本文主要是介绍Automatic Prompt Engineering,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
让大模型自己生成prompt,生成提示(prompt)存在两种不同的操作方式。第一种方式是在文本空间中进行,这种提示以离散的文本形式存在。第二种方式是将提示抽象成一个向量,在特征空间中进行操作,这种提示是抽象的、连续的。
APE
论文地址:https://arxiv.org/abs/2211.01910
候选prompt自动生成
简单来说就是给答案,让LLM去反推prompt长什么样。典型例子如下:
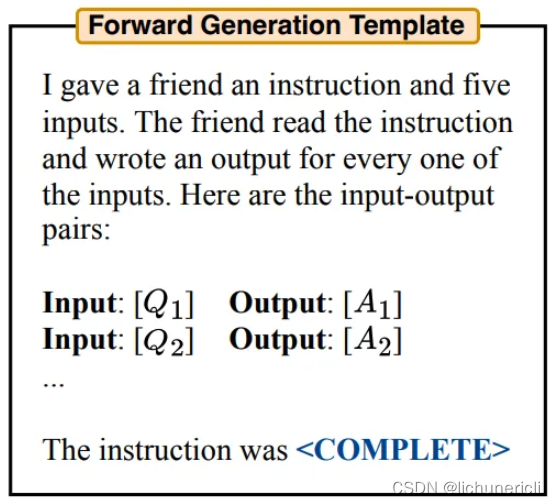
由于LLM大多采用decoder-only结构,所以把需要生成的内容放在最后肯定是最合理的,作者管这种生成方法叫forward generation template。这个template看起来是作者自己设计的,这个template只是一个candidate生成器,评分的时候用的是生成的candidate,和这儿的template无关。
相应的,另一种叫reverse generation template,就是把需要生成的prompt放到文章中的任意位置。
最后一种是根据task不同来制定相应的模板,比如有的task就固定是某种问答结构,这时候你需要和task align一下。
所以这样我们就完成了prompt的自动生成。这里的prompt可以生成很多次(采样),从而生成一个候选集。
评估prompt分数
生成完了候选prompt,接下来就需要想个方法评价哪个prompt比较好。
我们需要先从训练集里取一个子集(就是取一些有gt的训练数据),然后把上一步生成的prompt丢进去。由于我们是有gt的,所以可以比对模型生成gt的概率,生成gt的概率越大说明prompt越好,从某种程度上说和PPL是差不多的东西。
重新采样
经过上述评估之后我们可以留下那些评分高的prompt(由你自己设置top k%),然后把这些好的prompt再送进LLM,让它生成意思相近的prompt,这样相当于再次扩充了候选集,之后可以再进行一轮评估。如此反复迭代即可。

APE针对的场景主要是那种短prompt+固定小任务。比如说我固定了我的任务是“找反义词”,那么我只需要用一些数据去找prompt,这个prompt固定下来之后就不用动了。
OPRO
论文地址:https://arxiv.org/pdf/2309.03409.pdf

在OPRO框架中,有两个主要的大型语言模型(LLM):一个担任评分者(scorer),负责对提示进行评分;另一个则作为优化器(optimizer),根据给定的提示模板来生成新的提示。
首先,我们向优化器提供一个问题描述(用紫色字体表示,如“做数学题”),以及一些已经过评分的提示和它们的分数(用蓝色字体表示,即这些提示已经被评分者评估过,以判断其准确性)。此外,还会提供一些额外的指令(用橙色字体表示)。
接下来,优化器的任务是根据问题描述和已评分的提示,生成一些新的提示。这些新生成的提示应当旨在获得尽可能高的分数。一旦生成了新的提示并获得了它们的分数,我们就会将这些新的提示-分数对加入到之前的蓝色字体部分。如果存在长度限制,我们可能会移除一些分数较低的提示-分数对,以保持提示集的精简和高效。
INSTINCT
如何给ChatGPT正确的prompt?
在强化学习中,我们面临着exploration-exploitation dilemma。想象一下,你想要出售一台二手电脑,你去了市场,第一个人出价50元,你可以选择立即卖给他(exploitation利用),但如果你认为价格不够理想,你可以选择继续寻找下一个买家(exploration探索)。然而,一旦你决定继续寻找,你就不能回头了。下一个买家的出价可能低于50元,也可能高于50元,这就是探索与利用之间的dilemma两难选择,也被称为bandit问题。通过bandit算法,你可以做出“某种选择”。
这个例子虽然简单,但在实际的强化学习场景中,搜索空间可能非常庞大(比如你有100件商品要卖,每件商品都有100个潜在的买家),在这种情况下,遍历整个搜索空间是不切实际的。为了克服这个难题,研究者们提出了一系列专门的算法,例如INSTINCT中采用的NeuralUCB算法,它就是一种bandit问题的算法。
迭代流程


INSTINCT的何改
INSTINCT的改进主要体现在两个方面:首先是提示生成的方式,其次是迭代逻辑的优化。
在提示生成方面,APE采用的传统方法是给定一个模板后生成候选提示;OPRO的提示生成方式本质上相似,但采用了更先进的生成技术(APE更像是随机抽样,而OPRO则通过不断更新条件来进行抽样)。INSTINCT则采用了全新的方法,它通过在隐空间中生成软提示(soft prompt)来得到所需的提示。这种方法的巧妙之处在于,尽管最终得到的提示是离散的,但在操作过程中却是在连续的提示空间中进行,这使得许多优化变得可能。
在迭代逻辑方面,APE的方法相对简单,它直接利用大型语言模型(LLM)根据现有提示生成语义相似的提示,而且这一步骤是可选的。OPRO的迭代方法更为先进,它提供了大量示例和评分;但是,将LLM作为优化器的方法似乎缺乏逻辑依据。
INSTINCT的迭代逻辑则更加现代化,它采用了NeuralUCB算法来迭代优化软提示,从而控制真实提示的生成。换句话说,在第一步训练的评分网络中,实际上蕴含了判断“哪个提示更好”的知识,然后通过NeuralUCB算法利用这些知识寻找“可能更好的提示”。如果找到了更好的提示,那自然是最理想的结果;即使没有找到,这也相当于对训练集进行了一次采样。
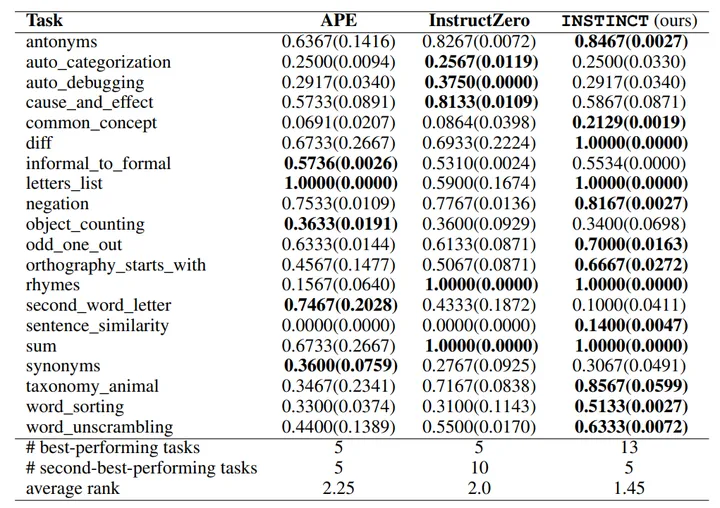
总的来说,INSTINCT的方法在技术上比前两者更为优雅,而且在结果上也表现得更好。
这篇关于Automatic Prompt Engineering的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







