本文主要是介绍解决从网页复制代码带有多余行号问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们在 Web 上找到一份很好的教程时,往往喜欢复制或者保存他人提供的代码。但是,有些网页带有自动编号功能,这会使得复制的文本处理起来比较麻烦。
例如下面的这段网页代码:

我们观察到每一行左侧都有行号的编号,我们在复制到 txt 中时候,会出现多余行号和前缀空格。
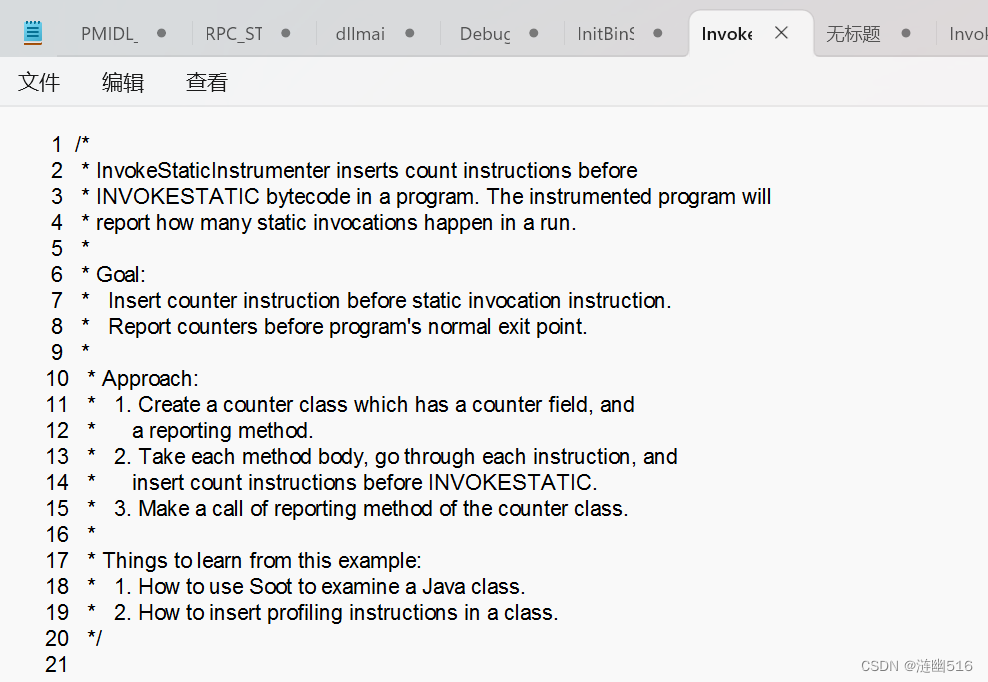
我们不需要这样,但是手动去除会很麻烦且容易出错。
那我们该怎么办呢?
这时候,我想到了写一个脚本去自动化处理。下面是自动化处理的 python 代码:
def remove_line_numbers_and_prefix_spaces_from_java_file(filename):try:with open(filename, 'r') as file:lines = file.readlines() # 读取文件中的所有行except FileNotFoundError:print(f"Error: File '{filename}' not found.")return Nonecleaned_lines = []for line in lines:# 如果行只包含数字和空格,则直接跳过if line.strip().isdigit() or line.strip() == "":cleaned_lines.append('\n')continue# 去除行号和前缀空格,保留正确的缩进cleaned_line = line.lstrip(' ').split(' ', 1)[-1] # 去除行首空格并从第一个空格开始切割cleaned_lines.append(cleaned_line)cleaned_code = ''.join(cleaned_lines) # 将处理后的行重新组合成代码return cleaned_code# 用户输入要处理的文件名和新文件名
filename = input("Enter the filename to process: ")
output_filename = input("Enter the output filename to write cleaned code: ")cleaned_code = remove_line_numbers_and_prefix_spaces_from_java_file(filename)
if cleaned_code:print("Cleaned code:")print(cleaned_code)# 将处理后的代码写入新文件try:with open(output_filename, 'w') as output_file:output_file.write(cleaned_code)print(f"Cleaned code written to '{output_filename}'.")except IOError:print(f"Error writing to file '{output_filename}'.")
运行这个脚本并输入要处理的文件以及输出文件路径。你将得到一份干净的代码。
目前此程序适用于处理标准的 Java 代码,是否有特殊情况导致出错的我暂时还没遇到。
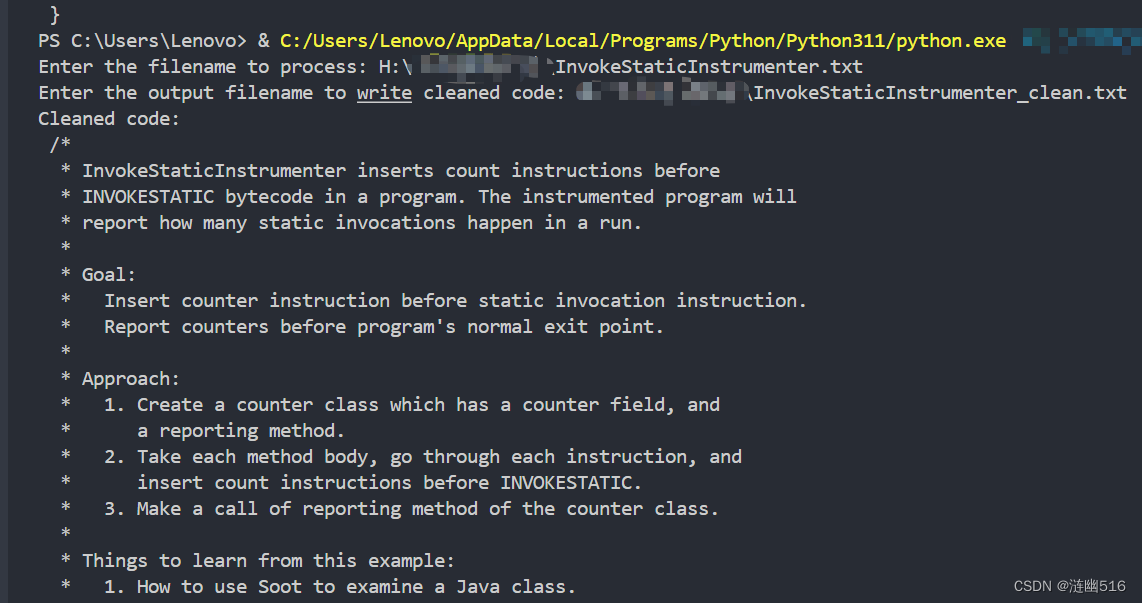
我们看一下生成的效果,非常棒,我也很喜欢。

本文发布于:2024.03.23.
这篇关于解决从网页复制代码带有多余行号问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







