本文主要是介绍Keepalive与idle监测及性能优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Keepalive 与 idle监测
- Keepalive(保活): Keepalive 是一种机制,通常用于TCP/IP网络。它的目的是确保连接双方都知道对方仍然存在并且连接是活动的。这是通过定期发送控制消息(称为keepalive消息)实现的。如果在预定时间内未收到回复,那么发送方可以认为另一方已经失去响应,可能会关闭连接。这种机制对于长时间保持连接,但可能不频繁交换数据的场景特别有用,比如数据库连接或长期的网络会话。
- Idle 监测(空闲监测): Idle 监测是指监测网络连接在一段时间内是否有数据传输。如果在这段时间内没有数据交换,那么认为连接是空闲的。空闲监测通常用于管理资源,如关闭长时间未使用的连接来释放资源。这在服务器环境中尤为重要,因为服务器可能需要处理大量的连接,而且资源(如内存和处理能力)是有限的。
两者的主要区别在于它们的目的和实施方式。Keepalive 主要用于确保连接双方知道对方仍然“活着”,并且连接是有效的。而Idle监测则用于确定一个连接在一段时间内是否有活动,以决定是否应该保持或关闭这个连接。Keepalive是通过定期发送控制消息来实现的,而Idle监测是通过观察一段时间内的数据传输活动来实现的。
在Linux内核中也有一个keepalive来确认对端的连接状态是否健康。

| net.ipv4.tcp_keepalive_time = 7200 |
|---|
| net.ipv4.tcp_keepalive_intvl = 75 |
| net.ipv4.tcp_keepalive_probes = 9 |
当启用(默认关闭)keepalive 时,TCP 在连接没有数据通过的7200秒后 发送keepalive 探测消息,当探测没有确认时,按75秒的重试频率重发, 一直发9 个探测包都没有确认,就认定连接失效。
所以总耗时一般为:2 小时11 分钟(7200 秒+ 75 秒* 9 次)
Server端开启TCP keepalive的两种方式
serverBootstrap.childOption(ChannelOption.SO_KEEPALIVE,true);serverBootstrap.childOption(NioChannelOption.of(StandardSocketOptions.SO_KEEPALIVE),true);
除了在tcp网络层开启keepalive之外,我们普遍还需要在应用层启动keepalive,一般称之为:应用心跳(心跳机制 ),原因如下:
1、协议分层,各层关注点不同,网络传输层关注网络是否可达,应用层关注是否能正常提供服务
2、tcp的keepalive默认关闭,并且经过路由等中转设备后keepalive包有可能被丢弃
- Keepalive包的特性:Keepalive包是TCP协议中的空包,不携带数据,仅用于检测对端是否仍然可达。由于这些包没有数据负载,它们在网络中的优先级可能比正常的数据包要低。
- 网络设备的策略和配置:在复杂的网络环境中,路由器、防火墙或其他中间设备可能会根据自己的配置和策略处理流经的数据包。在某些情况下,这些设备可能会丢弃认为不重要的包,尤其是在网络拥堵或资源紧张的情况下。由于Keepalive包通常被视为不携带重要数据的控制包,因此在某些网络环境中可能会被丢弃。
- 网络问题:除了被网络设备主动丢弃之外,Keepalive包也可能因为网络问题(如不稳定的连接、路径更改、丢包率高的链路等)而在传输过程中丢失。
当Keepalive包丢失时,发送方可能无法准确判断连接的状态,这可能导致误判连接已断开而提前关闭连接,或者错误地认为一个已经失效的连接仍然有效。因此,在设计和部署基于TCP Keepalive的系统时,需要考虑到这些潜在的网络问题和限制。
3、tcp层的keepalive时间太长,默认>2小时,虽然可改,但是属于系统参数一旦改动影响该机器上的所有应用 另外需要注意:http虽然属于应用层协议,因此会经常听到 HTTP 的头信息:Connection: Keep-Alive,HTTP/1.1 默认使用Connection:keep-alive进行长连接。在一次 TCP 连接中可以完成多个 HTTP 请求,但是对每个请求仍然 要单独发 header,Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache)中 设定这个时间。这种长连接是一种“伪链接”,而且只能由客户端发送请求,服务端响应。 HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接
Idle 监测,只是负责诊断,诊断后,做出不同的行为,决定Idle 监测的最终用途,一般用来配合keepalive ,减少 keepalive 消息
Idle配合keepalive的发展阶段
刚开始的时候:定时keepalive 消息,keepalive 消息与服务器正常消息交换完全不关联,定时就发送
这样会导致发送很多没有用的消息,我的连接本来就是正常的,我为啥还得额外告诉服务器**“我还活着”**呢?
