本文主要是介绍GPU算力池管理工具Determined AI部署与使用教程(2024.03),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概念
1.1 什么是Determined?
Determined AI 是一个全功能的深度学习平台,兼容 PyTorch 和 TensorFlow。它主要负责以下几个方面:
- 分布式训练:Determined AI 可以将训练工作负载分布在多个 GPU(可能在多台计算机上)上,而无需更改代码。无论是在一台计算机上利用2个 GPU 还是在多台计算机上利用16个 GPU,都只需更改配置即可。
- 超参数调优:Determined AI 提供了自动超参数搜索功能,可以帮助你找到最优的模型参数。
- 资源管理:Determined AI 可以有效地管理和调度计算资源,以降低云 GPU 的成本。
- 实验跟踪:Determined AI 可以跟踪和记录实验的过程,方便你分析结果和复现实验。
Determined AI 的主要组件之一是命令行接口(CLI),它提供了一种高效的方式来管理和控制系统的各个方面。例如,你可以使用 CLI 来创建、列出和管理实验,以及访问重要的实验指标和日志。CLI 还可以帮助你管理作业队列,监控正在进行的任务的进度,甚至根据需要优先处理或取消作业。
此外,Determined AI 还支持自由形式的任务,如命令和 Shell。命令和 Shell 使开发人员可以在不必编写符合试验 API 的代码的情况下,使用 Determined 集群和其 GPU。
1.2 Determined集群中的Master和Agent分别表示什么意思?
在 Determined 集群中,Master 和 Agent 有特定的角色和功能。
- Master:Master 是 Determined 集群的核心,它负责管理和调度所有的任务。Master 接收来自用户(通过网页、CLI 等方式)的请求,并将这些请求发送到 Agent 进行处理。Master 的行为可以通过设置配置变量来控制,这可以通过使用配置文件、环境变量或命令行选项来完成。
- Agent:Agent 是执行任务的节点,它们在 Master 的调度下运行任务。每个 Agent 都有一个唯一的 ID(默认为当前机器的主机名),并且在一个集群中必须是唯一的。Agent 节点通常是配备 GPU 的服务器,用于运行计算密集型的深度学习任务。
总的来说,Master 负责管理和调度任务,而 Agent 负责执行这些任务。
2. 部署与配置
2.1 在本地部署
在部署 Master 与 Agent 节点的服务器上需要先安装好 Docker,安装教程(Ubuntu 系统下):Install Docker Engine on Ubuntu。
安装 nvidia-container-toolkit(Master 和存储节点不需要 GPU,也无需安装 Nvidia 相关的内容),否则部署使用 GPU 的集群会出现报错 Internal Server Error ("could not select device driver "nvidia" with capabilities: [[gpu utility]]"):
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.listsudo apt-get updatesudo apt-get install -y --no-install-recommends nvidia-container-toolkitsudo service docker restart
安装 Determined 库并在本地启动集群,对于本地开发或小型集群(例如 GPU 工作站),您可能希望同时安装 Master 和 Agent 位于同一节点上,因此可以使用 cluster-up:
pip install determined # 可能会有某些包之间存在版本冲突需要解决# If your machine has GPUs:
det deploy local cluster-up# If your machine does not have GPUs:
det deploy local cluster-up --no-gpu
如果 det 命令识别不到可能是没有配置环境变量:
sudo vim /etc/environment
在 PATH='xxx' 后面添加 ':/home/<用户名>/.local/bin'
即: 'xxx:/home/<用户名>/.local/bin'source /etc/environment # 应用更新
要停止 Determined 集群,请在当前运行 Determined 集群的计算机上,运行:
det deploy local cluster-down
