本文主要是介绍TrOCR—基于Transformer的OCR入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导 读
本文主要介绍TrOCR:基于Transformer的OCR入门。
背景介绍
多年来,光学字符识别 (OCR) 出现了多项创新。它对零售、医疗保健、银行和许多其他行业的影响是巨大的。尽管有着悠久的历史和多种最先进的模型,研究人员仍在不断创新。与深度学习的许多其他领域一样,OCR 也看到了变压器神经网络的重要性和影响。如今,我们拥有像TrOCR(Transformer OCR)这样的模型,它在准确性方面真正超越了以前的技术。

在本文中,我们将介绍 TrOCR 并重点关注四个主题:
-
-
TrOCR的架构是怎样的?
-
TrOCR 系列包括哪些型号?
-
TrOCR 模型是如何预训练的?
-
如何使用 TrOCR 和 Hugging Face 进行推理?
-
如果您经常使用 OCR,本文将帮助您在自己的项目中轻松使用 TrOCR。
TrOCR架构
TrOCR 由 Li 等人提出。在论文 TrOCR:基于 Transformer 的光学字符识别与预训练模型中。
作者提出了一种摆脱OCR传统CNN和 RNN 架构的方法。相反,他们使用视觉和语言转换器模型来构建 TrOCR 架构。
TrOCR 模型由两个阶段组成:
-
-
编码器阶段由预训练的视觉变换器模型组成。
-
解码器阶段由预训练的语言转换器模型组成。
-
由于其高效的预训练,基于 Transformer 的模型在下游任务上表现非常出色。为此,作者选择 DeIT 作为视觉 Transformer 模型。对于解码器阶段,他们根据 TrOCR 变体选择了 RoBERTa 或 UniLM 模型。
下图显示了使用 TrOCR 的简单 OCR 管道。
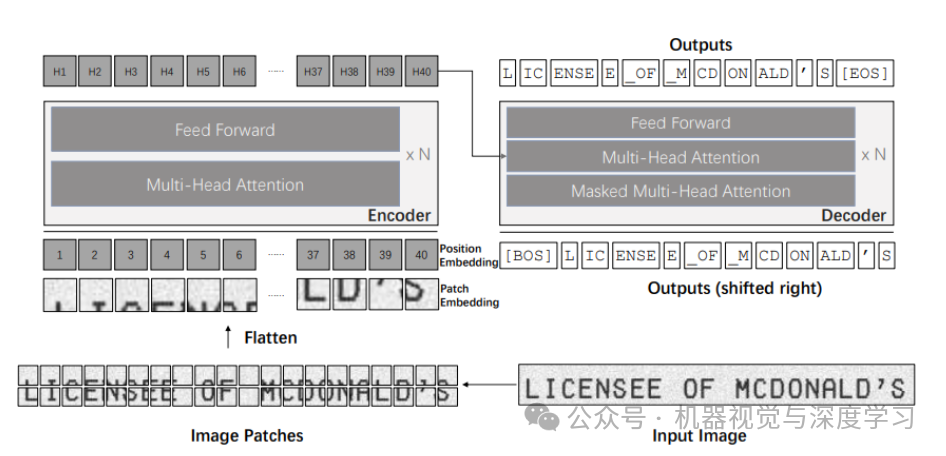
在上图中,左侧块显示视觉变换器编码器,右侧块显示语言变换器解码器。以下是 TrOCR 推理阶段的简单分解:
-
-
首先,我们将图像输入到 TrOCR 模型,该模型通过图像编码器。
-
图像被分解成小块,然后通过多头注意力块。前馈块产生图像嵌入。
-
然后这些嵌入进入语言转换器模型。
-
语言转换器模型的解码器部分产生编码输出。
-
最后,我们对编码输出进行解码以获得图像中的文本。
-
需要注意的一件事是,在进入视觉转换器模型之前,图像的大小已调整为 384×384 分辨率。这是因为 DeIT 模型期望图像具有特定的尺寸。
当然,多头注意力、编码器和解码器涉及多个组件。但是,这些超出了本文的范围。
TrOCR系列模型
TrOCR 模型系列包括多个预训练和微调的模型。
TrOCR 预训练模型
TrOCR 系列中的预训练模型称为第一阶段模型。这些模型是根据大规模综合生成的数据进行训练的。该数据集包括数亿张打印文本行的图像。
官方存储库包括预训练阶段的三个尺度的模型。它们是(参数数量不断增加):
-
-
TrOCR-Small-Stage1
-
TrOCR-Base-Stage1
-
TrOCR-Large-Stage1
-
毫无疑问,Large 模型表现最好,但也是最慢的。
TrOCR 微调模型
预训练阶段结束后,模型在 IAM 手写文本图像和 SROIE 打印收据数据集上进行了微调。
IAM 手写数据集包含手写文本的图像。微调该数据集使模型比其他模型更好地识别手写文本。
同样,SROIE 数据集由数千个收据图像样本组成。在此数据集上微调的模型在识别印刷文本方面表现非常好。
就像预训练阶段模型一样,手写模型和打印模型也分别包含三个尺度:
-
-
TrOCR-Small-IAM
-
TrOCR-Base-IAM
-
TrOCR-Large-IAM
-
TrOCR-Small-SROIE
-
TrOCR-Base-SROIE
-
TrOCR-Large-SROIE
-
TrOCR 的理论和架构讨论到此结束。我们现在将继续使用 TrOCR 进行推理。
使用TrOCR模型推理
Hugging Face 托管从预训练到微调阶段的所有 TrOCR 模型。
我们将使用两种模型,一种是手写的微调模型,一种是打印的微调模型来运行推理实验。
在《Hugging Face》中,模型的命名遵循trocr-<model_scale>-<training_stage>惯例。
例如,在 IAM 手写数据集上训练的 TrOCR 小模型称为trocr-small-handwritten。
接下来,我们将使用trocr-small-printed和trocr-base-handwritten模型进行推理。
以下部分中介绍的代码位于 Jupyter Notebook 中。
安装要求、导入和设置计算设备
要使用 Hugging Face 和 TrOCR 进行推理,我们需要安装两个必需的库:Hugging Face transformers、sentencepiecetokenizer 。
!pip install -q transformers!pip install -q -U sentencepiece
导入需要的包:
from transformers import TrOCRProcessor, VisionEncoderDecoderModelfrom PIL import Imagefrom tqdm.auto import tqdmfrom urllib.request import urlretrievefrom zipfile import ZipFileimport numpy as npimport matplotlib.pyplot as pltimport torchimport osimport glob
综上所述,我们需要下载urllib并zipfile提取推理数据。
前向传递将使用 GPU 或 CPU 设备,具体取决于可用性。
device = torch.device('cuda:0' if torch.cuda.is_available else 'cpu')辅助函数
以下代码行包含一个用于下载和提取数据集的简单函数。
