本文主要是介绍深度学习论文随记(三)GoogLeNet-2014年,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

深度学习论文随记(三)GoogLeNet
Going Deeper with Convolutions
Author: Christian Szegedy, Wei Liu, Yangqing Jia, etl.
Year 2014
1、导引
2014年google参加ILSVRC竞赛,以此网络模型获得第一名的成绩。此模型名为GoogLeNet,而不是GoogleNet.是为了向CNN的开山鼻祖LeNet致敬。
该模型共有22层,利用multi-scaletraining。层数虽然变多,但是参数总量却只有7M,比AlexNet少多了,可是准确率却提高了:Top-5的错误率只有6.66%。
GoogLeNet模型成功证明了用更多的卷积,更深的网络层数可以得到更好的预测效果。
2、模型解读
Inception结构:
Why?
如果单纯的加深或者拓宽网络模型,会产生两个较为突出的问题:
①网络规模变大会产生更多参数,从而容易导致过拟合的发生。
②网络规模变大会使得计算量变大,消耗更多的计算资源。
解决这两个问题的方法是将全连接甚至是一般的卷积转化为稀疏矩阵。但是由于计算机计算时,对于非均匀稀疏数据这种东西的计算效率很差(这个其实很容易理解,你留意一下就会发现计算机在很多时候,都对矩形、矩阵有着难以置信的执着。),所以AlexNet模型启用了全连接层(全连接层说白了就是进行了矩阵乘法,)其目的是为了更好地优化并行运算。
所以,针对:”既要使得网络具有稀疏性,又想利用密集矩阵的高计算性能”这一个问题,人们提出了一种思路:将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,Google团队就顺着这一个思路,提出来了Inception结构。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
首先提出下图这样的基本结构:

本模型的分析:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3 . 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
4 . 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。但是5x5的卷积核会带来巨大的计算量,所以采用1x1的卷积核进行降维处理。
所以他们又做了如下的改进:

GoogLeNet:
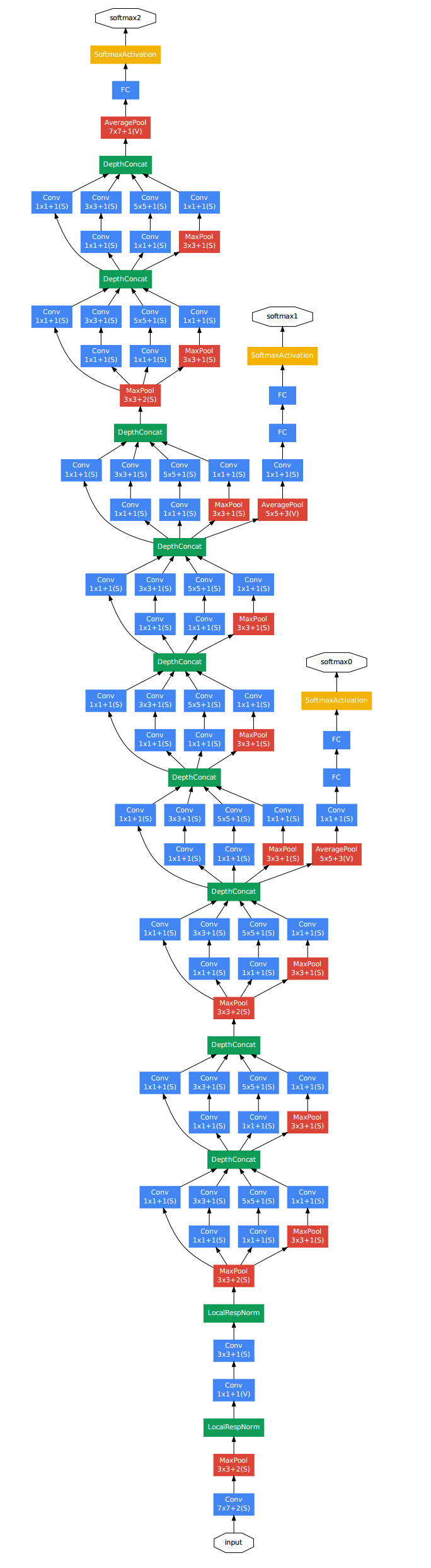

共有22层,原始输入的数据大小为224x224x3.
3、特点
·采用了模块化的结构,方便增添和修改
·网络最后用的是averagepooling层替代全连接层,将Top-1成功率提高了一点
·网络移除了全连接层,但是保留了Dropout层
·网络增加了两个辅助的softmax用于向前传导梯度,避免梯度消失。
这篇关于深度学习论文随记(三)GoogLeNet-2014年的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




