本文主要是介绍2、线程池ThreadPool有界、无界队列、同步队列以及5大参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
队列的本质是内存,无界队列会造成jvm内存溢出,线程的本质是cpu,CPU爆满
线程池的两个方法:submit方法中调用的execute方法,但是submit方法有返回值;
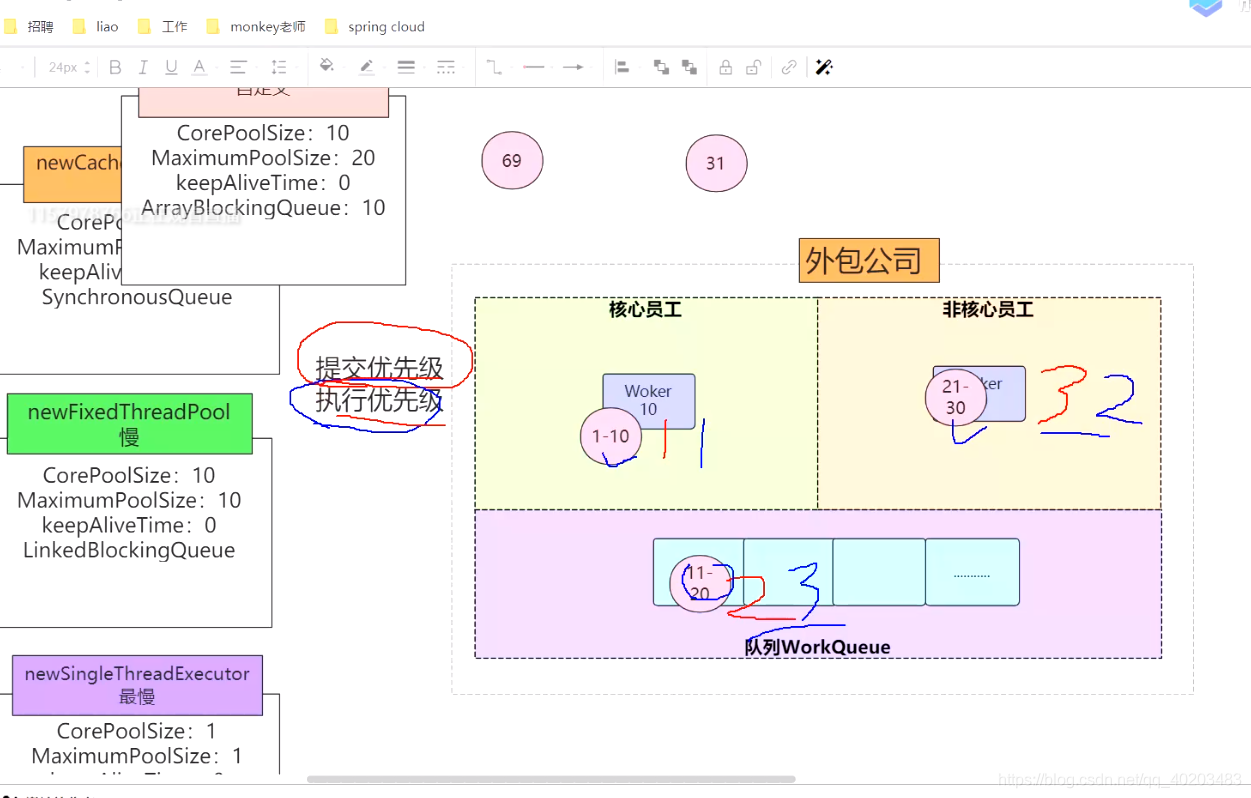
Java提供了4钟线程池:
(1)、SingleThreadExecutor:核心线程、最大线程数都是1,阻塞队列是无界队列LinkedBlockingQueue
使用场景: 适用于串行执行任务场景
(2)、FixedThreadPool:线程数量固定的线程池,当线程处于空闲状态时,他们并不会被回收,除非线程池被关闭。当所有的线程都处于活动状态时,新的任务都会处于等待状态,直到有线程空闲出来。
LinkedBlockingQueue阻塞队列;
使用场景:适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
(3)、CachedThreadPool:核心线程数为0,总线程数量阈值为Integer.MAX_VALUE,SynchronousQueue队列。
使用场景:执行大量短生命周期任务。因为maximumPoolSize是无界的,所以提交任务的速度 > 线程池中线程处理任务的速度就要不断创建新线程;每次提交任务,都会立即有线程去处理,因此CachedThreadPool适用于处理大量、耗时少的任务。
(4)、ScheduledThreadPool:线程总数阈值为Integer.MAX_VALUE,工作队列使用DelayedWorkQueue,非核心线程存活时间为0,所以线程池仅仅包含固定数目的核心线程。
使用场景:周期性执行任务,并且需要限制线程数量的场景
你可以通过Executors来实例化这四种线程池。
查看源码会发现,这四种线程池都直接或者间接获取的ThreadPoolExecutor实例 ,只是实例化时传递的参数不一样。所以如果java提供的四种线程池满足不了我们的需求,我们可以创建自定义线程池。
ThreadPoolExecutor的构造方法如下:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue) {this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,Executors.defaultThreadFactory(), defaultHandler);}
其中:
