本文主要是介绍SE5 - BM1684 人工智能边缘开发板入门指南 -- 模型转换、交叉编译、yolov5、目标追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
我们属于SoC模式,即我们在x86主机上基于tpu-nntc和libsophon完成模型的编译量化与程序的交叉编译,部署时将编译好的程序拷贝至SoC平台(1684开发板/SE微服务器/SM模组)中执行。
注:以下都是在Ubuntu20.04系统上操作的,当然Ubuntu18和22也是可以的,因为我们主要是用的官方 docker 环境进行配置。
准备工作
安装docker
首先安装docker
# 更新一下库
sudo apt-get update
sudo apt-gefat upgrade
# 安装 docker
sudo apt-get install docker.io
# docker命令免root权限执行
# 创建docker用户组,若已有docker组会报错,没关系可忽略
sudo groupadd docker
# 将当前用户加入docker组
sudo gpasswd -a ${USER} docker
# 重启docker服务
sudo service docker restart
# 切换当前会话到新group或重新登录重启X会话
newgrp docker
我已经装docker了,这一步没有测试,若有问题请问百度。
下载SDK
在算能官网上,资料下载里下载相关sdk:https://developer.sophgo.com/site/index/material/all/all.html
基础工具包包括:
- tpu-nntc 负责对第三方深度学习框架下训练得到的神经网络模型进行离线编译和优化,生成最终运行时需要的BModel。目前支持Caffe、Darknet、MXNet、ONNX、PyTorch、PaddlePaddle、TensorFlow等。
- libsophon 提供BMCV、BMRuntime、BMLib等库,用来驱动VPP、TPU等硬件,完成图像处理、张量运算、模型推理等操作,供用户进行深度学习应用开发。
- sophon-mw 封装了BM-OpenCV、BM-FFmpeg等库,用来驱动VPU、JPU等硬件,支持RTSP流、GB28181流的解析,视频图像编解码加速等,供用户进行深度学习应用开发。
- sophon-sail 提供了支持Python/C++的高级接口,是对BMRuntime、BMCV、BMDecoder、BMLib等底层库接口的封装,供用户进行深度学习应用开发。
可以下载这个SDK

这里面包含了models里的所有代码,当然里面很多包是用不到的。
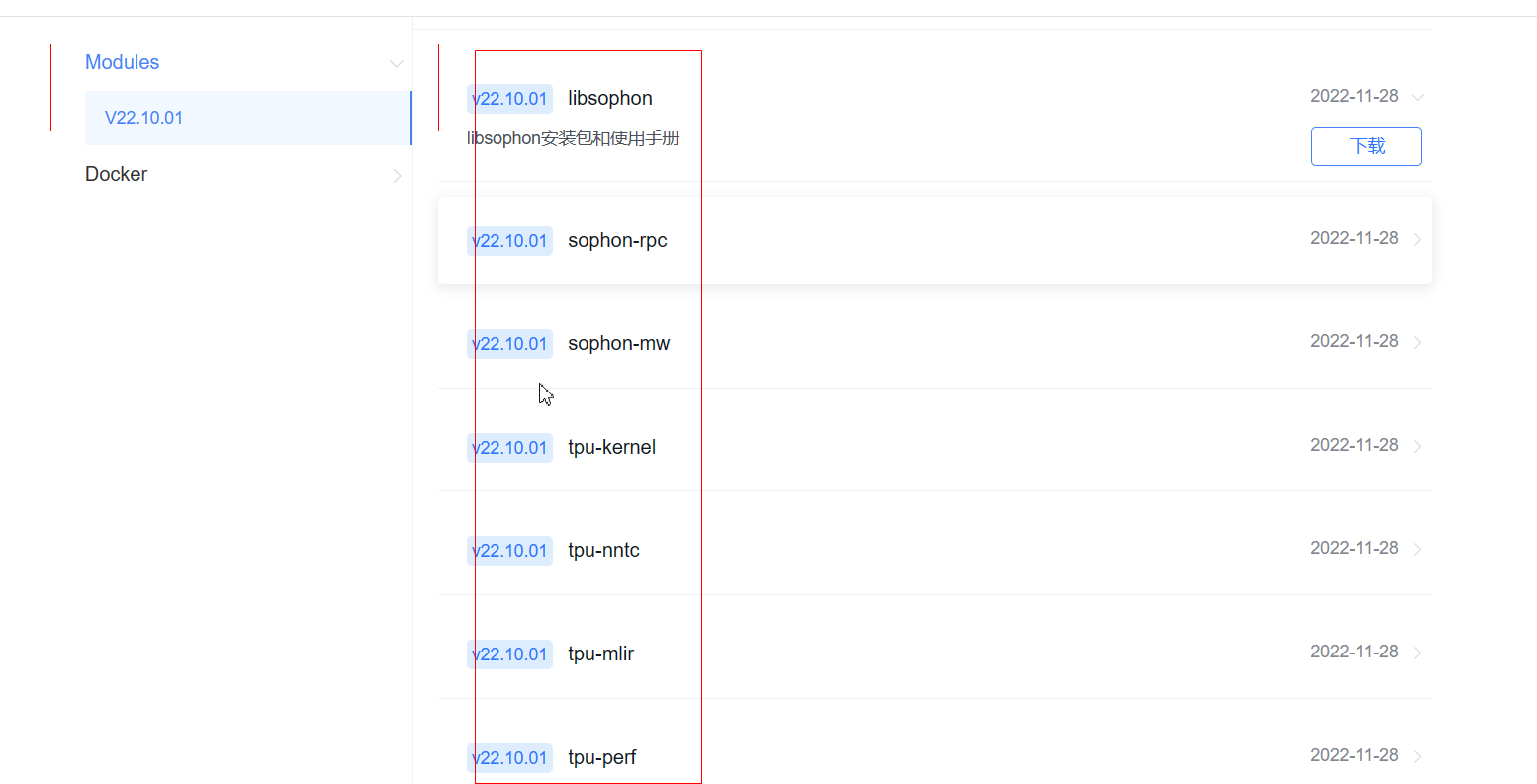
也可以只下载我们需要的sdk
主要是这几个:
tpu-nntc
libsophon
sophon-mw
sophon-demo
sophon-img
sophon-sail
sophon-demo
分别wget 到本地就行,
# 先建个存放的路径
mkdir fugui
