本文主要是介绍ShuffleNet模型详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ShuffleNet论文地址:1707.01083.pdf (arxiv.org)
ShuffleNetv2论文地址:1807.11164.pdf (arxiv.org)
ShuffleNetv1
简介
ShuffleNet 是专门为计算能力非常有限的移动设备设计的。架构采用了逐点分组卷积和通道shuffle两种新的运算,在保持精度的同时大大降低了计算成本。ShuffleNet 比 MobileNet 在 ImageNet 分类任务上的 top-1误差更低 (绝对7.8%) ,在基于arm的移动设备上,ShuffleNet比AlexNet实现了约13倍的实际加速,同时保持了相当的准确性。
逐点分组卷积
作者注意到最先进的基础架构,如Xception和ResNeXt,在极小的网络中变得效率较低,因为密集1 × 1卷积代价很昂贵。为减少1 × 1卷积的计算复杂度。克服逐点分组卷积带来的副作用,提出了一种新的通道洗牌操作,以帮助信息在特征通道之间流动。
Channel Shuffle
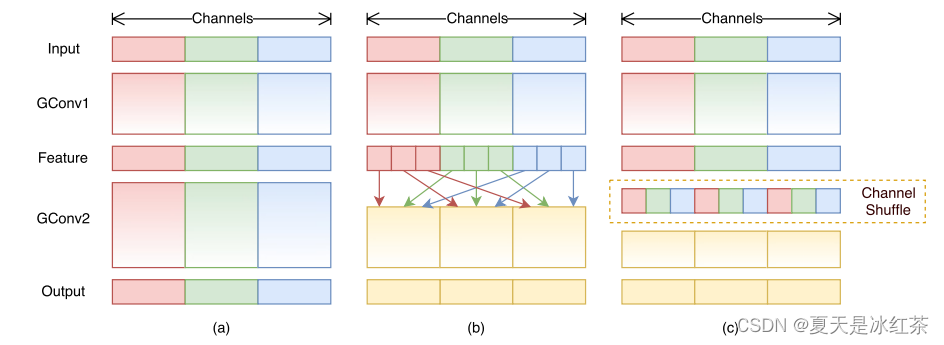
使用 1 × 1 卷积核进行操作时的复杂度较高,因为需要和每个像素点做互相关运算,所以这会消耗大量资源,所以作者提出将这一层也设计为分组卷积的的形式,但它只在组内进行卷积,为了使得信息在组之间流动,作者提出将每次分组卷积后的结果进行组内分组,再互相交换各自的组内的子组,通过Channel Shuffle允许分组卷积从不同的组中获取输入数据,从而实现输入通道和输出通道相关联 。这种相关联有助于增加网络的非线性,提高网络的表征能力。
def channel_shuffle(x, groups):batchsize, num_channels, height, width = x.size()channels_per_group = num_channels // groupsx = x.view(batchsize, groups, channels_per_group, height, width) # reshapex = torch.transpose(x, 1, 2).contiguous()x = x.view(batchsize, num_channels, height, width) # flattenreturn x这一个过程很好实现,我们只需要先将总通道数除以组数,计算每个组中的通道数,然后使用torch.transpose函数交换第二维和第三维,以实现通道混洗。
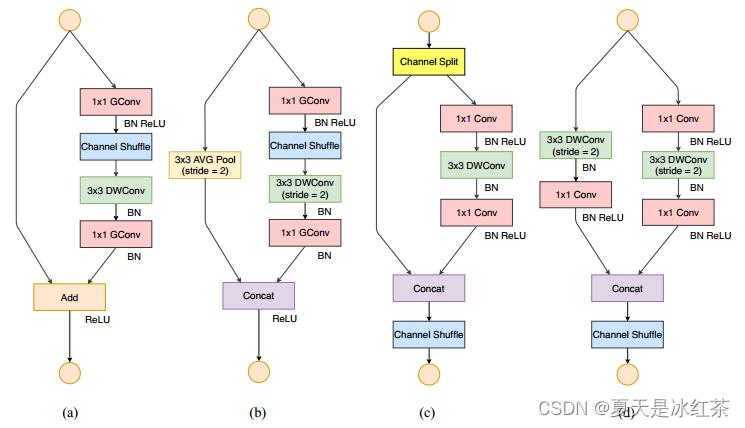
ShuffleNet unit
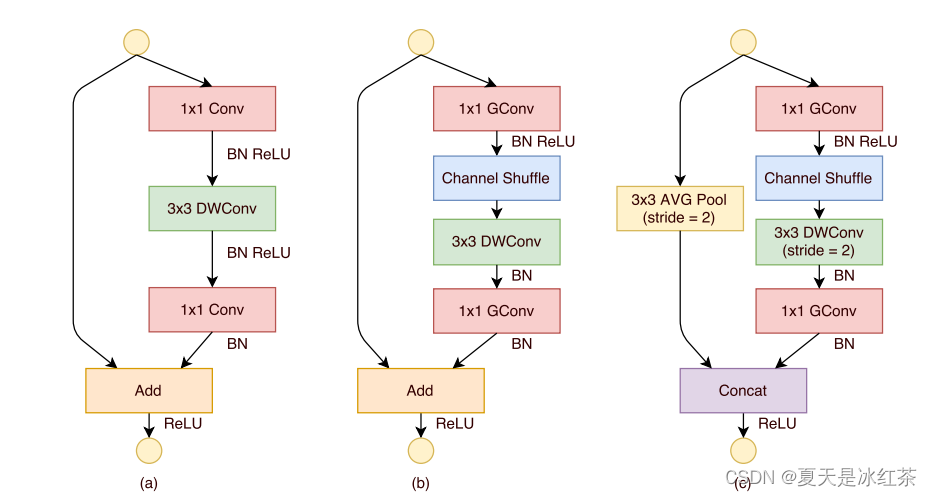
我们关注(b)和(c),因为(a)就是一个将DW卷积替换3x3卷积的瓶颈结构,后面两种在GConv与DWConv之间进行了通道洗牌。唯一不同的是(c)满足的是stride=2的情况,现在我们先将其组合在一起。
class shufflenet_units(nn.Module):"""可参考 <https://arxiv.org/pdf/1707.01083.pdf> Figure2 (b) and (c)"""def __init__(self, in_channels, out_channels, stride, groups):super(shufflenet_units, self).__init__()mid_channels = out_channels // 4self.stride = strideself.groups = 1 if in_channels == 24 else groupsself.GConv1 = nn.Sequential(nn.Conv2d(in_channels, mid_channels, kernel_size=1, stride=1, groups=self.groups, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True))self.DWConv = nn.Sequential(nn.Conv2d(mid_channels, mid_channels, kernel_size=3, stride=self.stride, padding=1, groups=self.groups, bias=False),nn.BatchNorm2d(mid_channels))self.GConv2 = nn.Sequential(nn.Conv2d(mid_channels, out_channels, kernel_size=1, stride=1, groups=self.groups, bias=False),nn.BatchNorm2d(out_channels))self.shortcut = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):out = self.GConv1(x)out = channel_shuffle(out, groups=self.groups)out = self.DWConv(out)out = self.GConv2(out)if self.stride == 2:short_out = self.shortcut(x)out = torch.cat([out, short_out], dim=1)return self.relu(out)这里就能通过判断stride是否为2来决定是否进行下采样操作,并将下采样结果与输出特征图进行拼接。我觉得我这里实现的还是相当完美的。
ShuffleNetv1网络搭建
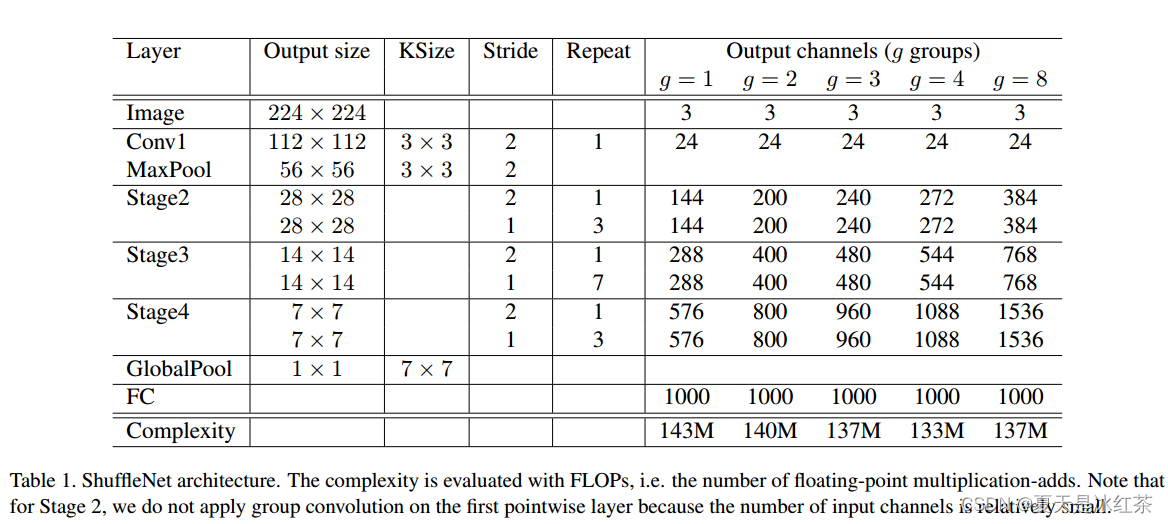
虽然作者没有提供源码,但是想要实现还是比较容易的,可以看到Stage2,Stage3,Stage4有共有的特点,比如在每个stage的repeat阶段都先进行一次Stride=2的操作,所以这里完全可以参考torch官方实现VGG的方式去写,只不过说这里的方式比较固定罢了。
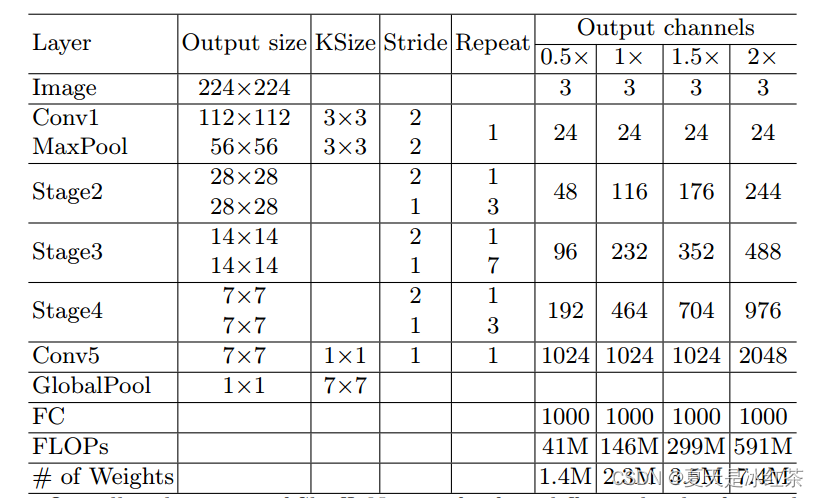
class ShuffleNetV1(nn.Module):"""参考 <https://arxiv.org/pdf/1707.01083.pdf> Table 1 实现根据论文所述 —— 组数越小表示性能越好"""def __init__(self, groups, stages_out_channels, num_classes=1000, repeat_layers=(4, 8, 4)):super(ShuffleNetV1, self).__init__()self.groups = groupsself.conv1 = nn.Sequential(nn.Conv2d(3, 24, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(24),nn.ReLU(inplace=True),)self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.stage2 = self._make_layers(24, stages_out_channels[0], repeat_layers[0], groups)self.stage3 = self._make_layers(stages_out_channels[0], stages_out_channels[1], repeat_layers[1], groups)self.stage4 = self._make_layers(stages_out_channels[1], stages_out_channels[2], repeat_layers[2], groups)self.globalpool = nn.AvgPool2d(kernel_size=7, stride=1)self.fc = nn.Linear(num_channels[2], num_classes)def _make_layers(self, in_channels, out_channels, repeat_number, groups):layers = []# 不同的 stage 阶段在第一步都是 stride = 2layers.append(shufflenet_units(in_channels, out_channels - in_channels, 2, groups))in_channels = out_channelsfor i in range(repeat_number - 1):layers.append(shufflenet_units(in_channels, out_channels, 1, groups))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.max_pool(x)x = self.stage2(x)x = self.stage3(x)x = self.stage4(x)x = self.globalpool(x)x = torch.flatten(x, 1)out = self.fc(x)return outcfg_with_shufflenet = {'g1': [144, 288, 576],'g2': [200, 400, 800],'g3': [240, 480, 960],'g4': [272, 544, 1088],'g8': [384, 768, 1536],'x0_5': [24, 48, 96, 192, 1024],'x1_0': [24, 116, 232, 464, 1024],'x1_5': [24, 176, 352, 704, 1024],'x2_0': [24, 244, 488, 976, 2048],
