of excitation,” in Acoustics, Speech and Signal Processing, 2006. ICASSP 2006 Proceedings. 2006 IEEE International Conference on. IEEE, 2006, vol. 3, pp. III–III.
[11] Juho Kontio, Laura Laaksonen, and Paavo Alku, “Neural network-based artificial bandwidth expansion of speech,” IEEE transactions on audio, speech, and language processing, vol. 15, no. 3, pp. 873–881, 2007.
[12] Bernd Iser and Gerhard Schmidt, “Neural networks versus codebooks in an application for bandwidth extension of speech signals,” in Eighth European Conference on Speech Communication and Technology, 2003.
[13] Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang, “Image super-resolution using deep convolutional networks,” IEEE Trans. Pattern Anal. Mach.Intell., vol. 38, no. 2, pp. 295–307, Feb. 2016.
[14] Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee, “Accurate image super-resolution using very deep convolutional networks,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR Oral), June 2016.
[15] Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang, “Deep laplacian pyramid networks for fast and accurate super-resolution,” in IEEE Conference on Computer Vision and Pattern Recognition,2017.
[16] Diederik Kingma and Jimmy Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
[17] Junichi Yamagishi, “English multi-speaker corpus for cstr voice cloning toolkit,” http://homepages.inf.ed.ac.uk/jyamagis/page3/page58/page58.html, 2012.
[18] Soroush Mehri, Kundan Kumar, Ishaan Gulrajani,Rithesh Kumar, Shubham Jain, Jose Sotelo, Aaron Courville, and Yoshua Bengio, “Samplernn: An unconditional end-to-end neural audio generation model,”2016, cite arxiv:1612.07837.
[19] Augustine Gray and John Markel, “Distance measures for speech processing,” IEEE Transactions on Acoustics,Speech, and Signal Processing, vol. 24, no. 5, pp.380–391, 1976.
[20] Aron van den Oord, Sander Dieleman, Heiga Zen,Karen Simonyan, Oriol Vinyals, Alexander Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu,“Wavenet: A generative model for raw audio,” in Arxiv,2016.


![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)



