本文主要是介绍2020年黑龙江省水稻种植分布数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
黑龙江省,位于中国最东北部,是我国位置最北、最东,纬度最高,经度最东的省份,气候为温带大陆性季风气候。黑龙江省土地总面积为47.3万平方公里(含加格达奇和松岭区),占全国土地总面积的4.9%,农用地面积3950.2万公顷,占全省土地总面积的83.5%。全省耕地面积15940850.84公顷,占全省土地总面积的33.87%,全省人均耕地面积0.416公顷(合6.24亩/人),高于全国人均耕地水平。主产农作物有春小麦、大豆、稻谷、玉米、甜菜等。
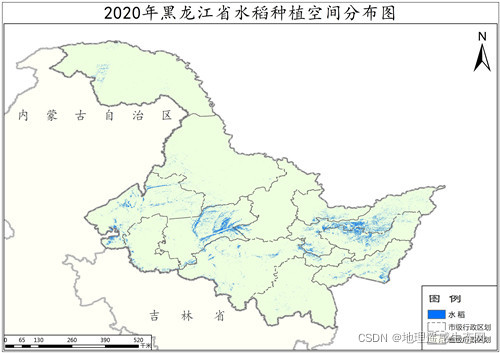
2020年黑龙江省水稻种植分布数据,描述了黑龙江省全省范围内2020年水稻种植的空间分布。通过对水稻分布的统计计算,可以得出黑龙江省2020年水稻的播种面积。该数据为栅格图像数据,数据格式为TIFF格式,空间分辨率为10米,数学基础采用2000国家大地坐标系(CGCS2000)及Albers投影。
2020年黑龙江省水稻种植分布数据的生产是遵循了农业遥感的基本原理,地理遥感生态网依据黑龙江省水稻播种及生长规律制定像素分类策略,利用国内外中分辨率卫星影像,由计算机智能算法提取得出。该数据产品已通过抽样检查验证,数据的像素类别精度为85%(±2%)。
地理遥感生态网平台主要由土地利用遥感监测数据、行政区划边界数据(行政村边界、乡镇街道边界、省市县边界)、气象数据(降雨量、气温、蒸散量、辐射、湿度、日照时数、风速、水汽压数据)、水文站点数据(径流量数据)、遥感数据(npp净初级生产力数据数据、NDVI数据、LAI叶面积指数、GPP初级生产力数据、地表温度LST数据、高精度遥感影像等)、土壤数据(土壤类型、土壤质地、土壤有机质、土壤PH值、土壤质地、土壤侵蚀、土壤NPK、土壤厚度土、土壤重金属含量分布、土壤含水量等)、POI兴趣点数据(餐饮服务、道路附属设施、地名地址信息、风景名胜、公共设施、公司企业、购物服务、交通设施服务、金融保险服务、科教文化服务、摩托车服务、汽车服务、汽车维修、汽车销售、商务住宅、生活服务、事件活动、体育休闲服务、通行设施、医疗保健服务、政府机构及社会团体、住宿服务等)、全国作物类型分布数据(大豆、玉米、水稻、甘蔗、小麦空间分布数据等)、生态系统服务空间数据集、中国湿地沼泽分类数据集、城市空气质量监测数据、中国水系流域空间分布数据集、中国道路空间分布数据、中国陆地生态系统类型分布数据、社会经济统计年鉴数据、中国GDP空间分布数据集、中国人口空间分布数据集、城市建筑轮廓空间分布数据、全国地质灾害空间分布数据(崩塌、塌陷、泥石流、地面沉降、地裂缝、滑坡、斜坡、地震等)、地质岩性分布图、地形地貌数字高程DEM数据(地貌类型矢量数据、12.5米高精度DEM数据等)、中国NDVI植被指数空间分布数据集、夜间灯光数据、三级流域矢量边界、植被类型分布、自然保护区分布、建筑轮廓分布等土地利用、生态环境、灾害监测、社会经济和气象气候系列数据。
原文链接:https://bbs.csdn.net/forums/gisrs?spm=1001.2014.3001.6682
这篇关于2020年黑龙江省水稻种植分布数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






