本文主要是介绍(8)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题2】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章传送门
(1)工业界推荐系统-小红书推荐场景及内部实践【业务指标、链路、ItemCF】
(2)工业界推荐系统-小红书推荐场景及内部实践【UserCF、离线特征处理】
(3)工业界推荐系统-小红书推荐场景及内部实践【矩阵补充、双塔模型】
(4)工业界推荐系统-小红书推荐场景及内部实践【正负样本选择】
(5)工业界推荐系统-小红书推荐场景及内部实践【线上召回和模型更新】
(6)工业界推荐系统-小红书推荐场景及内部实践【其他召回通道】
(7)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题1】
该系列文章根据小红书搜推算法工程师、团队负责人王树森B站上主讲的《工业界的推荐系统》之小红书业务场景及内部实践整理而得。感谢大佬分享工业界前沿的推荐系统实战技术!
这篇文章讲解工业界推荐系统实践中对于冷启动问题的处理技巧,包括:冷启动评价指标、召回通道、聚类召回、Lookalike人群扩展、流量调控以及冷启动中的AB测试等。
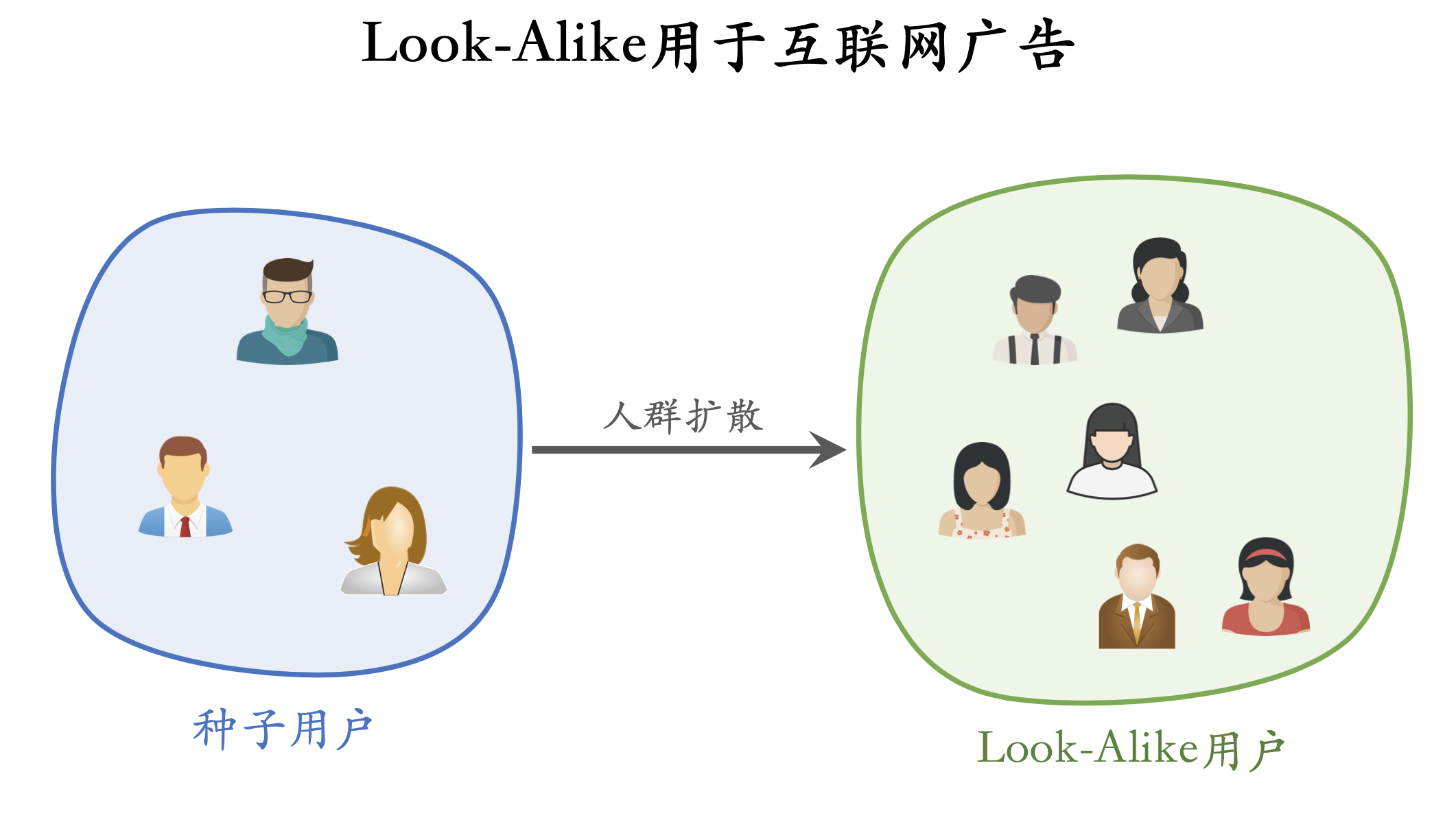
Lookalike 人群扩散
Look-Alike起源于互联网广告

