本文主要是介绍Pytorch打怪路(一)pytorch进行CIFAR-10分类(2)定义卷积神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pytorch打怪路(一)pytorch进行CIFAR-10分类(2)定义卷积神经网络

注:官方文档地址-- http://pytorch.org/docs/0.3.0/index.html
我的系列博文
Pytorch打怪路(一)pytorch进行CIFAR-10分类(1)CIFAR-10数据加载和处理
Pytorch打怪路(一)pytorch进行CIFAR-10分类(2)定义卷积神经网络(本文)
Pytorch打怪路(一)pytorch进行CIFAR-10分类(3)定义损失函数和优化器
Pytorch打怪路(一)pytorch进行CIFAR-10分类(4)训练
Pytorch打怪路(一)pytorch进行CIFAR-10分类(5)测试
1、简述
官网tutorial中显示图片的那部分我就直接省略了,因为跟训练网络无关,只是for fun
这一步骤虽然代码量很少,但是却包含很多难点和重点,执行这一步的代码需要包含以及神经网络工具箱torch.nn、以及神经网络函数torch.nn.functional,如果有兴趣的同学去看一下官网的Docs,会发现这俩模块所占的篇幅是相当相当的长啊,不知道一下午能不能看完….
所以我在这里也就简要地、根据此例所给的代码,来讲解一下即可,更多的内容还是参考官方文档更实在,虽然更费时……
所以我在这里也就简要地、根据此例所给的代码,来讲解一下即可,更多的内容还是参考官方文档更实在,虽然更费时……
注意:虽然官网给的程序有这么一句 from torch.autograd import Variable,但是此步中确实没有显式地用到variable,只能说网络里运行的数据确实要以variable的形式存在,在后面我们会讲解这个内容
所以这节先不讨论,当然代码写在那里是没问题的,反正后面会用
2.代码
# 首先是调用Variable、 torch.nn、torch.nn.functional
from torch.autograd import Variable # 这一步还没有显式用到variable,但是现在写在这里也没问题,后面会用到
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module): # 我们定义网络时一般是继承的torch.nn.Module创建新的子类def __init__(self): super(Net, self).__init__() # 第二、三行都是python类继承的基本操作,此写法应该是python2.7的继承格式,但python3里写这个好像也可以self.conv1 = nn.Conv2d(3, 6, 5) # 添加第一个卷积层,调用了nn里面的Conv2d()self.pool = nn.MaxPool2d(2, 2) # 最大池化层self.conv2 = nn.Conv2d(6, 16, 5) # 同样是卷积层self.fc1 = nn.Linear(16 * 5 * 5, 120) # 接着三个全连接层self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x): # 这里定义前向传播的方法,为什么没有定义反向传播的方法呢?这其实就涉及到torch.autograd模块了,# 但说实话这部分网络定义的部分还没有用到autograd的知识,所以后面遇到了再讲x = self.pool(F.relu(self.conv1(x))) # F是torch.nn.functional的别名,这里调用了relu函数 F.relu()x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5) # .view( )是一个tensor的方法,使得tensor改变size但是元素的总数是不变的。# 第一个参数-1是说这个参数由另一个参数确定, 比如矩阵在元素总数一定的情况下,确定列数就能确定行数。# 那么为什么这里只关心列数不关心行数呢,因为马上就要进入全连接层了,而全连接层说白了就是矩阵乘法,# 你会发现第一个全连接层的首参数是16*5*5,所以要保证能够相乘,在矩阵乘法之前就要把x调到正确的size# 更多的Tensor方法参考Tensor: http://pytorch.org/docs/0.3.0/tensors.htmlx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x# 和python中一样,类定义完之后实例化就很简单了,我们这里就实例化了一个net