在许多情况下,Determined 集群将由多个节点组成。在这种情况下,您将需要分别启动 Master 和 Agents。启动和停止独立 Master:
det deploy local master-up # 启动
det deploy local master-down # 停止
若要在计算机上部署独立的 Agent,请运行以下命令之一,<master_hostname> 为 Master 的主机名:
# If the machine has GPUs:
det deploy local agent-up <master_hostname># If the machine doesn't have GPUs:
det deploy local agent-up --no-gpu <master_hostname># Stop Agent
det deploy local agent-down
与用户相关的指令:
det user list # 列出所有的用户,包括他们的用户名、管理员状态、活动状态等
det user get <username> # 显示某用户的详细信息,包括他们是否已经登录
访问 http://localhost:8080/,用户名为 determined,密码留空,即可登录。
2.2 配置参考
查看当前 Master 配置信息:
det master config
我们可以自定义 Master 的配置,在需要部署 Master 的服务器上创建 Master 配置文件 master-config.yaml,具体配置教程见:Master Configuration Reference,参考内容如下:
__internal:audit_logging_enabled: falseexternal_sessions:jwt_key: ''login_uri: ''logout_uri: ''proxied_servers: null
cache:cache_dir: /var/cache/determined
checkpoint_storage:host_path: /home/ubuntu/.local/share/determinedpropagation: nullsave_experiment_best: 0save_trial_best: 1save_trial_latest: 1storage_path: nulltype: shared_fs
cluster_name: ''
config_file: ''
db:host: determined-dbmigrations: file:///usr/share/determined/master/static/migrationsname: determinedpassword: '********'port: '5432'ssl_mode: disablessl_root_cert: ''user: postgres
enable_cors: false
feature_switches: []
integrations:pachyderm:address: ''
launch_error: true
log:color: truelevel: info
logging:type: default
notebook_timeout: null
observability:enable_prometheus: false
port: 8080
reserved_ports: null
resource_manager:client_ca: ''default_aux_resource_pool: default # 默认辅助资源池default_compute_resource_pool: defaut # 默认计算资源池no_default_resource_pools: falserequire_authentication: falsescheduler:allow_heterogeneous_fits: falsefitting_policy: besttype: fair_sharetype: agent
resource_pools: # 设置资源池
- agent_reattach_enabled: falseagent_reconnect_wait: 25sdescription: ''kubernetes_namespace: ''max_aux_containers_per_agent: 100pool_name: defaultprovider: nulltask_container_defaults: null
- agent_reattach_enabled: falseagent_reconnect_wait: 25sdescription: ''kubernetes_namespace: ''max_aux_containers_per_agent: 100pool_name: RTX3090provider: nulltask_container_defaults: null