}def shufflenet_v1_g1(num_classes):return ShuffleNetV1(groups=1,stages_out_channels=cfg_with_shufflenet['g1'],num_classes=num_classes)def shufflenet_v1_g2(num_classes):return ShuffleNetV1(groups=2,stages_out_channels=cfg_with_shufflenet['g2'],num_classes=num_classes)def shufflenet_v1_g3(num_classes):return ShuffleNetV1(groups=3,stages_out_channels=cfg_with_shufflenet['g3'],num_classes=num_classes)def shufflenet_v1_g4(num_classes):return ShuffleNetV1(groups=4,stages_out_channels=cfg_with_shufflenet['g4'],num_classes=num_classes)def shufflenet_v1_g8(num_classes):return ShuffleNetV1(groups=8,stages_out_channels=cfg_with_shufflenet['g8'],num_classes=num_classes)
经过实验测试,下面是我打印出来的模型参数。
shufflenet_v1_g1 Total params: 1,880,296
shufflenet_v1_g2 Total params: 1,834,852
shufflenet_v1_g3 Total params: 1,781,032
shufflenet_v1_g4 Total params: 1,734,136
shufflenet_v1_g8 Total params: 1,797,304
根据论文所述,组数越小表示性能越好,就是说shufflenet_v1_g1的性能应该是最好的。
ShuffleNetv2
有效网络设计的实用指南
G1) 相等的通道宽度最小化内存访问成本(MAC)
目前网络通常采用深度可分离卷积,其中点向卷积(即1 × 1卷积)占据了大部分复杂度。而1 × 1卷积的核形状由两个参数指定:输入通道数和输出通道数
。设h和w为特征映射的空间大小,则1 × 1卷积的FLOPs为
。
这里可由不等式:
则=
可推出
论文中也给出了实验数据:
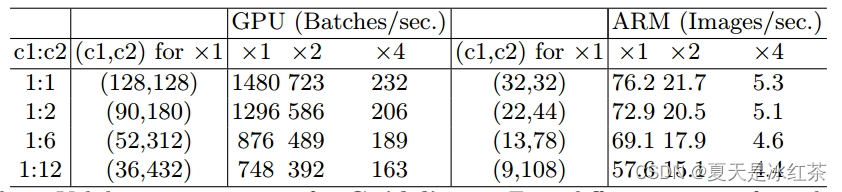
得出时,网络处理的速度最快。
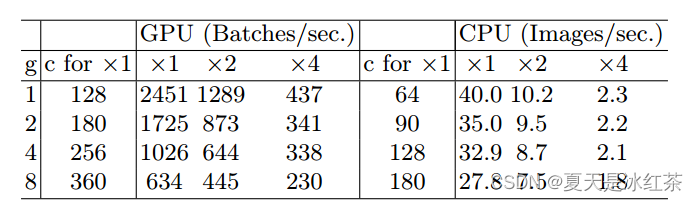
G2) 过多的分组卷积增加MAC
FLOPs为推出
,
同样的,论文中对这部分也做了一系列的对照实验,可以看见g越高,网络的处理速度越慢。
G3) 网络碎片降低了并行度
这部分没有公式佐证,但这种碎片化结构已被证明有利于准确性,但它可能会降低效率,因为它对GPU等具有强大并行计算能力的设备不友好。它还引入了额外的开销,例如内核启动和同步。在ARM上,速度降低相对较小。
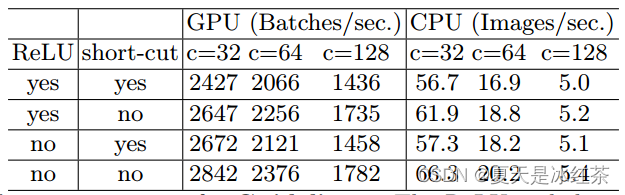
G4) 逐元素操作带来的内存和耗时不可忽略
元素操作占用了相当多的时间,特别是在GPU上。这里,元素操作符包括ReLU、AddTensor、AddBias等。它们具有较小的FLOPs,但相对较重的MAC。特别地,我们还考虑深度卷积作为元素明智的运算符,因为它也具有较高的MAC/FLOPs比率。
基于上述指导方针和实证研究,一个高效的网络架构应具备
- 使用输入输出通道相同的卷积
- 了解使用分组卷积的代价,合理的设定分组个数
- 降低网络并行的分支
- 减少逐点运算
ShuffleNetv2网络搭建
下面是全部实现的代码
"""
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices<https://arxiv.org/pdf/1707.01083.pdf>
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design<https://arxiv.org/pdf/1807.11164.pdf>
"""
import torch