# 分别wget 到本地就行
wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/10/libsophon_20221027_214818.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/11/sophon-mw_20221027_183429.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-demo_20221027_181652.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-img_20221027_215835.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-sail_20221026_200216.zip https://sophon-file.sophon.cn/sophon-prod-s3/drive/22/11/28/15/sophon-demo_20221027_181652.zip
配置环境
装上解压缩工具
sudo apt-get install unzip
先把这几个压缩文件解压了
unzip \*.zip
创建docker容器:
#如果当前系统没有对应的镜像,会自动从docker hub上下载;此处将tpu-nntc的上一级目录映射到docker内的/workspace目录;这里用了8001到8001端口的映射(使用ufw可视化工具会用到端口号)。如果端口已被占用,请根据实际情况更换为其他未占用的端口。
:~/fugui# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
进入 tpu-nntc,解压缩包
root@39d67fa4c7bb:/workspace/fugui/tpu-nntc_20221028_200521# tar -zxvf tpu-nntc_v3.1.3-242ef2f9-221028.tar.gz
进入tpu-nntc_v3.1.3-242ef2f9-221028 运行一下命令初始化软件环境
source scripts/envsetup.sh
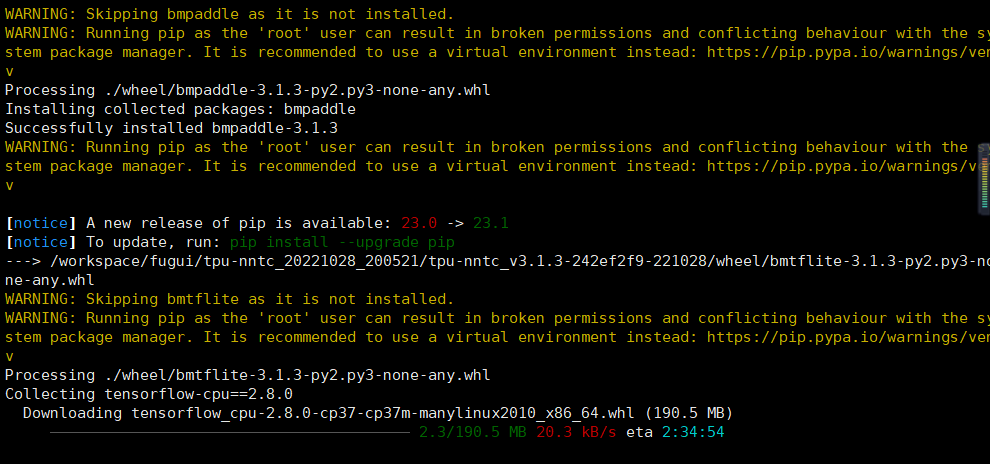
在下载tensorflow时比较慢,我们都是用pytorch,直接ctrl c跳过,不装他了。
yolov5
这里就不演示官方模型了,直接用我们自己训练的模型进行量化推理。
注意:这里必须用yolov5 v6.1版本
如何训练就不说了,参考:这篇文章
最好使用yolov5s训练,然后对训练后的模型进行转换。比如我训练的是安全帽检测,现在生成了best.pt这个权重文件,为了好区分我改名为anquanmao.pt
将他放在了yolov5的根目录下,然后修改了models文件下的yolo.py中的forward函数。将return x if self.training else (torch.cat(z, 1), x) 修改为:
return x if self.training else x
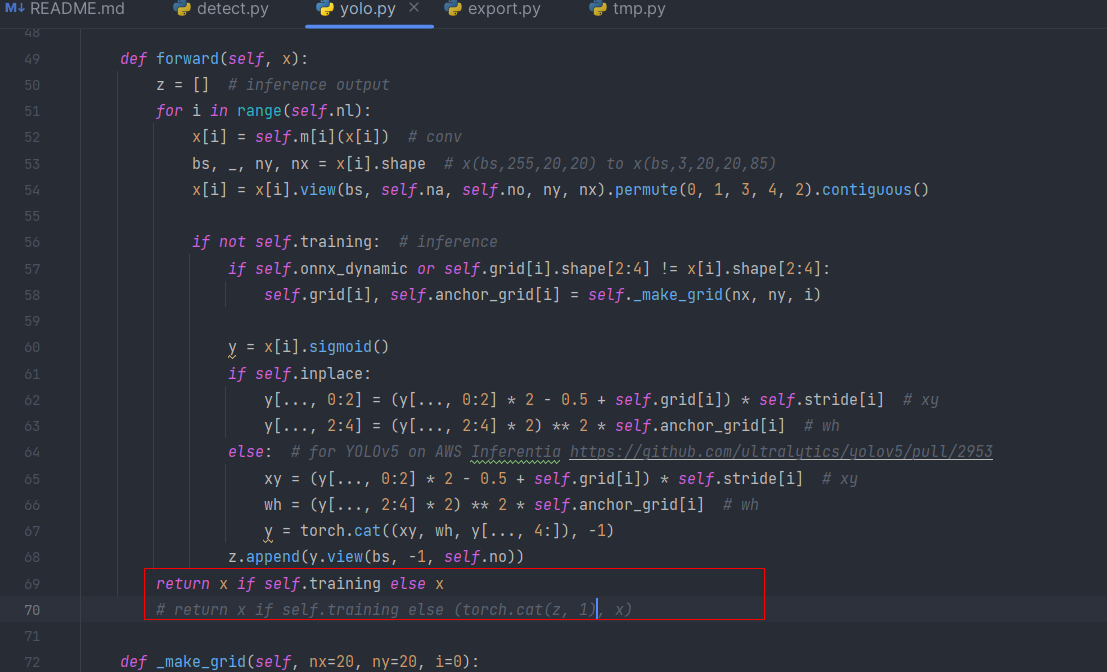
然后运行
python export.py --weight anquanmao.pt --include torchscript
这样生成了 anquanmao.torchscript 文件
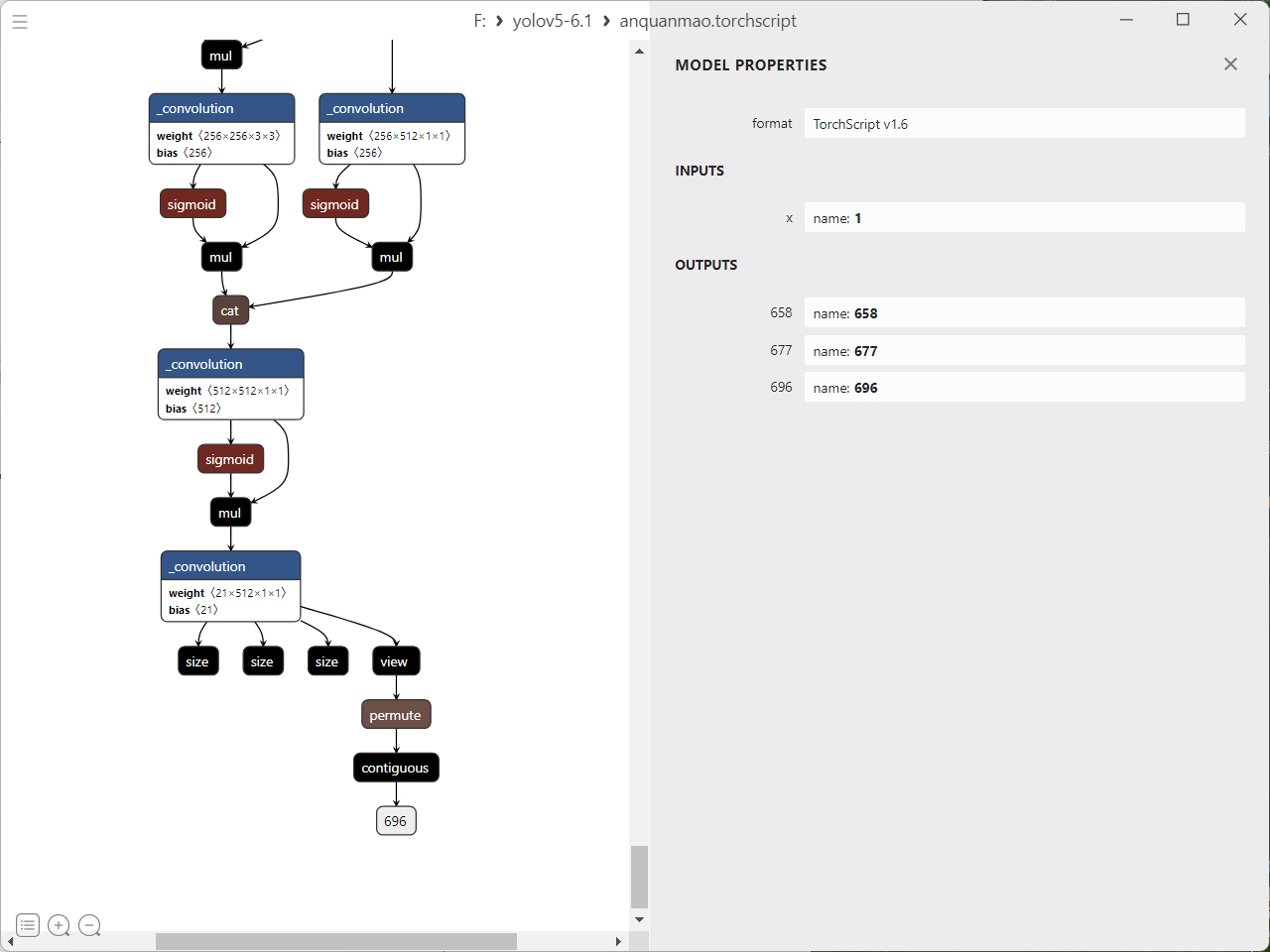
打开这个权重文件看看是不是和我的一样,只要是yolov5 6.1就肯定一样。