后来进化为:既然我正常发消息的时候完全没必要发送keepalive消息,那么我就在没有发送消息的时候去发送keepalive消息,也就是空闲检测+判断为Idle的时候才会发送keepalive,无数据发送超过一定的时候之后,并且判定为Idle,再发送keepalive。
Idle的好处
- 快速释放损坏的、恶意的、很久不用的连接,让系统时刻保持最好的状态
- 实际应用中:结合起来使用。按需keepalive ,保证不会空闲,如果空闲,关闭连接
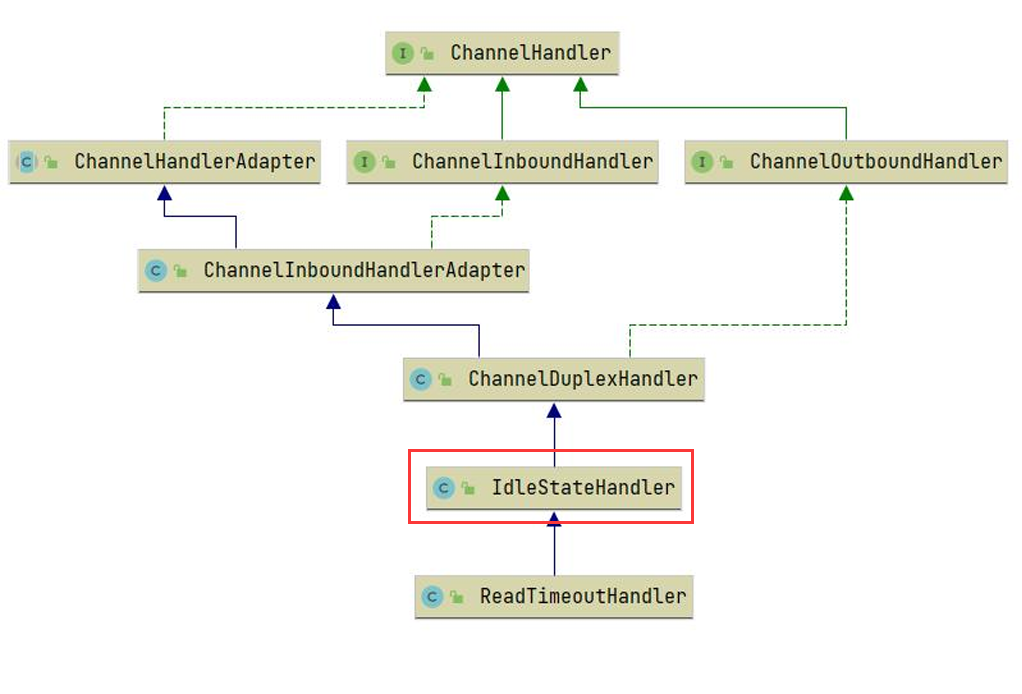
IdleStateHandler 是 Netty 框架中的一个处理空闲状态的类,主要用于检测并处理 Channel(连接)在一段时间内的空闲状态。这个构造函数接受三个时间参数和一个时间单位参数:
readerIdleTimeSeconds:读超时时间,即如果在指定时间内没有从 Channel 中读取到任何数据(即客户端没有向服务器发送任何数据),则认为该 Channel 进入了读空闲状态。writerIdleTimeSeconds:写超时时间,即如果在指定时间内 Channel 没有写出任何数据(即服务器没有向客户端发送任何数据),则认为该 Channel 进入了写空闲状态。allIdleTimeSeconds:所有类型的超时时间,即在指定时间内 Channel 既没有读取也没有写出任何数据,则认为该 Channel 进入了整体空闲状态。