import torch.nn as nn__all__ = ["ShuffleNetV1", "shufflenet_v1_g1", "shufflenet_v1_g2", "shufflenet_v1_g3","shufflenet_v1_g4", "shufflenet_v1_g8", "ShuffleNetV2", "shufflenet_v2_x0_5","shufflenet_v2_x1_0", "shufflenet_v2_x1_5", "shufflenet_v2_x2_0",]cfg_with_shufflenet = {'g1': [144, 288, 576],'g2': [200, 400, 800],'g3': [240, 480, 960],'g4': [272, 544, 1088],'g8': [384, 768, 1536],'x0_5': [24, 48, 96, 192, 1024],'x1_0': [24, 116, 232, 464, 1024],'x1_5': [24, 176, 352, 704, 1024],'x2_0': [24, 244, 488, 976, 2048],
}def channel_shuffle(x, groups):"""Shufflenet uses channel shuffling"""batchsize, num_channels, height, width = x.size()channels_per_group = num_channels // groupsx = x.view(batchsize, groups, channels_per_group, height, width) # reshapex = torch.transpose(x, 1, 2).contiguous()x = x.view(batchsize, num_channels, height, width) # flattenreturn xclass shufflenet_units(nn.Module):"""可参考 <https://arxiv.org/pdf/1707.01083.pdf> Figure2 (b) and (c)"""def __init__(self, in_channels, out_channels, stride, groups):super(shufflenet_units, self).__init__()mid_channels = out_channels // 4self.stride = strideself.groups = 1 if in_channels == 24 else groupsself.GConv1 = nn.Sequential(nn.Conv2d(in_channels, mid_channels, kernel_size=1, stride=1, groups=self.groups, bias=False),nn.BatchNorm2d(mid_channels),nn.ReLU(inplace=True))self.DWConv = nn.Sequential(nn.Conv2d(mid_channels, mid_channels, kernel_size=3, stride=self.stride, padding=1, groups=self.groups, bias=False),nn.BatchNorm2d(mid_channels))self.GConv2 = nn.Sequential(nn.Conv2d(mid_channels, out_channels, kernel_size=1, stride=1, groups=self.groups, bias=False),nn.BatchNorm2d(out_channels))self.shortcut = nn.AvgPool2d(kernel_size=3, stride=2, padding=1)self.relu = nn.ReLU(inplace=True)def forward(self, x):out = self.GConv1(x)out = channel_shuffle(out, groups=self.groups)out = self.DWConv(out)out = self.GConv2(out)if self.stride == 2:short_out = self.shortcut(x)out = torch.cat([out, short_out], dim=1)return self.relu(out)class ShuffleNetV1(nn.Module):"""参考 <https://arxiv.org/pdf/1707.01083.pdf> Table 1 实现根据论文所述 —— 组数越小表示性能越好"""def __init__(self, groups, stages_out_channels, num_classes=1000, repeat_layers=(4, 8, 4)):super(ShuffleNetV1, self).