net = Net()3.涉及知识点
①神经网络工具箱 torch.nn
这是一个转为深度学习设计的模块,我们来看一下 官方文档中它的目录
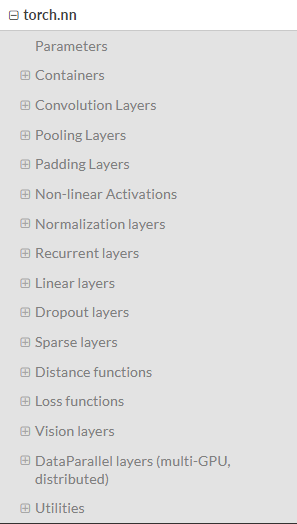
可以看到,nn模块中有很多很多的子模块,其中较为重要的,也是在咱们上面的程序中出现过的一些内容包括:
a. Container中的Module,也即nn.Module
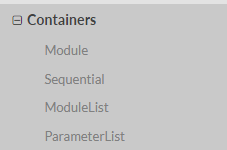
看一下nn.Module的详细介绍
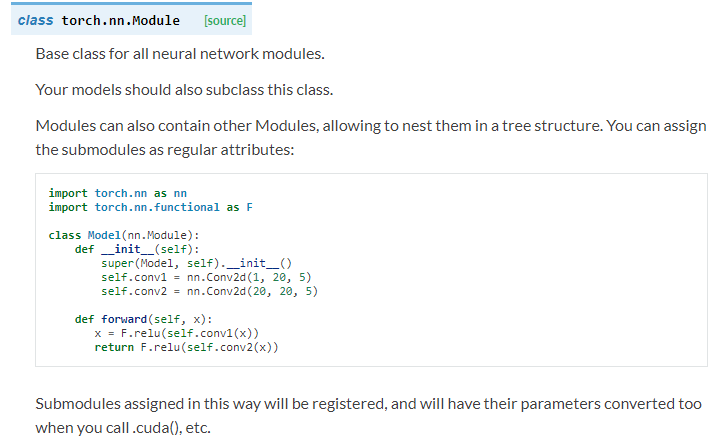
可知, nn.Module是所有神经网络的基类,我们自己定义任何神经网络, 都要继承nn.Module!class Net(nn.Module):
b. convolution layers
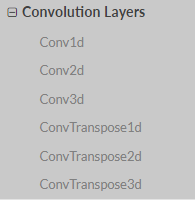
我们在上面的代码块中用到了Conv2d: self.conv1 = nn.Conv2d(3, 6, 5) self.conv2 = nn.Conv2d(6, 16, 5)

例如Conv2d(1,20,5)的意思就是说,输入是1通道的图像,输出是20通道,也就是20个卷积核,卷积核是5*5,其余参数都是用的默认值
c. pooling layers
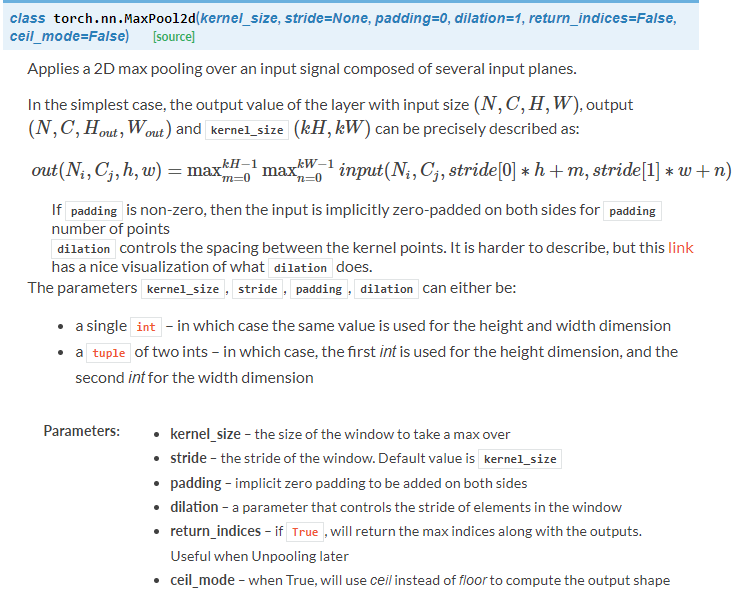
可以看到有很多的池化方式,我们上面的代码采用的是Maxpool2d: self.pool = nn.MaxPool2d(2, 2)
d. Linear layer
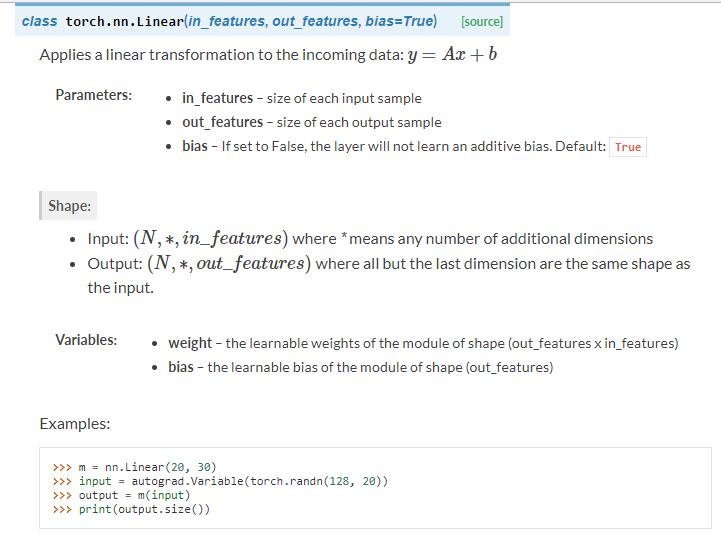
我们代码中用的是线性层Linear: self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10)
e. Non-linear Activations
要注意,其实这个例子中的非线性激活函数用的 并不是 torch.nn模块中的这个部分,但是 torch.nn模块中 有这个部分,所以我还是提一下。
此例中的激活函数用的其实是 torch.nn.functional 模块中的函数。它们是有区别的,区别下文继续讲。现在先浏览一下这个部分的内容即可:
可以看出,torch.nn 模块中其实也有很多激活函数的,只不过我们此例用的不是这里的激活函数!!!
②torch.nn.functional
这个模块包含的内容如图所示
t orch.nn中大多数layer在torch.nn.funtional中都有一个与之对应的函数。二者的区别在于:
torch. nn.Module中实现layer的都是一个特殊的类,可以去查阅,他们都是以class xxxx来定义的, 会自动提取可学习的参数
而 nn.functional中的函数,更像是纯函数,由def function( )定义,只是进行简单的 数学运算而已。
说到这里你可能就明白二者的区别了,functional中的函数是一个确定的不变的运算公式,输入数据产生输出就ok,
而深度学习中会有很多权重是在不断更新的,不可能每进行一次forward就用新的权重重新来定义一遍函数来进行计算,所以说就会采用类的方式,以确保能在参数发生变化时仍能使用我们之前定好的运算步骤。
所以从这个分析就可以看出什么时候改用nn.Module中的layer了:
如果模型有可学习的参数,最好使用nn.Module对应的相关layer,否则二者都可以使用,没有什么区别。
比如此例中的Relu其实没有可学习的参数,只是进行一个运算而已,所以使用的就是functional中的relu函数,
而卷积层和全连接层都有可学习的参数,所以用的是nn.Module中的类。
不具备可学习参数的层,将它们用函数代替,这样可以不用放在构造函数中进行初始化。
定义网络模型,主要会用到的就是torch.nn 和torch.nn.funtional这两个模块,这两个模块值得去细细品味一番,希望大家可以去读一下官方文档
这篇关于Pytorch打怪路(一)pytorch进行CIFAR-10分类(2)定义卷积神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






