本文主要是介绍Deep_Learning_readme,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文目录
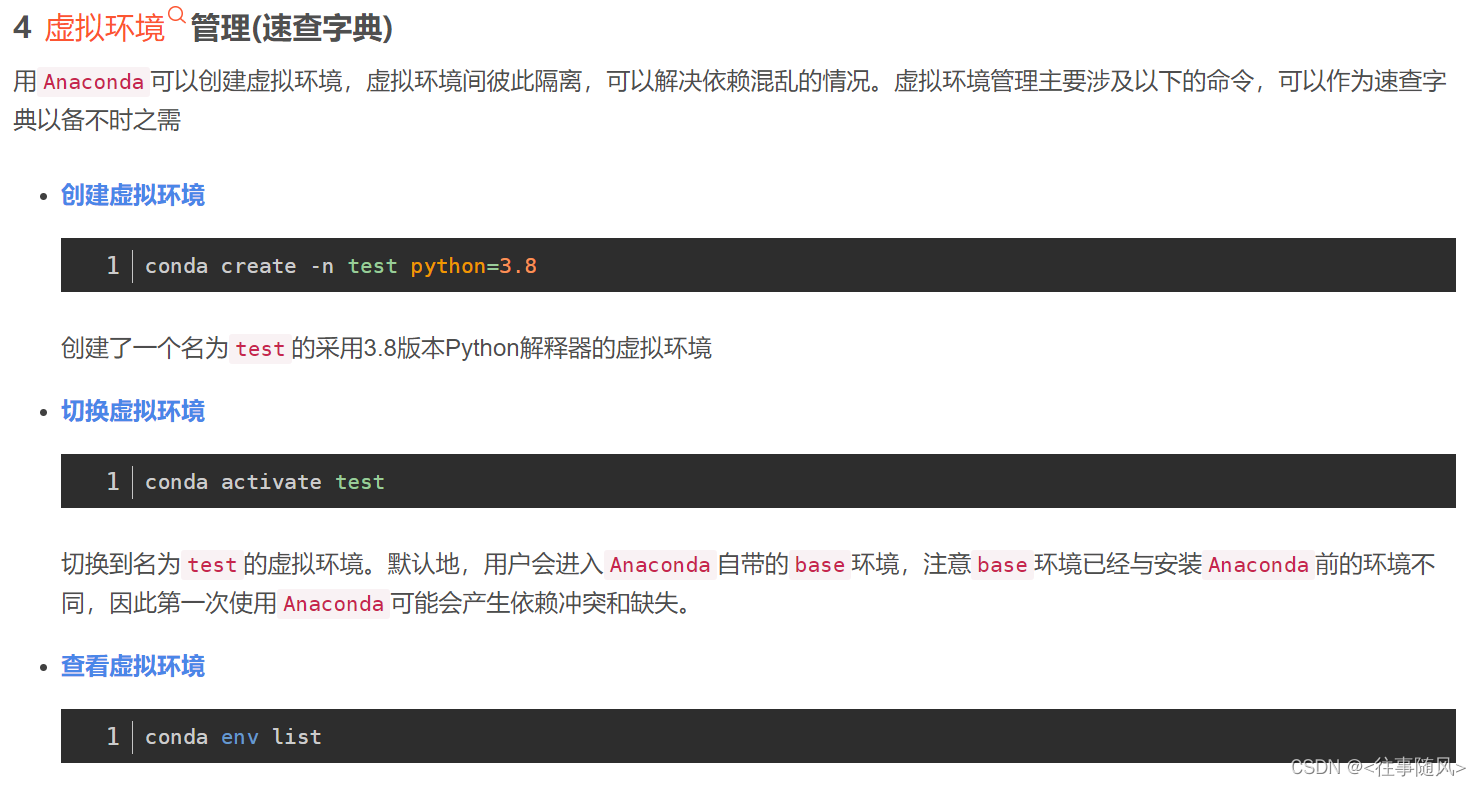
- 1.环境安装
- 2. A1-1实验:
- 3. A1-2实验:
- 4. A1-3实验 :
- **5. A2-CNN实验**
- **6. A3-RNN实验**
!!!!!!!!提示:全程路径和环境名字不要出现中文及中文符号若安装过程出现错误,大家将错误信息复制到百度查询解决即可!!!!!!!!!!