修改 anquanmao.torchscript 为 anquanmao.torchscript.pt (就是在最后加个.pt)
然后将这个文件拷贝到你的x86服务器里,路径为:
/root/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/data
然后找些你训练的图片,也就是安全帽,200张左右就行
同样上传到那个文件夹里
然后就可以进行模型转换了
# 先备份一下
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# cp 2_2_gen_int8bmodel.sh 3_2_gen_int8bmodel.sh
vi cp 2_2_gen_int8bmodel.sh
然后修改里面内容,200太多了,转换起来太慢了,50就够了

修改model_info.sh
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# vi model_info.sh
echo "start fp32bmodel transform, platform: ${platform} ......"root_dir=$(cd `dirname $BASH_SOURCE[0]`/../ && pwd)
build_dir=$root_dir/build
# 将这里修改为我们刚才存放的.torchscript.pt文件地址
src_model_file=${root_dir}/data/anquanmao.1_3output.torchscript.pt
src_model_name=`basename ${src_model_file}`
# 这里也修改下吧 yolov5s ——> anquanmao
dst_model_prefix="anquanmao"
dst_model_postfix="coco_v6.1_3output"
fp32model_dir="${root_dir}/data/models/${platform}/fp32model"
int8model_dir="${root_dir}/data/models/${platform}/int8model"
lmdb_src_dir="${root_dir}/data/images"
# 这里修改为我们上传的图片地址
image_src_dir="${root_dir}/data/anquanmao"
# lmdb_src_dir="${build_dir}/coco2017val/coco/images/"
#lmdb_dst_dir="${build_dir}/lmdb/"
img_size=${2:-640}
batch_size=${3:-1}
iteration=${4:-2}
img_width=640
img_height=640
运行转换命令前需要加上权限,否则不能执行
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# sudo chmod 777 *
然后执行转int8bmodel模型,转FP32也一样
root@39d67fa4c7bb:/workspace/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/scripts# ./ 2_2_gen_int8bmodel.sh