root: /usr/share/determined/master
security:authz:_strict_ntsc_enabled: falsefallback: basicrbac_ui_enabled: nullstrict_job_queue_control: falsetype: basicworkspace_creator_assign_role:enabled: truerole_id: 2default_task:gid: 0group: rootid: 0uid: 0user: rootuser_id: 0ssh:rsa_key_size: 1024tls:cert: ''key: ''
task_container_defaults:add_capabilities: nullbind_mounts: nullcpu_pod_spec: nulldevices: nulldrop_capabilities: nullgpu_pod_spec: nullkubernetes: nulllog_policies: nullnetwork_mode: bridgepbs: {}shm_size_bytes: 4294967296slurm: {}work_dir: null
telemetry:cluster_id: ''enabled: trueotel_enabled: falseotel_endpoint: localhost:4317segment_master_key: '********'segment_webui_key: '********'
tensorboard_timeout: 300
webhooks:base_url: ''signing_key: fc9942f4d575
然后即可使用配置文件启动集群:
det deploy local cluster-up --master-config-path ./master-config.yaml
在需要部署 Agent 的服务器上创建 Agent 配置文件 agent-config.yaml,具体配置教程见:Agent Configuration Reference,参考内容如下:
# 必填,用于确定 Master 节点的主机名或 IP 地址
master_host: <ip_of_your_master_node>
# Master 节点的端口。
master_port: 8080# 此 Agent 的 ID,默认为当前计算机的主机名,ID 在集群中必须是唯一的
agent_id: RTX3090_0
# 指定分配到哪个资源池
resource_pool: RTX3090# Agent 容器的 HTTP/HTTPS 代理地址
http_proxy: <ip_of_proxy>
https_proxy: <ip_of_proxy>
这里主要配置3个内容:
- Master 节点主机名和端口号,用于识别 Master 节点。
agent_id和resource_pool,分别对应本机 ID 和资源池,根据显卡型号命名即可,注意资源池需要已在 Master 配置文件中定义过。- 科学上网代理。
完成后,所有 Agent 节点使用如下命令启动(最后的 0.29.0 为 Determined AI 的版本号,根据自己安装的版本修改即可):
docker run --gpus all -v /var/run/docker.sock:/var/run/docker.sock -v "$PWD"/agent-config.yaml:/etc/determined/agent.yaml determinedai/determined-agent:0.29.0
2.3 命令行、Notebook、Shell的使用方法
Determined 主要有两种使用方式:Web 和 CLI。其中 Web 可以直接通过 <Master节点IP>:8080 进行访问:
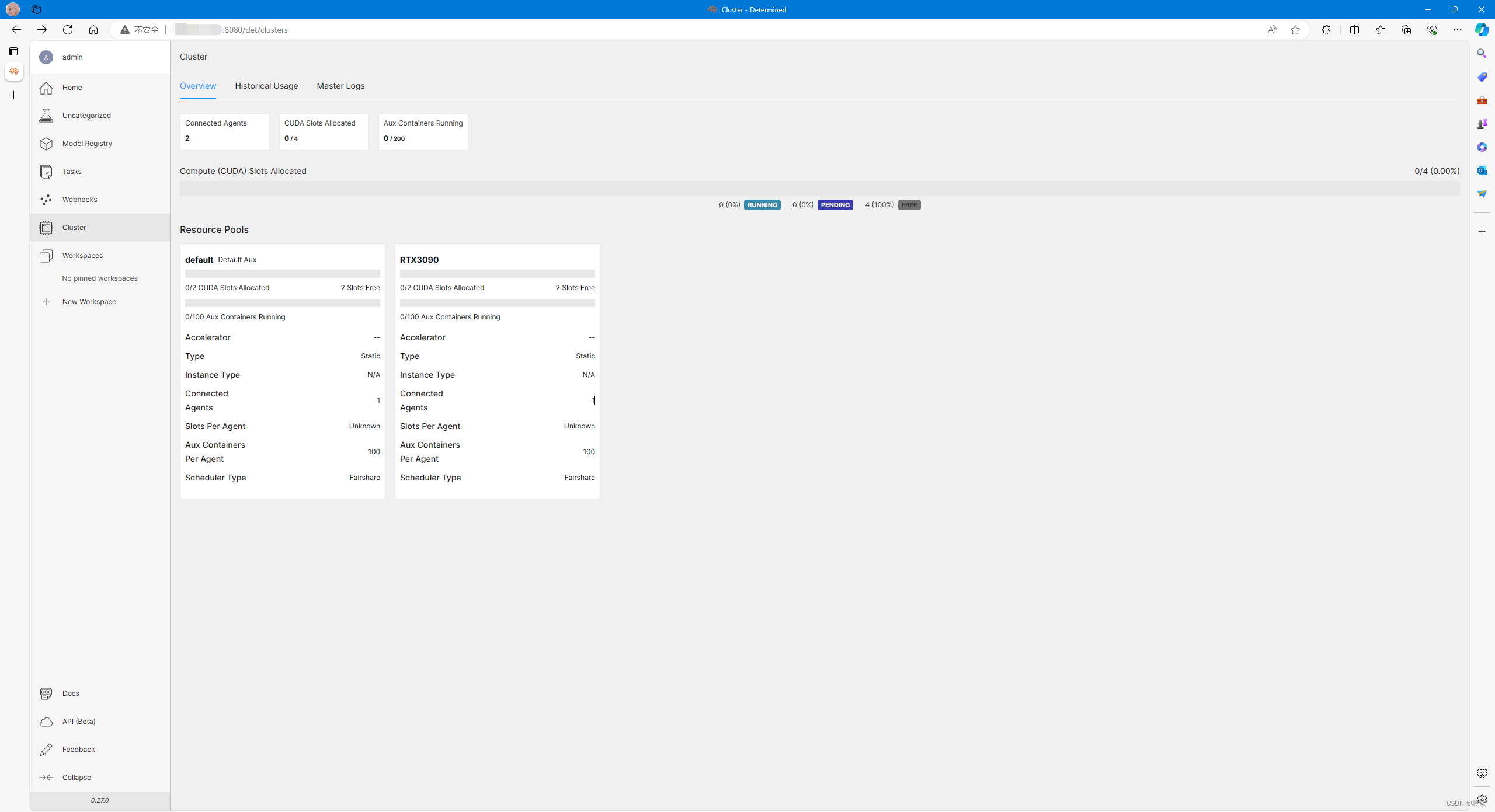
但是不推荐使用 Web 方式,因为网页端创建任务无法自定义存储路径和加载的 Docker 镜像,灵活度十分受限。因此接下来详细介绍 CLI 的用法。
首先在终端机安装好 Determined,然后在环境变量中配置 Master 节点 IP:
vim ~/.bashrc# 添加以下内容,保存并退出
export DET_MASTER=<Master节点的IP>source ~/.bashrc
接下来可以使用 Determined CLI 创建任务,首先在终端机需要登录,在 Admin 用户(用户名为 admin,密码留空)中可以管理其他用户,假设已经给终端机创建好账号即可登录:
