本文主要是介绍【机器学习300问】44、P-R曲线是如何权衡精确率和召回率的?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于精确率和召回率的基础概念我已经写了两篇文章,如果友友还不知道这两个评估指标是什么,可以先移步去看看这两篇文章:
【机器学习300问】25、常见的模型评估指标有哪些?![]() http://t.csdnimg.cn/JtuUO
http://t.csdnimg.cn/JtuUO
总结一下这两个概念,这里直接最凝练的说出其本质:精确率(误测,测正类有多准,查准率);召回率(漏测,测正类有多全,查全率)
【机器学习300问】31、不平衡数据集如何进行机器学习?![]() http://t.csdnimg.cn/L8idA
http://t.csdnimg.cn/L8idA
想象一下,你是一位宝石鉴定师,你的工作是在一堆石头中找到所有的宝石。在这个任务中,精确率(Precision)相当于你找到的宝石中真正是宝石的比例,而召回率(Recall)则是你能够找到的宝石总数占所有宝石的比例。
现在存在这么一种情况,你大多数时候都能找到真正的宝石(红宝石、绿宝石),但你找到的这些宝石并不是你最喜欢的宝石(蓝宝石)。这是为什么呢?
还有一种情况是,你找到了许多的宝石,这些被你选出的石头里五花八门涵盖了许多宝石(红宝石、绿宝石、蓝宝石都有),但同时相当一部分并不是宝石。
一、精确率和召回率的权衡
(1)问题出在哪儿呢?
- 高准确率低召回率:如果你非常小心,只有当你百分百确定时,你才会确定一块石头是宝石,那么你找到的“宝石”几乎都是真宝石——这就是很高的精确率,但是你可能会错过一些实际上是宝石的石头,因为你太谨慎了——这会导致较低的召回率。
- 低准确率高召回率:另一方面,如果你决定宁可错杀三千,绝不放过一个,你可能会将更多的普通石头也当做宝石,这样你几乎能找到所有的宝石——即很高的召回率,但这其中也混入了很多并非宝石的杂石——这就导致了低精确率。
(2)怎么去解决?
要解决高准确率低召回率或低准确率高召回率的问题,首先应明确实际应用中对精确率和召回率的需求权重,然后通过调整模型决策阈值、优化模型本身,并结合F1分数、ROC曲线和P-R曲线的分析来指导模型调优过程。
【机器学习300问】32、F1分数是什么?![]() http://t.csdnimg.cn/khqRi
http://t.csdnimg.cn/khqRi
二、P-R曲线是什么?
本文主要介绍P-R曲线这种方法,来看看它是如何解决精确率和召回率的权衡问题的。P-R曲线可以直观反映精确率随召回率变化的情况,尤其是在数据不平衡的情况下更具指导意义。通过分析P-R曲线,可以找到一个既能保持相对较高的精确率又能提高召回率的理想工作点。
(1)P-R曲线的定义
P-R曲线(Precision-Recall Curve)是针对二分类问题中模型性能评估的一种可视化工具,主要用于展现模型在不同阈值条件下的精确率和召回率之间的关系。
- 横轴(X轴):召回率(Recall)
- 纵轴(Y轴):精确率(Precision)
- 图中的点:不同阈值下的
(2)P-R曲线的图像
在构建P-R曲线的过程中,通常会调整模型的决策阈值,从而获得一系列的精确率和召回率对,这些对在坐标系中连接起来形成一条曲线。
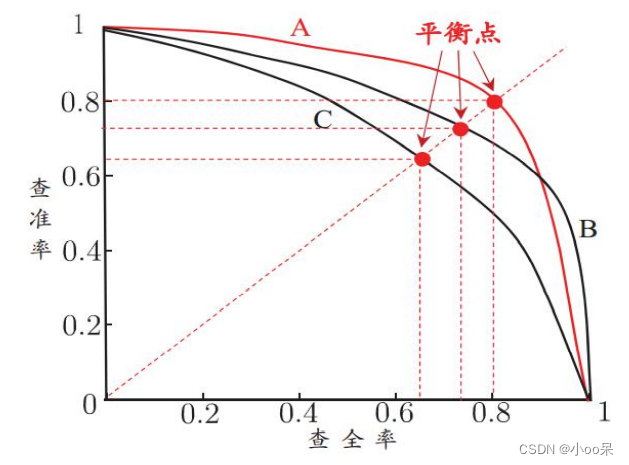
通过对这条曲线的分析,可以了解模型在不同阈值下如何权衡精确识别正类的能力(精确率)与找出尽可能多的正类实例的能力(召回率),即找到图中的平衡点,平衡点对应的阈值就是模型最合适的阈值。图中A、B、C是三个不同的模型,他们有着不同的平衡点。
① 寻找平衡点的三个方法
- 观察曲线形状来找平衡点,P-R曲线越靠近右上角,表示模型在保持高召回率的同时也能保持高精确率,这是最优的表现。
- 通过最高的F1分数来找平衡点,F1分数是精确率和召回率的调和平均值,它提供了一个单值度量来评估模型在这两个指标上的均衡表现。在P-R曲线上对应的F1分数最高的点,通常被认为是精确率和召回率的较好平衡点。
- 根据实际需求选择,如果业务对召回率有极高要求(比如疾病筛查,宁可错诊也不愿漏诊),则会选择召回率较高的点;如果对精确率有极高要求(比如防止误报警系统),则会选择精确率较高的点。
这篇关于【机器学习300问】44、P-R曲线是如何权衡精确率和召回率的?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