性能不好的机器会非常慢,等待完成即可
编译yolov5 c++程序
/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build#
cd cpp/deepsort_bmcv
mkdir build && cd build
# 请根据实际情况修改-DSDK的路径,需使用绝对路径
cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
make
复制到开发板
scp ../yolov5_bmcv.soc linaro@192.168.17.153:/data/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv
开发板运行
linaro@bm1684:/data/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv$ ./yolov5_bmcv_drawr.soc --input=rtsp://admin:sangfor@123@192.168.17.253 --bmodel=BM1684/yolov5s_v6.1_3output_int8_1b.bmodel
目标追踪
注:所有模型转换都是在docker环境中的
先进入docker
这里我们是要在docker环境里编译的,所以先进入docker
:~/tpu-nntc# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
初始化环境
root@2bb02a2e27d5:/workspace/tpu-nntc# source ./scripts/envsetup.sh
docker里安装编译器
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu libeigen3-dev
本C++例程依赖Eigen,您需要在编译c++程序的机器上运行如下命令安装:
sudo apt install libeigen3-dev
先下载相关文件,主要是追踪的测试视频,测试图片,目标追踪的权重,目标检测的权重
# 安装unzip,若已安装请跳过
sudo apt install unzip
chmod -R +x scripts/
./scripts/download.sh
然后编译c++代码
/workspace/sophon-demo/sample/DeepSORT/cpp/deepsort_bmcv/build#
cd cpp/deepsort_bmcv
mkdir build && cd build
# 请根据实际情况修改-DSDK的路径,需使用绝对路径。
cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
make
这时会生成deepsort_bmcv.soc文件,复制到盒子里
:/workspace/sophon-demo/sample/DeepSORT/cpp/deepsort_bmcv# scp -r deepsort_bmcv.soc linaro@192.168.17.125:/data/yolo/sophon-demo/sample/DeepSORT/cpp
测试视频