def download_and_unzip(url, save_path):print(f"Downloading and extracting assets....", end="")# Downloading zip file using urllib package.urlretrieve(url, save_path)try:# Extracting zip file using the zipfile package.with ZipFile(save_path) as z:# Extract ZIP file contents in the same directory.z.extractall(os.path.split(save_path)[0])print("Done")except Exception as e:print("\nInvalid file.", e)URL = r"https://www.dropbox.com/scl/fi/jz74me0vc118akmv5nuzy/images.zip?rlkey=54flzvhh9xxh45czb1c8n3fp3&dl=1"asset_zip_path = os.path.join(os.getcwd(), "images.zip")# Download if assest ZIP does not exists.if not os.path.exists(asset_zip_path):download_and_unzip(URL, asset_zip_path)
上面的代码将下载包括以下内容的图像:
-
-
从旧报纸上打印文本图像,以使用打印模型进行推理。
-
手写文本图像,使用手写文本微调模型进行推理。
-
野外弯曲文本图像以测试 TrOCR 模型的局限性。
-
接下来,我们有一个简单的函数来读取 PIL 格式的图像并将其返回以供下一个处理阶段使用。
def read_image(image_path):""":param image_path: String, path to the input image.Returns:image: PIL Image."""image = Image.open(image_path).convert('RGB')return image
该read_image()函数只需要一个图像路径并以 RGB 颜色格式返回它。
我们还编写一个辅助函数来执行 OCR 管道。
def ocr(image, processor, model):""":param image: PIL Image.:param processor: Huggingface OCR processor.:param model: Huggingface OCR model.Returns:generated_text: the OCR'd text string."""# We can directly perform OCR on cropped images.pixel_values = processor(image, return_tensors='pt').pixel_values.to(device)generated_ids = model.generate(pixel_values)generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]return generated_text
我们需要在这里关注一些事情。这些ocr()函数需要三个参数:
-
-
image:这是RGB颜色格式的PIL图像。
-
processor:Hugging Face OCR 管道需要 OCR 处理器首先将图像转换为适当的格式。我们将在初始化模型时详细讨论这一点。
-
model:这是 Hugging Face OCR 模型,它接受预处理图像并给出编码输出。
-
在 return 语句之前,您可能会注意到batch_decode()处理器的功能。这实质上是将模型生成的编码 ID 转换为输出文本。表示skip_special_tokens=True我们不希望像句子结尾或句子开头这样的特殊标记成为输出的一部分。
我们的最终辅助函数对新图像进行推理。它结合了前面的功能并在输出单元中显示图像。
def eval_new_data(data_path=None, num_samples=4, model=None):image_paths = glob.glob(data_path)for i, image_path in tqdm(enumerate(image_paths), total=len(image_paths)):if i == num_samples:breakimage = read_image(image_path)text = ocr(image, processor, model)plt.figure(figsize=(7, 4))plt.imshow(image)plt.title(text)plt.axis('off')plt.show()
该eval_new_data()函数接受目录路径、我们要进行推理的样本数量以及模型作为参数。
对印刷文本的推断
让我们加载 TrOCR 处理器和打印文本模型。
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-small-printed')model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-small-printed').to(device)
要加载TrOCR 处理器,我们需要使用 TrOCRProcessor 类的 from_pretrained 模块。这接受 HuggingFace 存储库的字符串路径,其中包含特定模型。
那么,TrOCR 处理器有什么作用呢?
请记住,TrOCR 模型是一个神经网络,无法直接处理图像。在此之前,我们需要将图像处理成适当的格式。TrOCR 处理器首先将图像大小调整为 384×384 分辨率。然后它将图像转换为归一化张量格式,然后进入模型进行推理。我们还可以指定张量的格式。例如,在我们的例子中,我们将张量转换为 pt 格式,这表示 PyToch 张量。如果我们使用 TensorFlow 框架,我们还可以通过提供 tf 来获取 TensorFlow 格式的张量。
同样,我们使用该类VisionEncoderDecoderModel来加载预训练模型。在上面的代码块中,我们加载trocr-small-printed模型,并在加载后将模型传输到设备。接下来,我们调用该eval_new_data()函数开始对从旧报纸上裁剪的图像进行推理。
eval_new_data(data_path=os.path.join('images', 'newspaper', '*'),num_samples=2,model=model)
运行上述代码块会产生以下输出。运行上述代码块会产生以下输出。