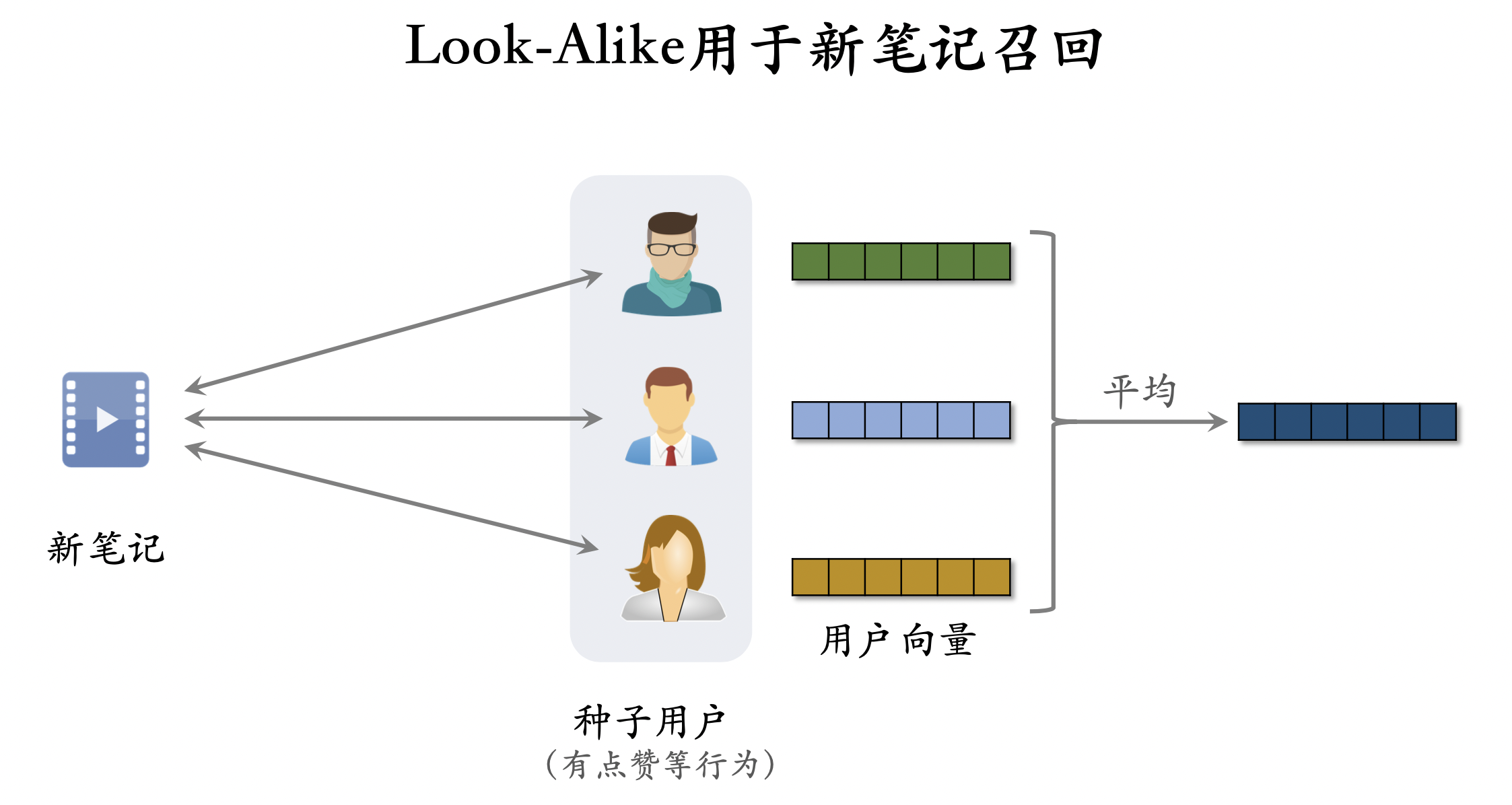
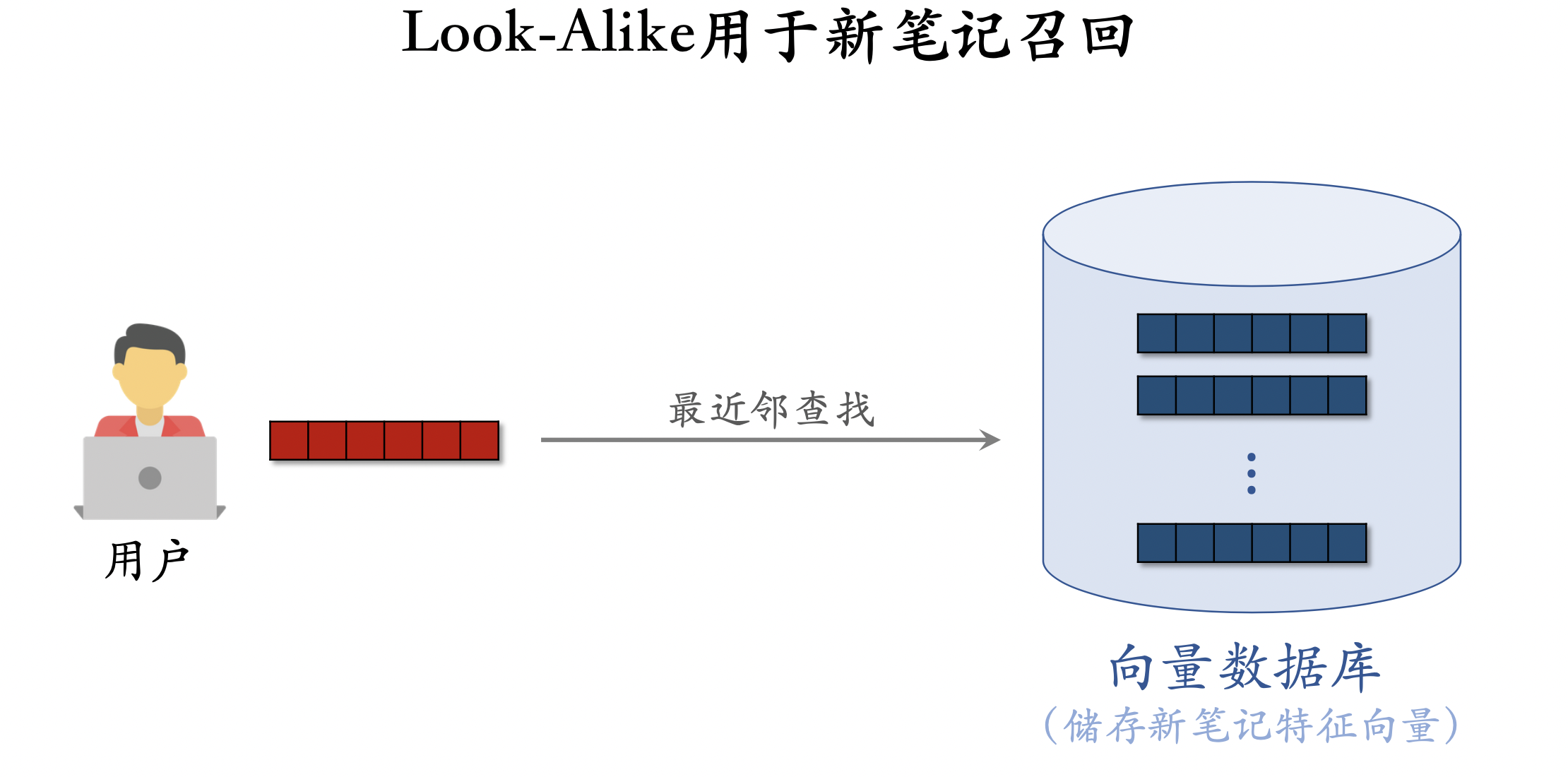
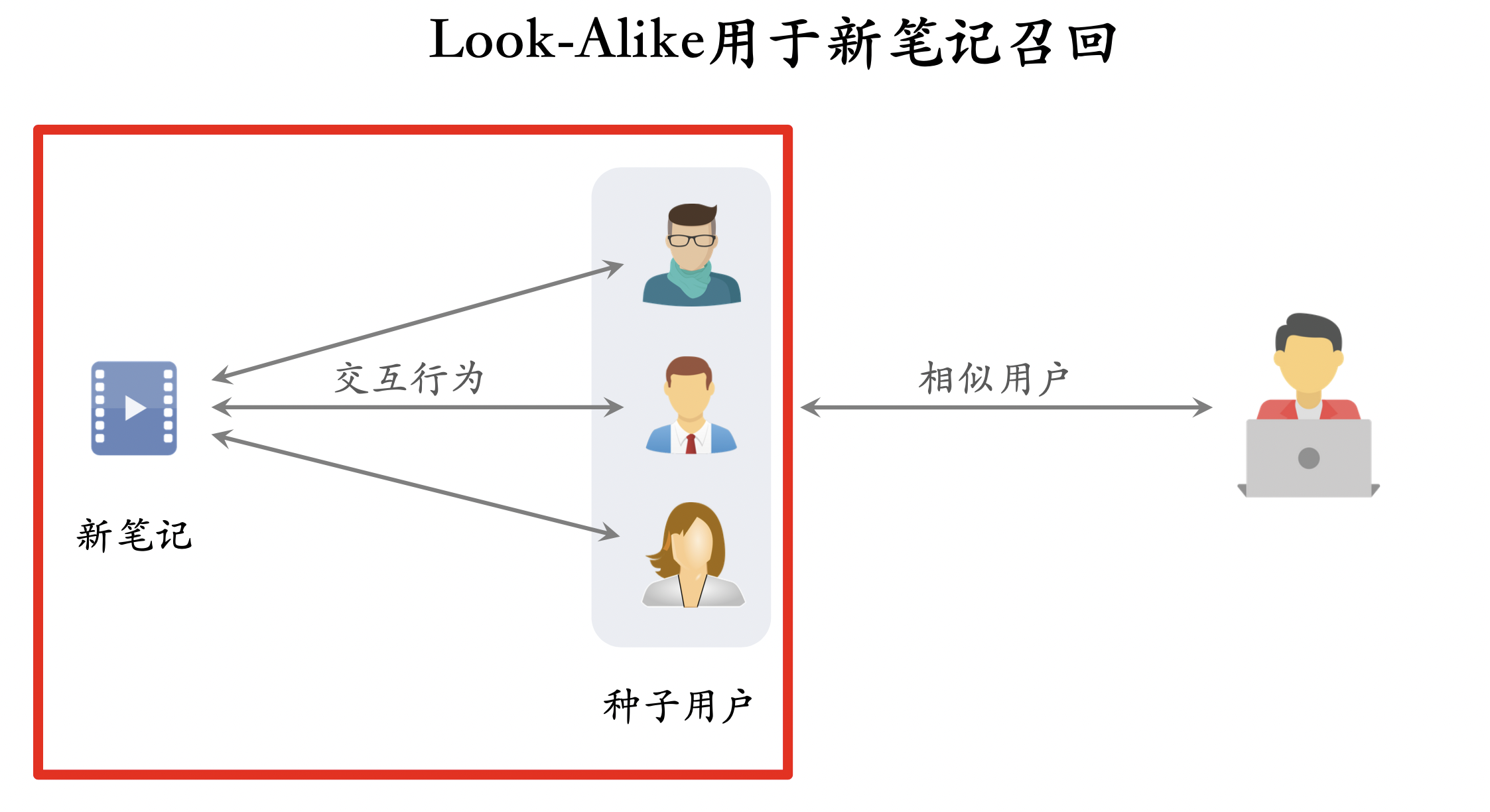
Look-Alike用于新笔记召回
Look-Alike人群扩散召回
- 点击、点赞、收藏、转发——用户对笔记可能感兴趣。
- 把有交互的用户作为新笔记的种子用户。
- 用 look-alike 在相似用户中扩散。

流量调控
冷启动的优化点
- 优化全链路(包括召回和排序)。
- 流量调控(流量怎么在新物品、老物品中分配)。
扶持新笔记的目的
- 目的1:促进发布,增大内容池。
- 新笔记获得的曝光越多,作者创作积极性越高。