./deepsort_bmcv.soc --input=rtsp://admin:sangfor@123@192.168.17.253 --bmodel_detector=../../BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor=../../BM1684/extractor_fp32_1b.bmodel --dev_id=0
运行相关代码,这个是检测图片的
cd python
python3 deepsort_opencv.py --input ../datasets/mot15_trainset/ADL-Rundle-6/img1 --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
对视频追踪
python3 deepsort_opencv.py --input ../datasets/test_car_person_1080P.mp4 --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
对本地摄像头视频追踪
python3 deepsort_opencv.py --input rtsp://admin:sangfor@123@192.168.17.253 --bmodel_detector ../models/BM1684/yolov5s_v6.1_3output_int8_1b.bmodel --bmodel_extractor ../models/BM1684/extractor_fp32_1b.bmodel --dev_id=0
人体姿态估计
python3 python/openpose_opencv.py --input rtsp://admin:sangfor@123@192.168.17.253 --bmodel models/BM1684/pose_coco_fp32_1b.bmodel --dev_id 0
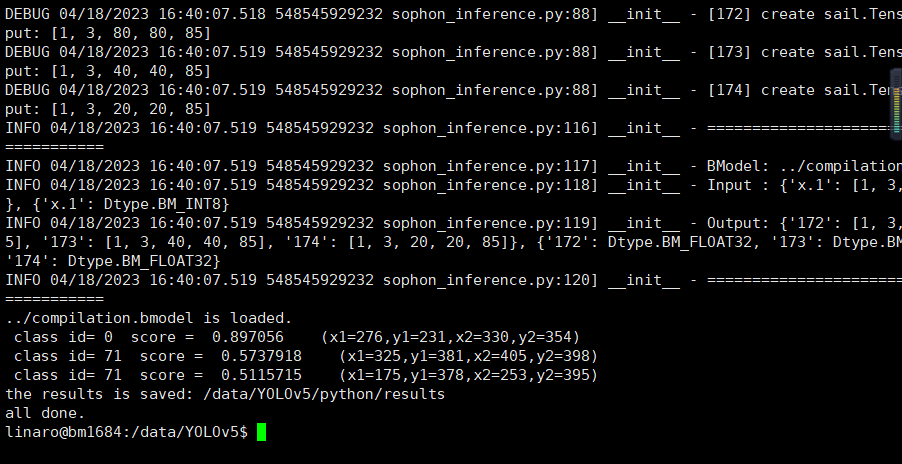
生成的文件会放在sample/YOLOv5/data/models/BM1684/int8model/anquanmao_batch1里
:~/fugui/sophon-demo_20221027_181652/sophon-demo_v0.1.0_b909566_20221027/sample/YOLOv5/data/models/BM1684/int8model/anquanmao_batch1# ls
compilation.bmodel input_ref_data.dat io_info.dat output_ref_data.dat
然后将转换好的模型推送到开发板
scp compilation.bmodel linaro@{开发板ip地址}:/data/{你的yolov5存放路径}
开发板环境配置
搭建 libsophon 环境
cd libsophon_<date>_<hash>
# 安装依赖库,只需要执行一次
sudo apt install dkms libncurses5
sudo dpkg -i sophon-*.deb
# 在终端执行如下命令,或者log out再log in当前用户后即可使用bm-smi等命令
source /etc/profile
python3 yolov5_new_1.py --input rtsp://admin:1111111a@192.168.16.223 --bmodel yolov5s_v6.1_3output_fp32_1b.bmodel