当进入空闲状态的时候就会去调用channelIdle方法

@Slf4j
public class ClientWriterIdleHandler extends IdleStateHandler {public ClientWriterIdleHandler() {super(0, 5, 0, TimeUnit.SECONDS);}@Overrideprotected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) throws Exception {super.channelIdle(ctx, evt);if(evt==IdleStateEvent.FIRST_WRITER_IDLE_STATE_EVENT){//发送 keepaliveUserInfo userInfo=new UserInfo();userInfo.setName("this is keepalive message");log.info("发送心跳信息");ctx.channel().writeAndFlush(userInfo);}}
}public class ServerReaderIdleHandler extends IdleStateHandler {public ServerReaderIdleHandler() {super(10, 0, 0, TimeUnit.SECONDS);}@Overrideprotected void channelIdle(ChannelHandlerContext ctx, IdleStateEvent evt) throws Exception {if(evt==IdleStateEvent.FIRST_READER_IDLE_STATE_EVENT){ctx.channel().close();}}
}
高级特性,性能优化
参数调优
-
linux系统参数,例如:/proc/sys/net/ipv4/tcp_keepalive_time
-
netty支持的系统参数设置,例如:serverbootstrap.option(ChannelOption.SO_BACKLOG,1024),且设置形式有两种:
-
1、针对ServerSocketChannel:通过.option设置
-
2、针对SocketChannel:通过.childOption设置
Linux参数: 进行tcp连接时,系统为每个tcp连接都会创建一个socket句柄,其实就是一个文件句柄(linux一切皆为文件),但是系统对于每个进程能够打开的文件句柄数量 