1.环境安装
首先进行环境的安装,推荐安装Anaconda,Anaconda中包含了conda等180多个科学包及其依赖项。其中conda则是一个开源的软件包管理系统和环境管理系统,用于安装多个版本的软件包及其依赖关系,并在它们之间轻松切换。方便我们进行环境管理。
大家根据自己系统,按照下面博文进行安装就行。
Anaconda安装与Python虚拟环境配置保姆级图文教程
若安装过程出现错误,大家将错误信息复制到百度查询解决即可。一直到下面这一步就行,后面的步骤不用做。
其中的test可以自拟(不要中文),其为环境变量名
 接下来开始实验部分讲解。
接下来开始实验部分讲解。
2. A1-1实验:
首先将老师给的文件夹解压,并打开Jupyter Notebook (Anaconda3)
进入之后是个网页,点击右上角upload
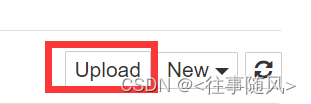
将老师给的A1-1.ipynb文件导入,然后运行代码即可。
3. A1-2实验:
进行A1-2实验之前,我们需要安装torch这个库。首先打开这个终端

输入指令
conda activate test
推荐博文
在anaconda下安装pytorch + python3.8+GPU/CPU版本 详细教程
由于部分同学电脑没有显卡,且各个同学系统也不一致,因此大家根据需求安装GPU 或CPU版本即可。CPU安装过程较简单,GPU安装过程较繁琐。
我们均从博文的第五小节开始操作,因为前面流程我们已经配置完成。
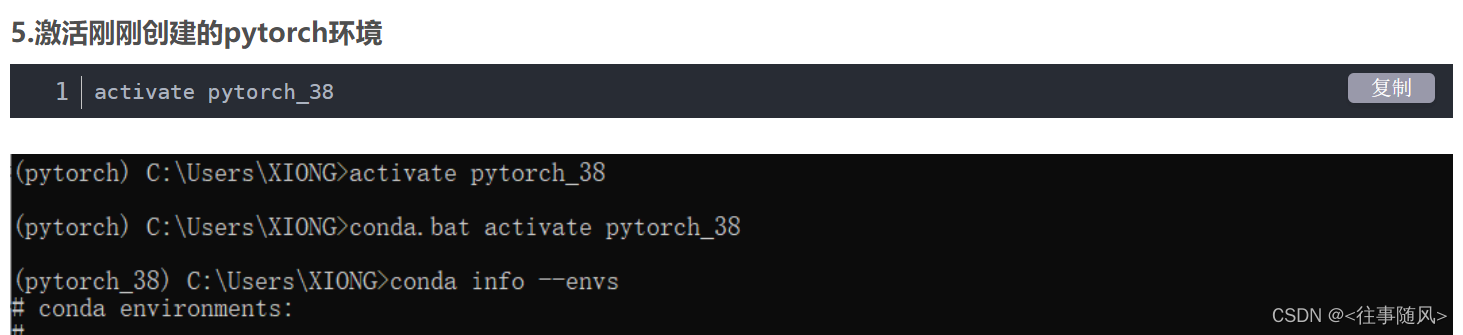
其中的pytorch_38就是我们的test环境。根据自己配置的名字来就行。torch安装完成后,我们按照A1-1的步骤将其导入Jupyter Notebook运行即可。
4. A1-3实验 :
由于本实验还需要tensorflow,torchvision以及timeit这3个库,因此我们需要进行安装。
打开终端,
对于CPU版本的同学我们分别执行以下命令:
pip install torchvisionpip install timeitpip install tensorflow==2.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
对于GPU版本的同学安装torchvision我们参考以下博文,注意一下版本对应关系就行。
在Anaconda中创建虚拟环境安装GPU版本的Pytorch及torchvision并在VsCode中使用虚拟环境
在第五章节,推荐使用5.2 离线安装,而不是在线安装,否则会出现一些bug。
对于GPU版本的同学安装tensorflow我们参考以下博文,注意一下版本对应关系就行。
tensorflow安装步骤(GPU版本,Anaconda环境下,Windows10)
接着我们直接打开jupyternotebook直接导入,运行代码即可。
5. A2-CNN实验
这个实验用到的依赖库我们已经安装完成,因此直接导入,运行代码就行。
6. A3-RNN实验
这篇关于Deep_Learning_readme的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