图像顶部的文本显示模型的输出。即使图像模糊不清,该模型的性能也非常好。在第一张图像中,模型可以预测所有逗号、句号,甚至连字符。
手写文本推理
对于手写文本推理,我们将使用基本模型(大于小模型)。我们先加载手写的TrOCR处理器和模型。
processor = TrOCRProcessor.from_pretrained('microsoft/trocr-base-handwritten')model = VisionEncoderDecoderModel.from_pretrained('microsoft/trocr-base-handwritten').to(device)
我们的方法遵循印刷文本模型的方法;我们只需更改存储库路径即可访问适当的模型。
为了运行推理,我们需要更改数据目录路径。
eval_new_data(data_path=os.path.join('images', 'handwritten', '*'),num_samples=2,model=model)

这是一个很好的例子,展示了 TrOCR 在手写文本上的表现如何。即使是跑步的手,它也可以正确检测所有字符。

即使使用不同类型的写作风格,模型性能也不会恶化。基于 Transformer 的视觉和语言模型的结合在这里大放异彩。
测试 TrOCR 的极限
尽管 TrOCR 令人印象深刻,但它并不是在所有类型的图像上都表现良好。例如,小型模型很难处理包含弯曲文本或来自广告牌、横幅和服装等自然场景的文本的图像。以下是一些例子。

很明显,该模型无法理解和提取单词STATES,并且预测>如上图所示
这是另一个例子。

在这种情况下,模型可以预测一个单词,但错误。
提高 TrOCR 性能
在上一节中,我们看到 TrOCR 模型在来自野外的图像上可能表现不佳。这些限制来自于视觉转换器和语言转换器模型的能力。需要一个能够看到弯曲文本的视觉转换器和一个能够理解此类文本中不同标记的语言转换器。
最好的方法是在弯曲文本数据集上微调 TrOCR 模型。为了提出解决方案,我们将在下一篇文章中在SCUT-CTW1500数据集上训练 TrOCR 模型。敬请关注!
结论
OCR 自从诞生以来,架构简单,已经取得了长足的进步。如今,TrOCR 为该领域带来了新的可能性。我们首先介绍了 TrOCR,并深入研究了它的架构。接下来,我们介绍了不同的 TrOCR 模型及其训练策略。我们通过推理和分析结果完成了这篇文章。
一个简单而有效的应用程序可以将旧文章和报纸数字化,这些文章和报纸很难手动阅读。
然而,TrOCR 在处理弯曲文本和自然场景中的文本时也有其局限性。我们将在下一篇文章中深入探讨这一点,在弯曲文本数据集上微调 TrOCR 模型并解锁新功能。
这篇关于TrOCR—基于Transformer的OCR入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