corePoolSize: 核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中
maximumPoolSize: 线程池最大线程数,它表示在线程池中最多能创建多少个线程;
keepAliveTime: 表示线程没有任务执行时最多保持多久时间会终止。
unit: 参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
TimeUnit.DAYS; //天TimeUnit.HOURS; //小时TimeUnit.MINUTES; //分钟TimeUnit.SECONDS; //秒TimeUnit.MILLISECONDS; //毫秒TimeUnit.MICROSECONDS; //微妙TimeUnit.NANOSECONDS; //纳秒
几种典型的工作队列
ArrayBlockingQueue:使用数组实现的有界阻塞队列,特性先进先出
LinkedBlockingQueue:使用链表实现的阻塞队列,特性先进先出,可以设置其容量,默认为Interger.MAX_VALUE,特性先进先出
SynchronousQueue:一个不存储元素的阻塞队列,每个插入操作,必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态
拒绝策略
handler: 表示当拒绝处理任务时的策略,有以下四种取值:
ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常。
ThreadPoolExecutor.DiscardPolicy:也是丢弃任务,但是不抛出异常。
ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务(重复此过程)
ThreadPoolExecutor.CallerRunsPolicy:只要线程池不关闭,该策略直接在调用者线程中,运行当前被丢弃的任务
个人认为这4中策略不友好,最好自己定义拒绝策略,实现RejectedExecutionHandler接口
线程池几个参数的理解:
比如去火车站买票, 有10个售票窗口, 但只有5个窗口对外开放. 那么对外开放的5个窗口称为核心线程数, 而最大线程数是10个窗口.如果5个窗口都被占用, 那么后来的人就必须在后面排队, 但后来售票厅人越来越多, 已经人满为患, 就类似于线程队列已满.这时候火车站站长下令, 把剩下的5个窗口也打开, 也就是目前已经有10个窗口同时运行. 后来又来了一批人,10个窗口也处理不过来了, 而且售票厅人已经满了, 这时候站长就下令封锁入口,不允许其他人再进来, 这就是线程异常处理策略.而线程存活时间指的是, 允许售票员休息的最长时间, 以此限制售票员偷懒的行为.