c++编译环境
安装libsophon
进入sophon-img_20221027_215835这个路径
解压里面的tar包
:~/fugui/sophon-img_20221027_215835# tar -zxvf libsophon_soc_0.4.2_aarch64.tar.gz
将相关库目录和头文件目录拷贝到soc-sdk文件夹中
:~/fugui/sophon-img_20221027_215835/libsophon_soc_0.4.2_aarch64/opt/sophon/libsophon-0.4.2# sudo cp -rf include lib ~/fugui/soc-sdk
安装sophon-opencv 和sophon-ffmpeg
先进入sophon-mw,解压sophon-mw-soc_0.4.0_aarch64.tar.gz这个tar包
:~/fugui/sophon-mw_20221027_183429# tar -zxvf sophon-mw-soc_0.4.0_aarch64.tar.gz
复制相关文件到soc-sdk
:~/fugui/sophon-mw_20221027_183429/sophon-mw-soc_0.4.0_aarch64/opt/sophon# cp -rf sophon-ffmpeg_0.4.0//lib sophon-ffmpeg_0.4.0/include/ ~/fugui/soc-sdk:~/fugui/sophon-mw_20221027_183429/sophon-mw-soc_0.4.0_aarch64/opt/sophon# cp -rf sophon-opencv_0.4.0//lib sophon-opencv_0.4.0/include/ ~/fugui/soc-sdk
很简单,复制过去,交叉编译的环境就搭建好了
TPU-NNTC环境
这里我们是要在docker环境里编译的,所以先进入docker
:~/fugui# docker run -v $PWD/:/workspace -it sophgo/tpuc_dev:latest
然后进入tpu-nntc,初始化环境
root@2bb02a2e27d5:/workspace/tpu-nntc# source ./scripts/envsetup.sh
docker里安装编译器
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# sudo apt-get install gcc-aarch64-linux-gnu g++-aarch64-linux-gnu
进入sophon-demo路径
下载相关文件
:~/fugui/sophon-demo/sample/YOLOv5# chmod -R +x scripts/
:~/fugui/sophon-demo/sample/YOLOv5# ./scripts/download.sh
编译yolov5
我们这里只是交叉编译,不能在x86设备上运行,要复制到我们1684平台
先cmake
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# cmake -DTARGET_ARCH=soc -DSDK=/workspace/soc-sdk ..