做了限制,超出则报错:Too many open file 设置方式:有很多种,ulimit -n [xxx] 注意:该命令修改的数值,只对当前登录用户目前使用的环境有效,系统重启或用户退出后失效,所以建议的做法是可以作为启动脚本的一部分,在启动程序前执行。
对于Netty来说:
针对ScoketChannel,7个,通过.childOption设置,常用的两个如下:
1、SO_KEEPALIVE,tcp层keepalvie,默认关闭,一般选择关闭tcp keepalive 而使用应用keepalive
2、TCP_NODELAY:设置是否启用nagle算法,该算法是tcp在发送数据时将小的、碎片化的数据拼接成一个大的报文一起发送,以 此来提高效率,默认是false(启用),如果启用可能会导致有些数据有延时,如果业务不能忍受,小报文也需要立即发送则可以禁用该算法
针对ServerScoketChannel,通过.Option设置,常用的一个如下:
1、SO_BACKLOG:最大等待连接数量,netty在linux下该值的获取是通过:io.netty.util.NetUtil完成的

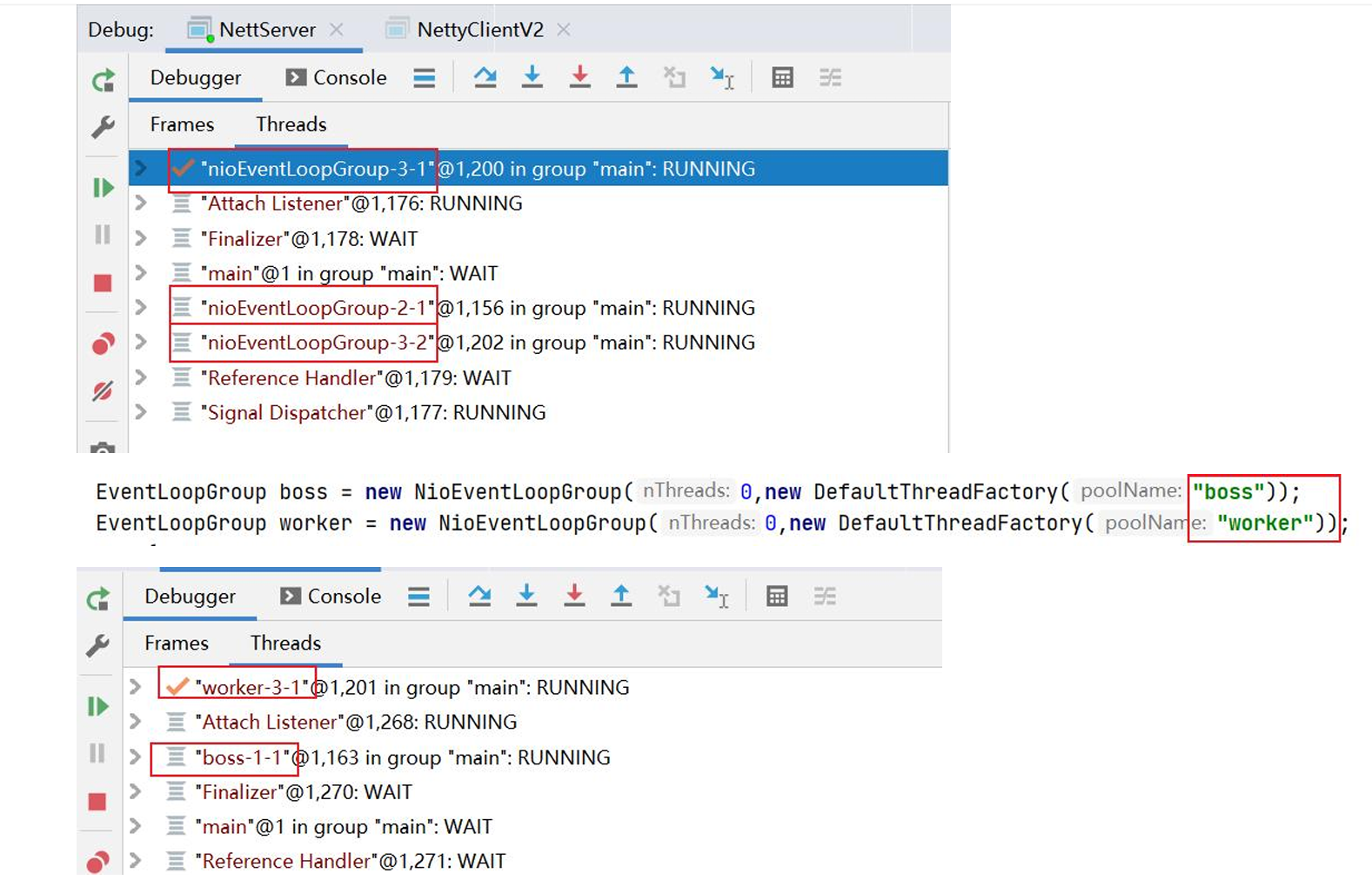
应用诊断->完善线程名
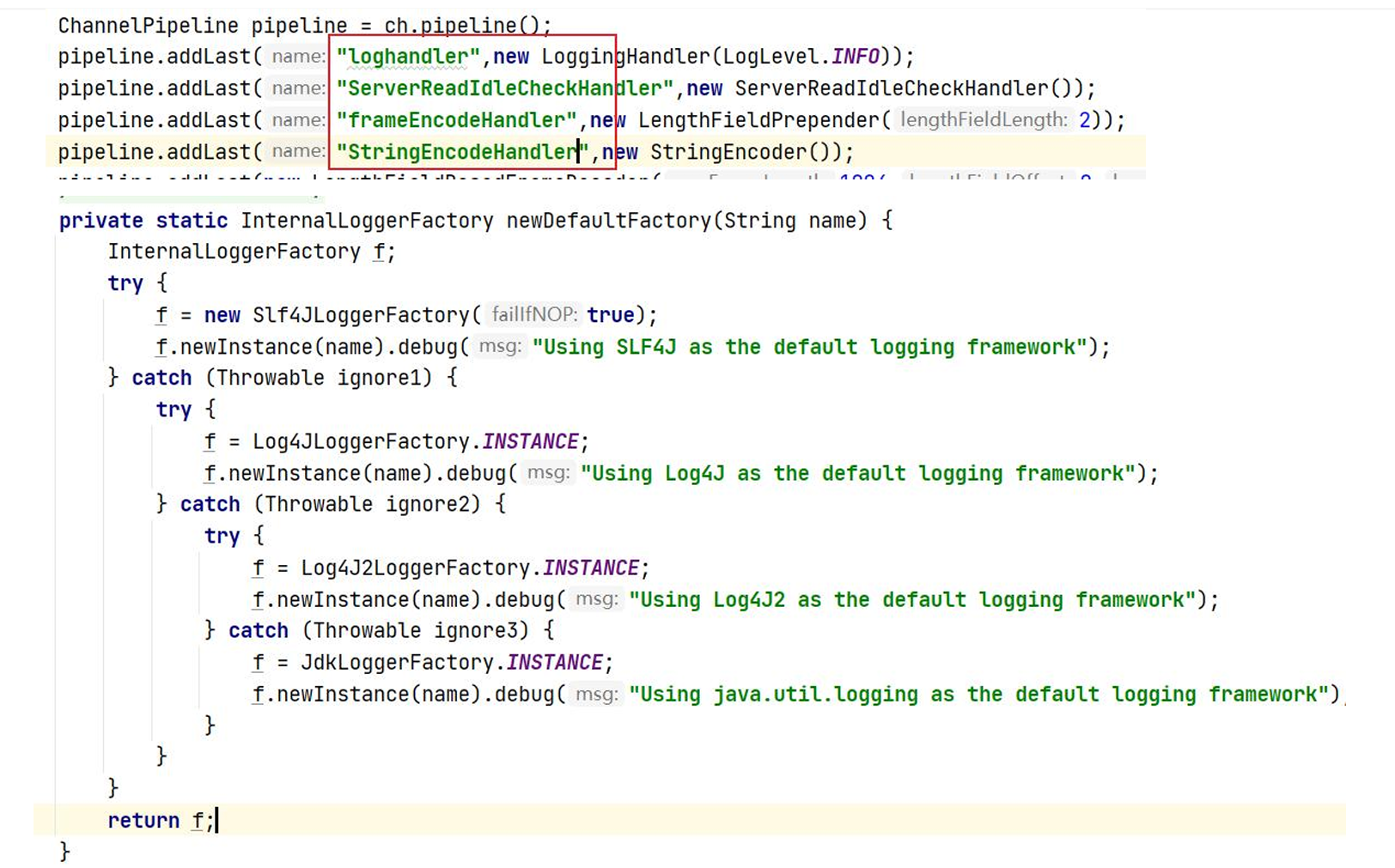