__init__()self.groups = groupsself.conv1 = nn.Sequential(nn.Conv2d(3, 24, kernel_size=3, stride=2, padding=1, bias=False),nn.BatchNorm2d(24),nn.ReLU(inplace=True),)self.max_pool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.stage2 = self._make_layers(24, stages_out_channels[0], repeat_layers[0], groups)self.stage3 = self._make_layers(stages_out_channels[0], stages_out_channels[1], repeat_layers[1], groups)self.stage4 = self._make_layers(stages_out_channels[1], stages_out_channels[2], repeat_layers[2], groups)self.globalpool = nn.AvgPool2d(kernel_size=7, stride=1)self.fc = nn.Linear(stages_out_channels[2], num_classes)def _make_layers(self, in_channels, out_channels, repeat_number, groups):layers = []# 不同的 stage 阶段在第一步都是 stride = 2layers.append(shufflenet_units(in_channels, out_channels - in_channels, 2, groups))in_channels = out_channelsfor i in range(repeat_number - 1):layers.append(shufflenet_units(in_channels, out_channels, 1, groups))return nn.Sequential(*layers)def forward(self, x):x = self.conv1(x)x = self.max_pool(x)x = self.stage2(x)x = self.stage3(x)x = self.stage4(x)x = self.globalpool(x)x = torch.flatten(x, 1)out = self.fc(x)return out################################### 以下为 ShuffleNetV2 ###############################################class Improved_shufflenet_units(nn.Module):def __init__(self, inp, oup, stride):super().__init__()if not (1 <= stride <= 3):raise ValueError("illegal stride value")self.stride = stridebranch_features = oup // 2if (self.stride == 1) and (inp != branch_features << 1):raise ValueError(f"Invalid combination of stride {stride}, inp {inp} and oup {oup} values. If stride == 1 then inp should be equal to oup // 2 << 1.")self.branch1 = nn.Sequential(# DWConvnn.Conv2d(inp, inp, kernel_size=3, stride=self.stride, padding=1, bias=False, groups=inp),nn.BatchNorm2d(inp),nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True),)self.branch2 = nn.Sequential(nn.Conv2d(inp if (self.stride > 1) else