在make
root@2bb02a2e27d5:/workspace/sophon-demo/sample/YOLOv5/cpp/yolov5_bmcv/build# make
此时会出现.soc文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eWPar5Yp-1692844732110)(https://gitee.com/lizheng0219/picgo_img/raw/master/img202325/image-20230421134631891.png)]
把输出的文件传导我们开发板上运行下
scp -r yolov5_bmcv linaro@192.168.17.125:/data/sophon-demo/sample/YOLOv5/cpp/
运行推理图片
./yolov5_bmcv.soc --input=../../coco128 --bmodel=../../python/yolov5s_v6.1_3output_fp32_1b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
推理视频
./yolov5_bmcv.soc --input=../../test.avi --bmodel=../../python/yolov5s_v6.1_3output_fp32_1b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
c++推理网络摄像头
./yolov5_bmcv.soc --input=rtsp://admin:sangfor@123@192.168.17.253 --bmodel=/data/ai_box/yolov5s_640_coco_v6.1_3output_int8_1b_BM1684.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
./yolov5_bmcv.soc --input=rtsp://admin:sangfor@123@192.168.17.253 --bmodel=/data/models/all16_v6.1_3output_int8_4b.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=/data/models/all16.names
网络摄像头:安全帽
./yolov5_bmcv.soc --bmodel=anquanmao.bmodel --dev_id=0 --conf_thresh=0.5 --nms_thresh=0.5 --classnames=../../coco.names
Python推理
python3 yolov5_opencv.py --input rtsp://admin:1111111a@192.168.16.222 --bmodel ../yolov5s_v6.1_3output_int8_4b.bmodel
前端只展示一路摄像头,我们只需要做一路摄像头使用多个算法推理。
不展示的摄像头也要实时在后台推理,有出现问题时要及时报警。
这样我们需做出单路摄像头推理多算法(单摄像头单算法也行,把所有检测都放到一个模型里,输出时只输出他选择的那个)
把所有模型统一训练比较简单,后台一块推理
sophon-pipeline
本地编译
docker run -v $PWD/:/workspace -p 8001:8001 -it sophgo/tpuc_dev:latest
source scripts/envsetup.sh
sudo apt-get install -y gcc-aarch64-linux-gnu g++-aarch64-linux-gnu libeigen3-dev
./tools/compile.sh soc /workspace/soc-sdk
开发板运行
linaro@bm1684:/data/sophon-pipeline/release/video_stitch_demo$ ./soc/video_stitch_demo --config=cameras_video_stitch1.json
英码
export PYTHONPATH=$PYTHONPATH:/system/libexport
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/system/lib/
python
pip3 install sophon_arm-master-py3-none-any.whl --force-reinstall
pip3 install opencv-python-headless<4.3
开发板执行命令
python3 python/yolov5_opencv.py --input ../data/images/coco200/000000009772.jpg --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
python3 python/yolov5_opencv.py --input ../data/xiyanimg/000017.jpg --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
python3 python/yolov5_video.py --input rtsp://admin:sangfor@123@192.168.17.253 --model ../compilation.bmodel
python3 python/yolov5_video.py --input rtsp://admin:1111111a@192.168.16.222 --model ../compilation.bmodel --dev_id 0 --conf_thresh 0.5 --nms_thresh 0.5
tar -zxf ~/Release_221201-public/sophon-mw_20221227_040823/sophon-mw-soc_*_aarch64.tar.gz
这篇关于SE5 - BM1684 人工智能边缘开发板入门指南 -- 模型转换、交叉编译、yolov5、目标追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