添加Handler名称 & 日志
线程模型优化
EventExecutorGroup business = new UnorderedThreadPoolEventExecutor(10,new DefaultThreadFactory("business"));pipeline.addLast(business,"ProtoStuffDecoder",new ProtoStuffDecoder());

零拷贝
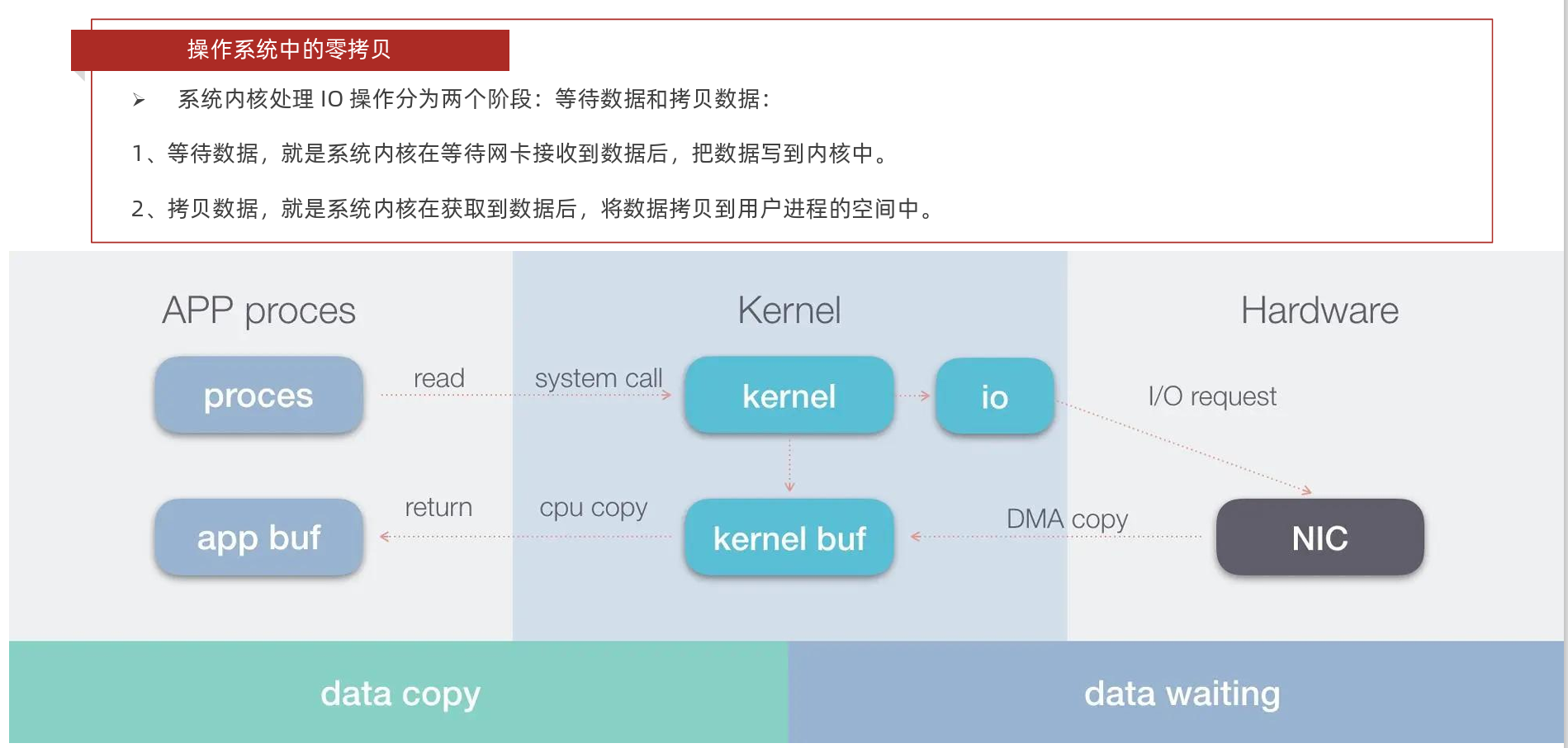
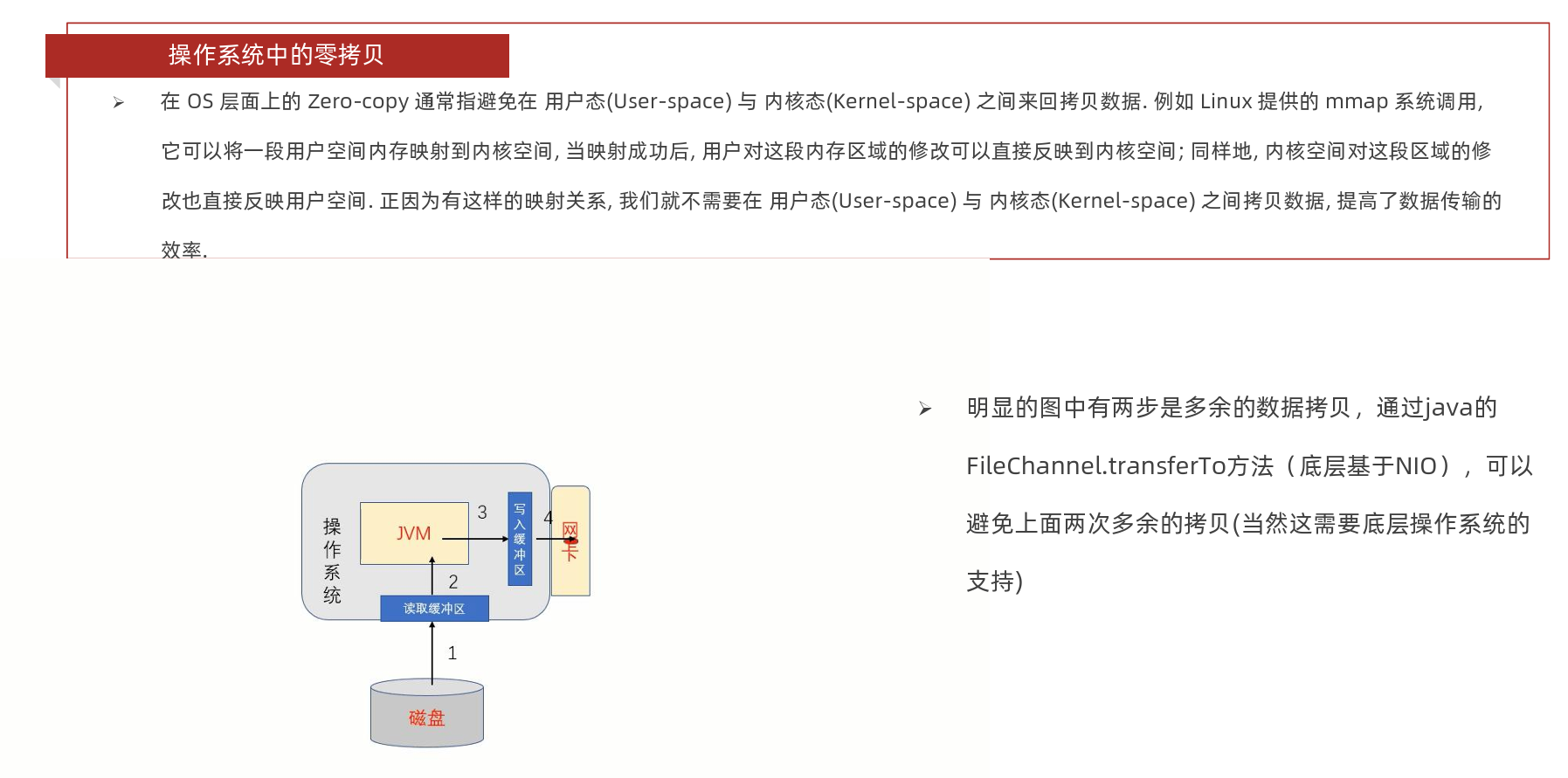
Netty 中的 Zero-copy 与上面我们所提到到 OS 层面上的 Zero-copy 不太一样, Netty的 Zero-coyp 完全是在用户态(Java 层面)的, 它的 Zero-copy 的更多的是偏向于 优化数据操作 这样的概念,Netty的Zero-copy主要体现在如下几个方面:
- 1、Direct Buffer: 直接堆外内存区域分配空间而不是在堆内存中分配, 如果使用传统的堆内存分配,当我们需要将数据通过 socket发送的时候,需要将数据从堆内存拷贝到堆外直接内存,然后再由直接内存拷贝到网卡接口层,通过Netty提供的Direct Buffers直接将数据分配到堆外内存,避免多余的数据拷贝
- 2、 Composite Buffers:传统的ByteBuffer,如果需要将两个ByteBuffer中的数据组合到一起,我们需要首先创建一个 size=size1+size2大小的新的数组,然后将两个数组中的数据拷贝到新的数组中。但是使用Netty提供的组合ByteBuf,就可以避 免这样的操作,因为CompositeByteBuf并没有真正将多个Buffer组合起来,而是保存了它们的引用,从而避免了数据的拷贝, 实现了零拷贝;同时也支持 slice 操作, 因此可以将 ByteBuf 分解为多个共享同一个存储区域的 ByteBuf, 避免了内存的拷贝。
- 3、通过 wrap 操作, 我们可以将 byte[] 数组、ByteBuf、ByteBuffer等包装成一个 Netty ByteBuf 对象, 进而避免了拷贝操作
- 4、通过 FileRegion 包装的FileChannel.tranferTo (Java nio)实现文件传输, 可以直接将文件缓冲区的数据发送到目标 Channel, 避免了传统通过循环 write 方式导致的内存拷贝问题
这篇关于Keepalive与idle监测及性能优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