branch_features,branch_features,kernel_size=1,stride=1,padding=0,bias=False,),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True),# DWConvnn.Conv2d(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1, bias=False, groups=branch_features),nn.BatchNorm2d(branch_features),nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),nn.BatchNorm2d(branch_features),nn.ReLU(inplace=True),)def forward(self, x):if self.stride == 1:x1, x2 = x.chunk(2, dim=1)out = torch.cat((x1, self.branch2(x2)), dim=1)else:out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)out = channel_shuffle(out, 2)return outclass ShuffleNetV2(nn.Module):def __init__(self,stages_out_channels,num_classes=1000,improved_units=Improved_shufflenet_units,repeat_layers=(4, 8, 4)):super().__init__()if len(repeat_layers) != 3:raise ValueError("expected stages_repeats as list of 3 positive ints")if len(stages_out_channels) != 5:raise ValueError("expected stages_out_channels as list of 5 positive ints")self._stage_out_channels = stages_out_channelsinput_channels = 3output_channels = self._stage_out_channels[0]self.conv1 = nn.Sequential(nn.Conv2d(input_channels, output_channels, 3, 2, 1, bias=False),nn.BatchNorm2d(output_channels),nn.ReLU(inplace=True),)input_channels = output_channelsself.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)# Static annotations for mypyself.stage2: nn.Sequentialself.stage3: nn.Sequentialself.stage4: nn.Sequentialstage_names = [f"stage{i}" for i in [2, 3, 4]]for name, repeats, output_channels in zip(stage_names, repeat_layers, self._stage_out_channels[1:]):seq = [improved_units(input_channels, output_channels, 2)]for i in range(repeats - 1):seq.append(improved_units(output_channels, output_channels, 1))setattr(self, name, nn.Sequential(*seq))input_channels = output_channelsoutput_channels = self._stage_out_channels[-1]self.conv5 = nn.Sequential(nn.Conv2d(input_channels, output_channels, 1, 1, 0, bias=False),nn.BatchNorm2d(output_channels),nn.ReLU(inplace=True),)self.fc = nn.Linear(output_channels, num_classes)def forward(self, x):x = self.conv1(x)x = self.maxpool(x)x = self.stage2(x)x = self.stage3(x)x = self.stage4(x)x = self.conv5(x)x = x.mean([2, 3]) # globalpoolx = self.fc(x)return x#----------------------------------------------------------------------------------------------------#