- 反映在发布渗透率、人均发布量。
- 目的2:挖掘优质笔记。
- 做探索,让每篇新笔记都能获得足够曝光。
- 挖掘的能力反映在高热笔记占比。
工业界的做法
- 假设推荐系统只分发年龄 <30 天的笔记。
- 假设采用自然分发,新笔记(年龄 <24 小时)的曝光占比为 1/30。
- 扶持新笔记,让新笔记的曝光占比远大于 1/30。
流量调控技术的发展
- 在推荐结果中强插新笔记。
- 对新笔记的排序分数做提权(boost)。
- 通过提权,对新笔记做保量。
- 差异化保量。
新笔记提权
-
目标:让新笔记有更多机会曝光。
- 如果做自然分发,24小时新笔记占比为 1/30。
- 做人为干涉,让新笔记占比大幅提升。
-
干涉粗排、重排环节,给新笔记提权。
-
优点:容易实现,投入产出比好。
-
缺点:
- 曝光量对提权系数很敏感。
- 很难精确控制曝光量,容易过度曝光和不充分曝光。
新笔记保量
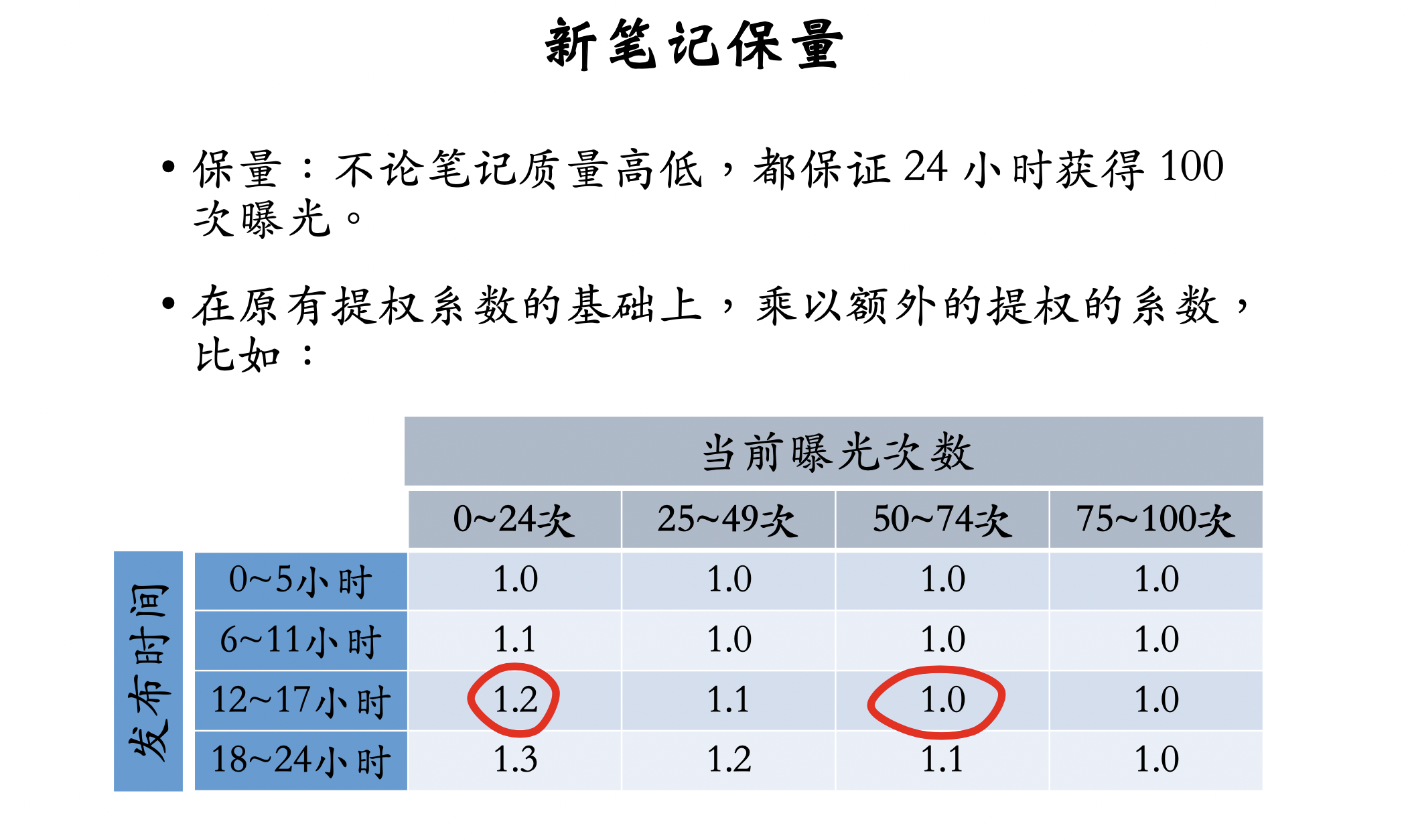

保量的难点
- 保量成功率远低于 100%。
- 很多笔记在24小时达不到100次曝光。
- 召回、排序存在不足。
- 提权系数调得不好。
- 线上环境变化会导致保量失败
- 线上环境变化:新增召回通道、升级排序模型、 改变重排打散规则…
- 线上环境变化后,需要调整提权系数。
- 思考题
- 给所有新笔记一个很大的提权系数(比如 4 倍), 直到达成 100 次曝光为止。
- 这样的保量成功率很高。
- 为什么不用这种方法呢?