det user login
然后写一个开启任务的 Yaml 配置文件,这里给出一个参考:
description: test_task
resources:resource_pool: RTX3090slots: 1
# 将物理机上host_path路径下的文件挂载到用户当前使用的容器的container_path路径下
bind_mounts:- host_path: /home/ubuntu/container_path: /run/determined/workdir/asanosaki/
environment: # Docker容器的环境配置,包括使用的镜像和环境变量image: determinedai/environments:cuda-11.8-pytorch-2.0-gpu-0.29.1environment_variables:- http_proxy=<ip_of_proxy>- https_proxy=<ip_of_proxy>
Determined 官方给出了很多个版本的 CUDA 和框架的组合,可以自行选择所需要的镜像,Determined AI Docker 镜像列表:Docker Hub DeterminedAI。
完成后,可以选择开启 Jupyter Notebook 或者终端,这取决于使用者的习惯:
# Notebook
det notebook start --config-file config.yaml# CMD
det cmd run --config-file config.yaml# Shell
det shell start --config-file config.yaml
对应的停止任务指令如下:
# Notebook
det notebook kill <ID># CMD
det cmd kill <ID># Shell
det shell kill <ID>
任务的 <ID> 可通过 det task list 查看所有任务信息获得,写前8位即可。
2.4 创建实验
先下载官方的项目示例代码:mnist_pytorch.tgz。
将其解压到当前目录:
tar zxvf mnist_pytorch.tgz -C ./
cd mnist_pytorch
可以看到该目录下有单卡运行实验以及多卡并行运行实验的实验配置文件 const.yaml 和 distributed.yaml,此处给出 distributed.yaml 配置参考内容如下:
name: mnist_pytorch_distributed
hyperparameters:learning_rate: 1.0n_filters1: 32n_filters2: 64dropout1: 0.25dropout2: 0.5
searcher:name: singlemetric: validation_lossmax_length:epochs: 1smaller_is_better: true
entrypoint: python3 -m determined.launch.torch_distributed python3 train.py
description: test_task
resources:resource_pool: RTX3090slots_per_trial: 2
bind_mounts:- host_path: /home/ubuntu/container_path: /run/determined/workdir/asanosaki/
environment:image: determinedai/environments:cuda-11.8-pytorch-2.0-gpu-0.29.1environment_variables:- http_proxy=<ip_of_proxy>- https_proxy=<ip_of_proxy>
接下来即可通过配置文件创建任务(最后一个 . 表示上传当前目录中的所有文件,作为模型的上下文目录。Determined 将模型上下文目录内容复制到试验容器工作目录):
det experiment create distributed.yaml .
2.5 通过VSCode SSH连接
首先确保 VSCode 已经安装 Remote - SSH 扩展,当用户开启了 Shell 后,可以在终端机上执行以下命令获取 Shell 的 SSH 登录命令:
det shell show_ssh_command <SHELL UUID>
复制 SSH 命令,在 VS Code 的 Remote Explorer 页面下即可添加连接。
这篇关于GPU算力池管理工具Determined AI部署与使用教程(2024.03)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



