本文主要是介绍了解一波经典的 I/O 模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近读了波网络 I/O 相关的文章,做下总结、摘录。(未完)
经典 I/O 模型
- {% checkbox red checked, 阻塞式 I/O(blocking I/O) %}
- {% checkbox red checked, 非阻塞式 I/O(non-blocking I/O) %}
- {% checkbox red, I/O 多路复用(I/O multiplexing) %}
- {% checkbox cyan , 信号驱动式 I/O(signal driven I/O) %}
- {% checkbox cyan , 异步 I/O(asynchronous I/O) %}
阻塞式 I/O 模型
对于阻塞式 I/O,以套接字(Socket)的输入操作为例。
- 1、首先应用进程发起 I/O 系统调用后,应用进程阻塞,转到内核空间处理。
- 2、之后,内核开始等待数据,等待数据到达之后,将内核中的数据拷贝到用户的缓冲区中,整个 I/O 处理完毕后返回进程。最后应用进程解除阻塞状态,处理数据。
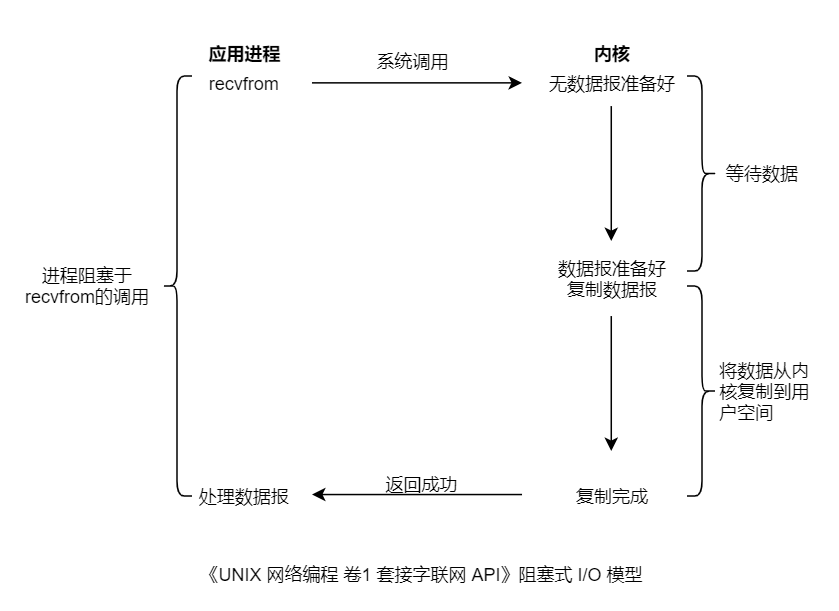
上图以 UDP 的 Socket 调用为例,进程调用 recvfrom 后,系统调用直到数据报到达且被复制到用户空间中或发生错误才返回。进程从调用开始到它返回的整段时间内是被阻塞的。recvfrom 成功返回后,应用进程开始处理数据报。
默认情形,Linux/Unix 的所有 Socket 是阻塞的。
附:基于 UDP 协议的 Socket 程序函数调用过程图
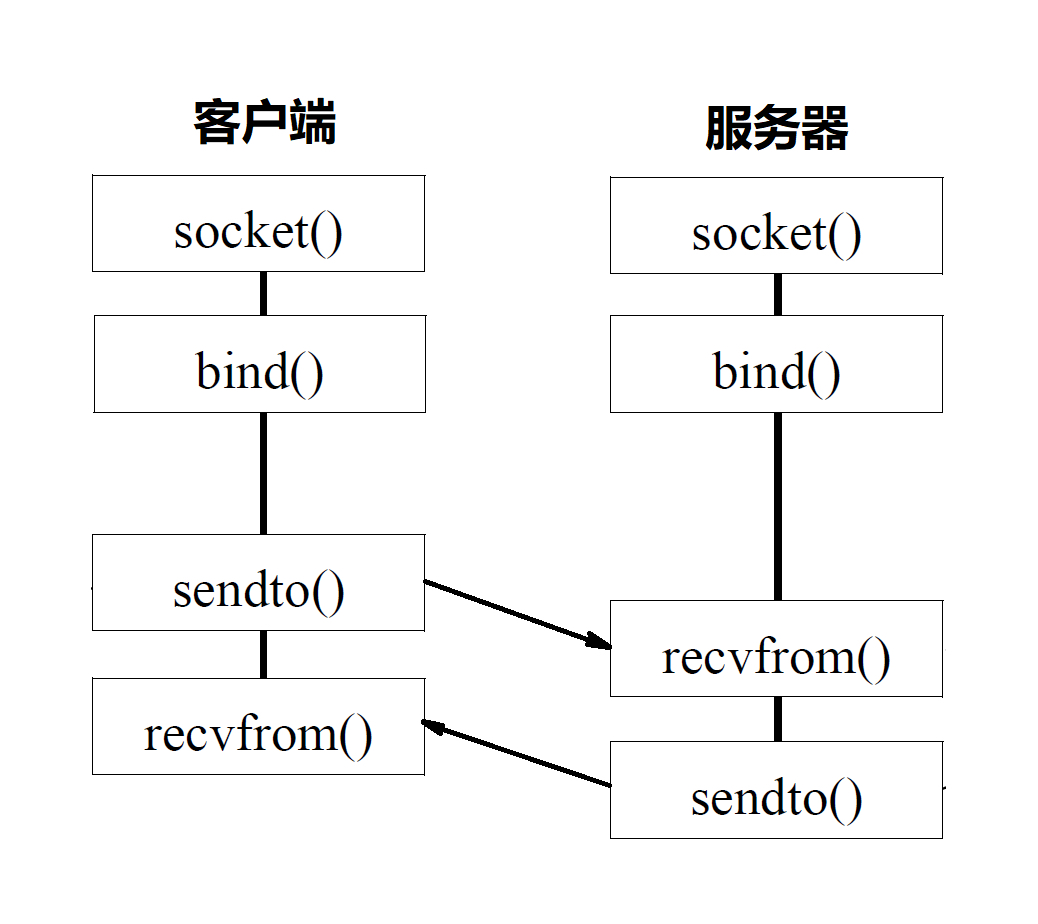
一般情况下,服务端需要管理多个客户端连接(处理并发连接),而 recvfrom 只能监视单个 Socket。上图的阻塞式 I/O 模型表示的是一对一沟通的情形,使用多线程/进程 + 阻塞式 I/O 我们可以管理多个 Socket ,实现一对多服务。