def shufflenet_v1_g1(num_classes):return ShuffleNetV1(groups=1,stages_out_channels=cfg_with_shufflenet['g1'],num_classes=num_classes)def shufflenet_v1_g2(num_classes):return ShuffleNetV1(groups=2,stages_out_channels=cfg_with_shufflenet['g2'],num_classes=num_classes)def shufflenet_v1_g3(num_classes):return ShuffleNetV1(groups=3,stages_out_channels=cfg_with_shufflenet['g3'],num_classes=num_classes)def shufflenet_v1_g4(num_classes):return ShuffleNetV1(groups=4,stages_out_channels=cfg_with_shufflenet['g4'],num_classes=num_classes)def shufflenet_v1_g8(num_classes):return ShuffleNetV1(groups=8,stages_out_channels=cfg_with_shufflenet['g8'],num_classes=num_classes)def shufflenet_v2_x0_5(num_classes):return ShuffleNetV2(cfg_with_shufflenet['x0_5'],num_classes=num_classes)def shufflenet_v2_x1_0(num_classes):return ShuffleNetV2(cfg_with_shufflenet['x1_0'],num_classes=num_classes)def shufflenet_v2_x1_5(num_classes):return ShuffleNetV2(cfg_with_shufflenet['x1_5'],num_classes=num_classes)def shufflenet_v2_x2_0(num_classes):return ShuffleNetV2(cfg_with_shufflenet['x2_0'],num_classes=num_classes)if __name__=="__main__":import torchsummarydevice = 'cuda' if torch.cuda.is_available() else 'cpu'input = torch.ones(2, 3, 224, 224).to(device)net = shufflenet_v2_x2_0(num_classes=4)net = net.to(device)out = net(input)print(out)print(out.shape)torchsummary.summary(net, input_size=(3, 224, 224))# shufflenet_v1_g1 Total params: 1,880,296# shufflenet_v1_g2 Total params: 1,834,852# shufflenet_v1_g3 Total params: 1,781,032# shufflenet_v1_g4 Total params: 1,734,136# shufflenet_v1_g8 Total params: 1,797,304# shufflenet_v2_x0_5 Total params: 345,892# shufflenet_v2_x1_0 Total params: 1,257,704# shufflenet_v2_x1_5 Total params: 2,482,724# shufflenet_v2_x2_0 Total params: 5,353,192参考文章
轻量级神经网络——shuffleNet_shuffnet-CSDN博客
【深度学习经典网络架构—9】:ShuffleNet系列(V1、V2)_shufflenet network-CSDN博客
【网络结构设计】3、ShuffleNet 系列 | 从 V1 到 V2_shufflenet网络结构-CSDN博客
轻量级神经网络——shuffleNet2_输入输出通道数相同的卷积-CSDN博客
轻量化网络结构——ShuffleNet_shufflenet网络结构-CSDN博客
论文阅读笔记:ShuffleNet-CSDN博客
这篇关于ShuffleNet模型详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