- 给新笔记分数 boost 越多,对新笔记越有利?
- 好处:分数提升越多,曝光次数越多。
- 坏处:把笔记推荐给不太合适的受众。
- 点击率、点赞率等指标会偏低。
- 长期会受推荐系统打压,难以成长为热门笔记。
差异化保量
-
保量:不论新笔记质量高低,都做扶持,在前 24 小 时给 100 次曝光。
-
差异化保量:不同笔记有不同保量目标,普通笔记 保 100 次曝光,内容优质的笔记保 100~500 次曝光。
- 基础保量:24 小时 100 次曝光。
- 内容质量:用模型评价内容质量高低,给予额外保量目标,上限是加 200 次曝光。
- 作者质量:根据作者历史上的笔记质量,给予额外 保量目标,上限是加 200 次曝光。
- 一篇笔记最少有 100 次保量,最多有 500 次保量。
AB test
- 作者侧指标:
- 发布渗透率、人均发布量。
- 用户侧指标:
- 对新笔记的点击率、交互率。
- 大盘指标:消费时长、日活、月活。
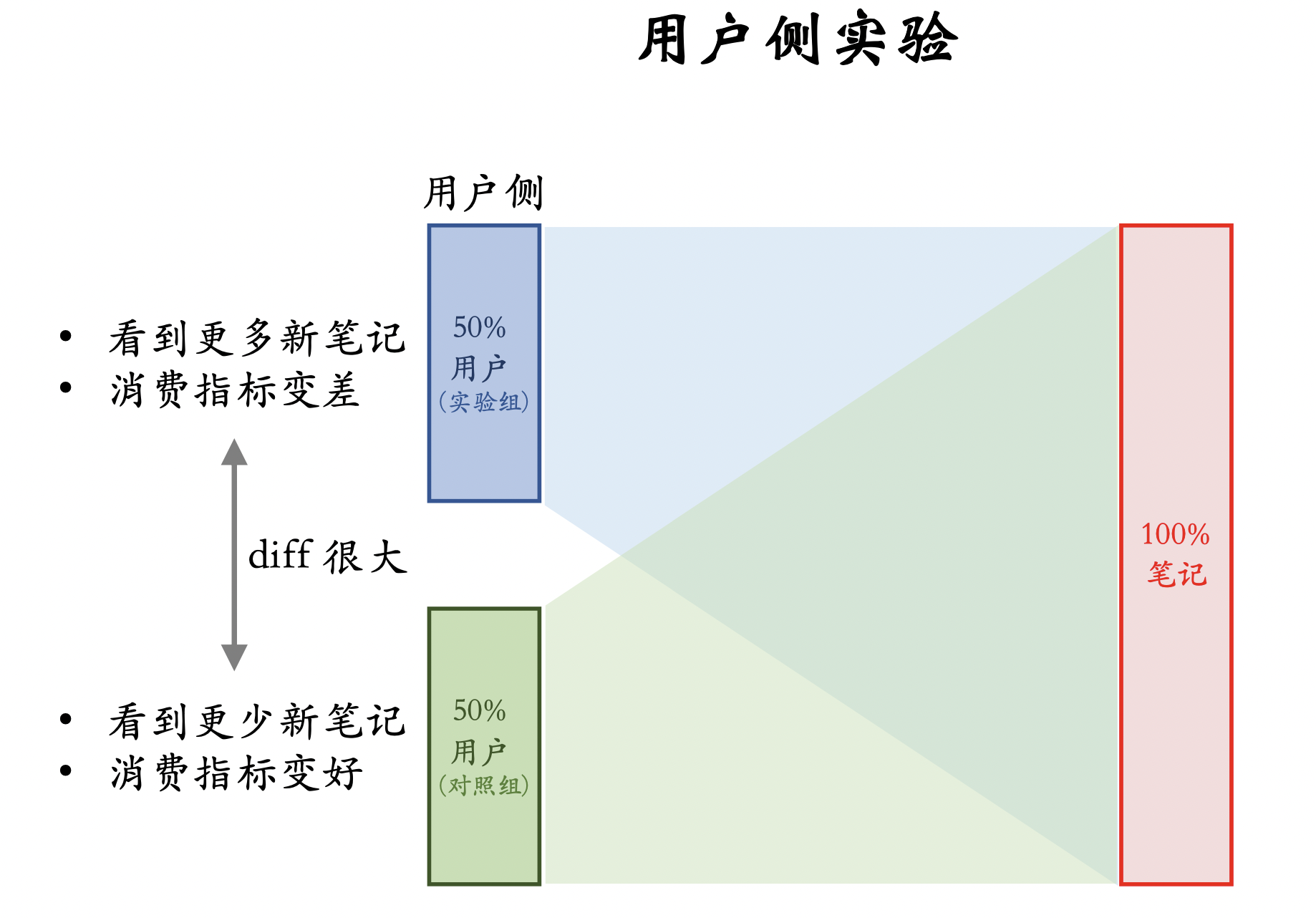
用户侧实验
缺点:
- 限定:保量 100 次曝光。
- 假设:新笔记曝光越多,用户使用APP时长越低。
- 新策略:把新笔记排序时的权重增大两倍。
