本文主要是介绍PointNet++论文复现(一)【PontNet网络模型代码详解 - 分类部分】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PontNet网络模型代码详解 - 分类部分
专栏持续更新中!关注博主查看后续部分!
分类模型的训练:
## e.g., pointnet2_ssg without normal features
python train_classification.py --model pointnet2_cls_ssg --log_dir pointnet2_cls_ssg
python test_classification.py --log_dir pointnet2_cls_ssg
训练和测试
知识补充
PyTorch中,nn.Conv1d和nn.Conv2d是卷积神经网络(CNN)的基本构建模块。用于处理一维和二维数据。
nn.Conv1d的参数:in_channels (int):输入信号的通道数。out_channels (int):卷积产生的通道数(即卷积核的数量)。kernel_size (int or tuple):卷积核的大小。stride (int or tuple, optional):卷积步长。padding (int or tuple, optional):输入数据两侧的填充数。dilation (int or tuple, optional):卷积核元素之间的间距。groups (int, optional):连接输入和输出通道的分组数。bias (bool, optional):是否添加偏置项。一维卷积示例:
import torchimport torch.nn as nnbatchSize=2num_features=3 # X,Y,Znum_point=4input=torch.ones(batchSize,num_features,num_point)x1=torch.Tensor([1,2,3,1]).reshape(1,4)input=torch.mul(x1,input)conv1=nn.Conv1d(3,5,1)y=conv1(input)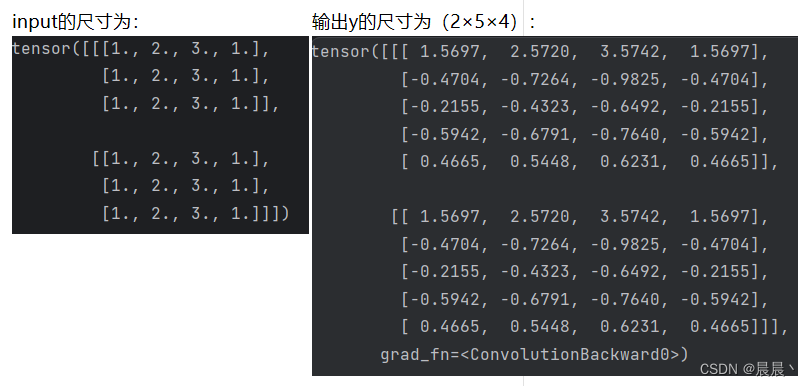
权重共享是卷积神经网络(CNN)的一个关键特性,尤其在处理图像、音频和文本等数据时非常重要。在一维卷积(Conv1D)的上下文中,权重共享具体意味着卷积层中的每个卷积核(或滤波器)在整个输入序列上滑动时使用相同的权重。
权重共享的含义
1、减少参数数量:在传统的全连接网络中,每个输入单元与每个输出单元之间都有一个独立的权重,导致参数数量随输入和输出大小的增长而急剧增加。在卷积网络中,由于使用了权重共享,同一个卷积核在不同位置的计算重复使用相同的权重,大大减少了模型的参数数量。
2、提高效率:权重共享不仅减少了模型的存储需求,也提高了计算效率,因为它减少了需要学习的参数数量。这使得卷积网络能够更快地训练,并减少了过拟合的风险。
3、捕捉局部特征:卷积操作通过卷积核在输入序列上的滑动来捕捉局部特征。权重共享保证了模型在整个序列的不同位置以相同的方式响应相似的模式或特征(输出特征的某一通道数值由一组权重(核)来决定,即该通道的所有值都共享同一组权重),这对于处理图像、音频和序列数据非常有用,因为这些类型的数据通常包含重复出现的局部模式。
一维卷积层和全连接层的区别
权重共享的一维卷积(Conv1D)层和全连接(Fully Connected,FC)层在结构和功能上有显著的区别,这些区别影响了它们在处理数据时的效率和适用性。以下是这两种网络层之间的主要区别:
权重共享与参数数量
权重共享的Conv1D层:在一维卷积层中,同一个卷积核(一组权重)在整个输入序列上滑动以提取特征,这意味着相同的权重被用于输入的不同部分。这种权重共享显著减少了模型的参数数量,因为不需要为输入数据的每个不同位置学习一组独立的权重。
全连接层:在全连接层中,每个输入单元都与每个输出单元连接,并且每个连接都有一个独立的权重。这意味着FC层的参数数量随输入和输出单元的数量线性增长,对于大型数据集或高维数据,会导致参数数量非常庞大,增加了计算成本和过拟合的风险。
局部连接与全局连接
Conv1D层:卷积操作侧重于提取输入序列的局部特征。每个卷积核在输入上滑动,只关注输入的一个局部区域,这有助于捕捉如边缘、纹理等局部模式,这对于时间序列分析、音频处理和文本处理等任务非常有效。
全连接层:在全连接层中,每个输入都与输出的每个单元连接,这意味着全连接层在处理输入时考虑了所有的全局信息。这使得FC层能够学习输入单元之间的复杂和非局部的关系,但也使其对于高维数据效率低下。
参数共享与空间不变性
Conv1D层的参数共享:通过在整个输入序列上重复使用相同的权重,卷积层能够对输入数据的平移表现出某种程度的不变
这篇关于PointNet++论文复现(一)【PontNet网络模型代码详解 - 分类部分】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