以下主要讲解存储等待执行的任务的队列对线程池执行的影响。
一.有界队列
1.初始的poolSize < corePoolSize,提交的runnable任务,会直接做为new一个Thread的参数,立马执行 。
2.当提交的任务数超过了corePoolSize,会将当前的runable提交到一个block queue中,。
3.有界队列满了之后,如果poolSize < maximumPoolsize时,会尝试new 一个Thread的进行救急处理,立马执行对应的runnable任务。
4.如果3中也无法处理了,就会走到第四步执行reject操作。
package com.singgel.threadPool;import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;public class BoundedThreadPool implements Runnable {public String name;public BoundedThreadPool(String name) {this.name = name;}@Overridepublic void run() {System.out.println(name);try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}public static void main(String[] args) {BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<>(3);ThreadPoolExecutor threadPool = new ThreadPoolExecutor(1, //核心池的大小。 当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中2, //线程池最大线程数,它表示在线程池中最多能创建多少个线程1L, //表示线程没有任务执行时最多保持多久时间会终止///TimeUnit.DAYS; //天//TimeUnit.HOURS; //小时//TimeUnit.MINUTES; //分钟//TimeUnit.SECONDS; //秒//TimeUnit.MILLISECONDS; //毫秒//TimeUnit.MICROSECONDS; //微妙//TimeUnit.NANOSECONDS; //纳秒TimeUnit.SECONDS, //参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:///ArrayBlockingQueue;//LinkedBlockingQueue;//SynchronousQueueworkQueue //一个阻塞队列,用来存储等待执行的任务);threadPool.execute(new BoundedThreadPool("任务1"));threadPool.execute(new BoundedThreadPool("任务2"));threadPool.execute(new BoundedThreadPool("任务3"));threadPool.execute(new BoundedThreadPool("任务4"));threadPool.execute(new BoundedThreadPool("任务5"));threadPool.execute(new BoundedThreadPool("任务6"));threadPool.shutdown();}}
执行结果是:且线程是两个两个执行的。
分析:线程池的corePoolSize为1,任务1提交后,线程开始执行,corePoolSize 数量用完,接着任务2、3、4提交,放到了有界队列中,此时有界队列也满了。继续提交任务5,由于当前运行的线程数poolSize < maximumPoolsize,线程池尝试new一个新的线程来执行任务5,所以任务5会接着执行。当继续提交任务6,时,poolSize达到了maximumPoolSize,有界队列也满了,所以线程池执行了拒绝操作。
二.无界队列
与有界队列相比,除非系统资源耗尽,否则无界的任务队列不存在任务入队失败的情况。当有新的任务到来,系统的线程数小于corePoolSize时,则新建线程执行任务。当达到corePoolSize后,就不会继续增加,若后续仍有新的任务加入,而没有空闲的线程资源,则任务直接进入队列等待。若任务创建和处理的速度差异很大,无界队列会保持快速增长,直到耗尽系统内存
package com.singgel.threadPool;import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;public class UnBoundedThreadPool implements Runnable {public Integer count;public UnBoundedThreadPool(Integer count) {this.count = count;}@Overridepublic void run() {System.out.println("任务" + count);try {Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}}public static void main(String[] args) throws InterruptedException {BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>();ThreadPoolExecutor pool = new ThreadPoolExecutor(5,10,1L,TimeUnit.SECONDS,workQueue);for (int i = 1; i <= 20; i++) {pool.execute(new UnBoundedThreadPool(i));}Thread.sleep(1000);System.out.println("线程池中队列中的线程数量:" + workQueue.size());pool.shutdown();}
}

如果修改了线程池的maximumPoolSize参数(大于corePoolSize的大小),程序执行结果不受影响。所以对于无界队列,maximumPoolSize的设置设置的再大对于线程的执行是没有影响的。Ps:这里说LinkedBlockingQueue是无界队列是不恰当的,只不过如果用无参构造函数初始化,默认的容量是Integer.MAX_VALUE
总结:
可以用以下一句总结:
当线程池的任务缓存队列已满并且线程池中的线程数目达到maximumPoolSize,如果还有任务到来就会采取任务拒绝策略。
这篇关于2、线程池ThreadPool有界、无界队列、同步队列以及5大参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