- 结果(只看消费指标):
- AB测试的diff是负数(策略组不如对照组)。
- 如果推全,diff会缩小(比如 −2%à−1%)。
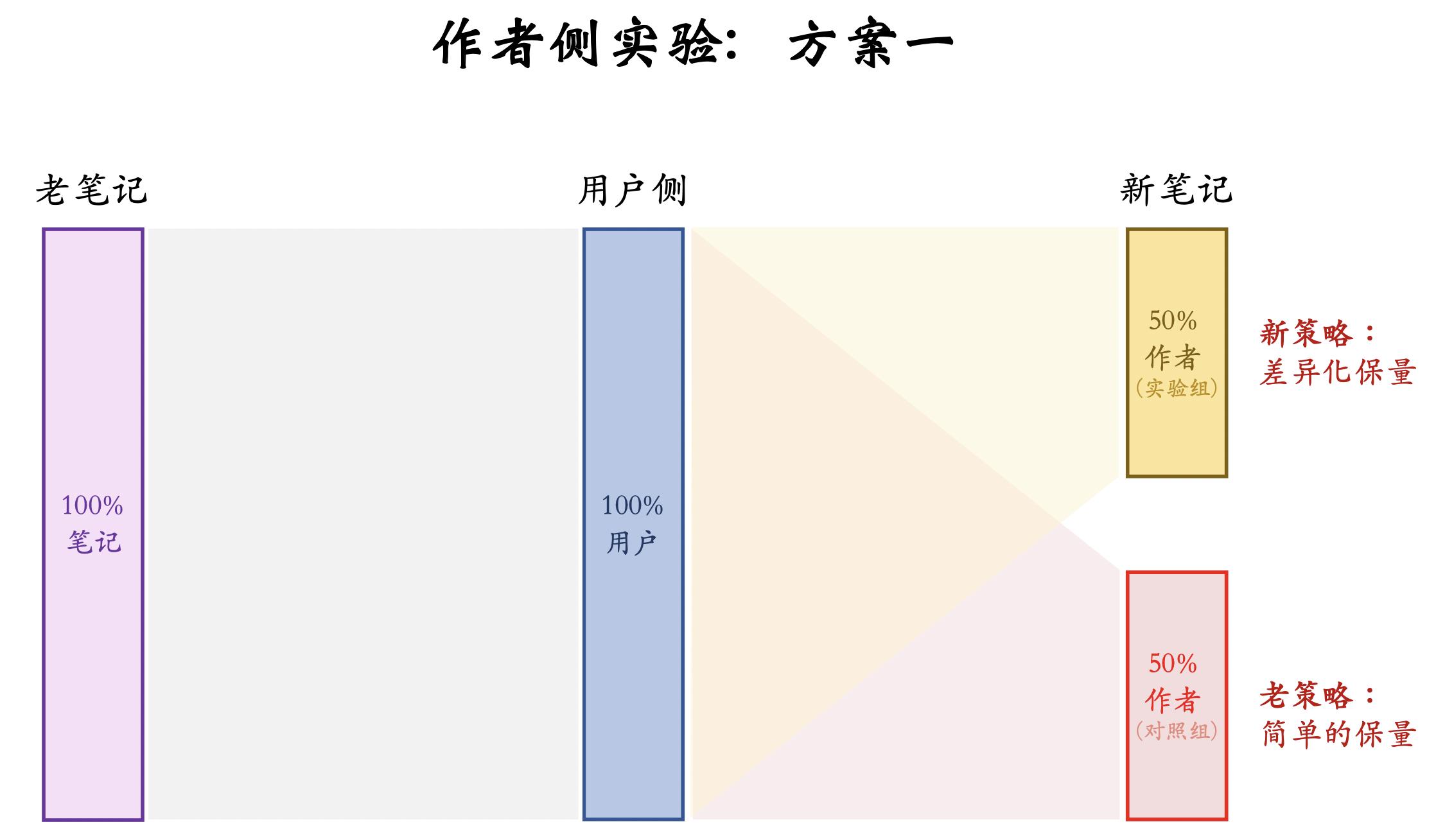
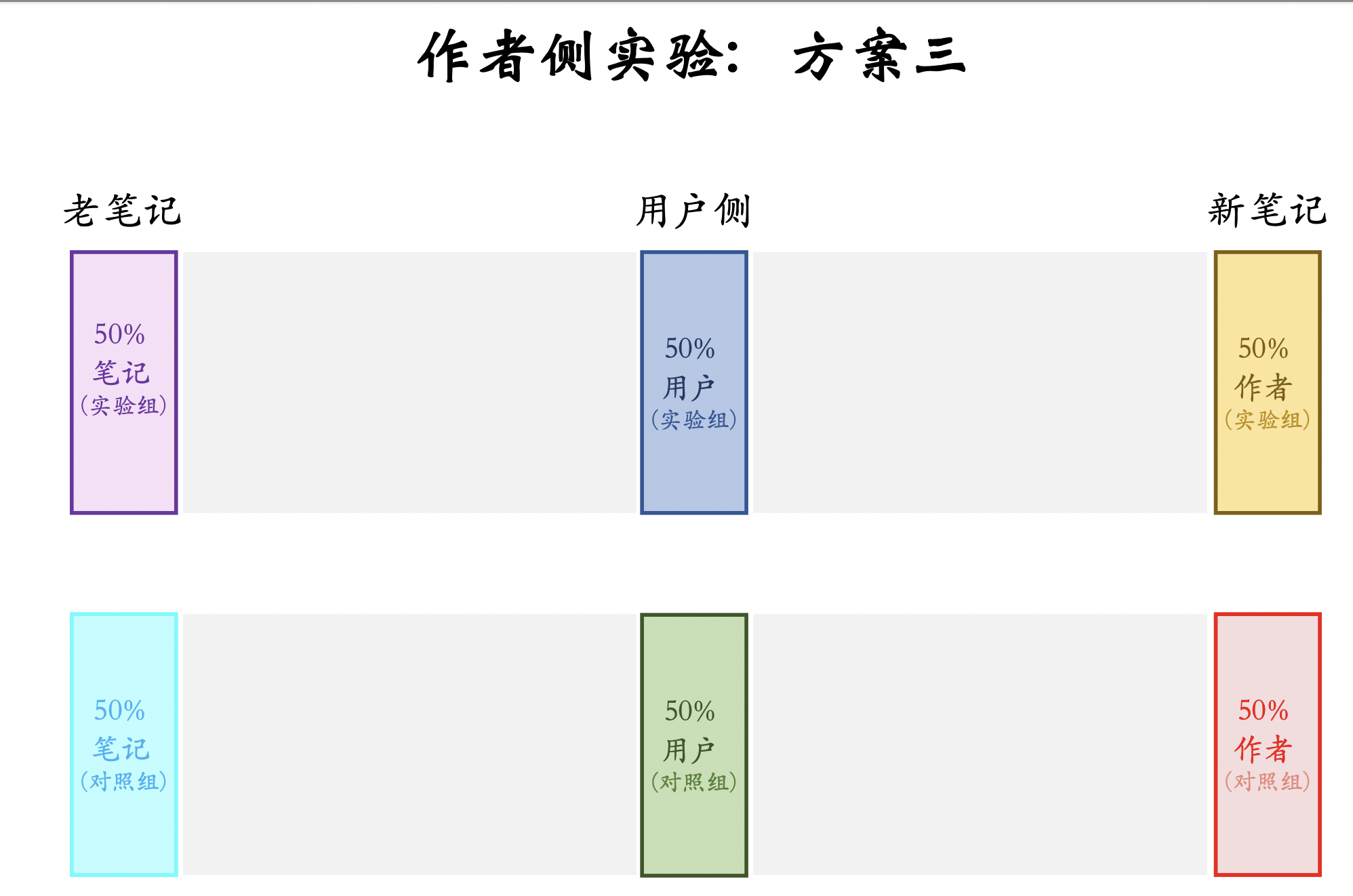
作者侧实验





这篇关于(8)工业界推荐系统-小红书推荐场景及内部实践【冷启动问题2】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