非阻塞式 I/O 模型
在类 Unix 系统下,可以把一个 Socket 设置成非阻塞的。这意味着内核在数据报没有准备好时不会阻塞应用进程(睡眠态),而是返回一个错误。
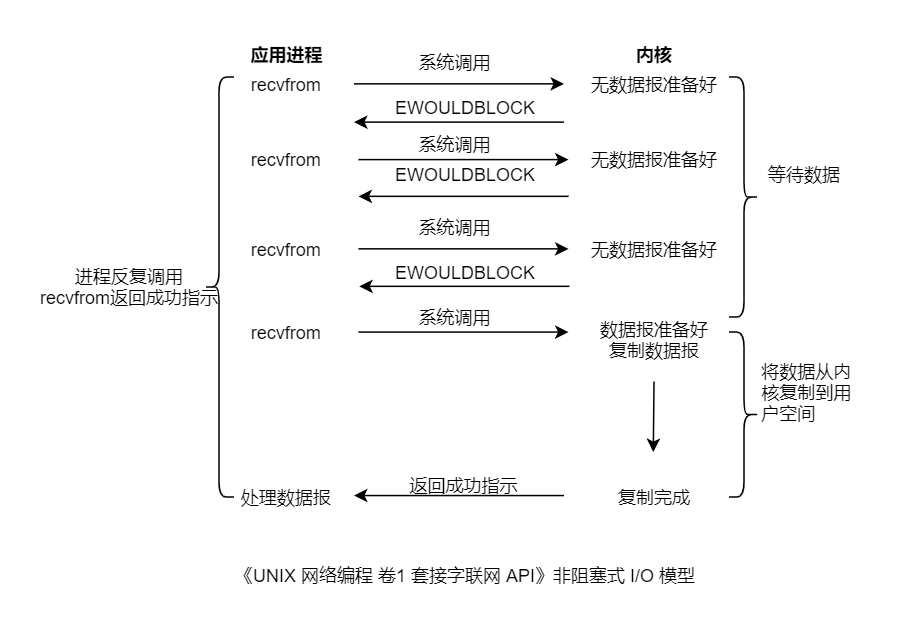
上图以 UDP 的 Socket 调用为例,进程反复调用 recvfrom(polling,轮询),无数据返回 EWOULDBLOCK 错误,直至数据报准备好。
问题:单进程处理数据报,不同于阻塞I/O,由于需要反复 polling,非阻塞 I/O 会耗费大量的 CPU 资源,进程阻塞不耗费 CPU 资源。如果耍上了多进程,那耗费,是不可承受的。
关于阻塞的原理,这篇文章有简单介绍✔🔗。
I/O 多路复用模型
什么是多路复用?多路指的是多个通道,一般就是多个网络连接的 I/O;复用指的是多个通道复用在一个复用器上。
引入多路复用机制的一个目的是为了处理多个网络连接 I/O。
I/O多路复用方法的演进历程:select 模型-> poll 模型-> epoll 模型
select 模型
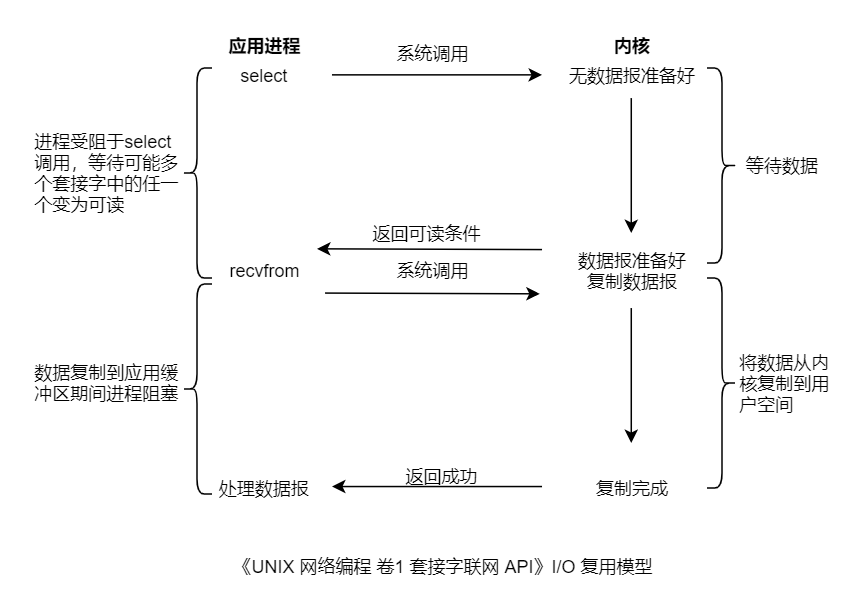
上图所示的整个用户进程一般一直是被阻塞的(blocking),即被 select(复用器) 所阻塞,多个 Socket 被注册在 select 中。进程阻塞于 select 调用,等待数据报套接字变为可读,一但 select 返回套接字可读,系统调用 recvfrom 把所读数据报复制到应用进程缓冲区。
{% note blue, 问题来了?为了处理多个网络连接 I/O,我们也可以通过多线程/进程的方式实现,多路复用的优势何在?这里的多路复用模型似乎比阻塞式 I/O 模型更为复杂,但它最大的优势在于用户可以在一个进程/线程内同时处理多个 socket 的 IO 请求。用户可以注册多个 socket,然后不断地调用 select 读取被激活的 socket,即可达到在同一个线程内同时处理多个 IO 请求的目的。(select 可接受的 socket 描述符数会有一定限制) %}
{% note red, 我们知道,操作系统多个进程/线程的开销维护还是蛮大的。对于高并发场景,如果一台机器要维护 1 万个连接(C10K问题),使用多线程/进程的方式处理,操作系统是无法承受的。如果维持 1 亿用户在线需要 10 万台服务器,成本那是相当的高。 %}
{% note yellow, $ 服务端单机最大 TCP 连接数=客户端 IP 数×客户端端口数 $,对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方。这只是理论上限,每个 TCP 连接的建立会受制于操作系统内存等因素的影响。%}
epoll 模型
新模型的出现肯定是为了解决旧模型的问题,那么 select 模型有什么问题?每次 Socket 所在的文件描述符集合中有 Socket 发生变化的时候,select 都需要通过轮询的方式去检查,而 epoll 引入了 CallBack(回调)机制,当某个文件描述符发送变化的时候,主动通知。随着监听的 Socket 数据增加的时候,效率相比于 select 的轮询快多了。
了解 epoll 的本质 -> 如果这篇文章说不清epoll的本质,那就过来掐死我吧! (2)
参考
- 《UNIX网络编程 卷1:套接字联网API》
- 趣谈网络协议
- RPC实战与核心原理
- 如果这篇文章说不清epoll的本质,那就过来掐死我吧!
- 5种网络IO模型(有图,很清楚)
- 《Nginx高性能Web服务器详解》
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
这篇关于了解一波经典的 I/O 模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







