本文主要是介绍每秒批量插入10000条数据到MySQL中,资源消耗(带宽、IOPS)有多少?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 🔊博主介绍
- 🥤本文内容
- 起因
- 代码
- 资源情况
- 改造
- 📢文章总结
- 📥博主目标
🔊博主介绍
🌟我是廖志伟,一名Java开发工程师、Java领域优质创作者、CSDN博客专家、51CTO专家博主、阿里云专家博主、清华大学出版社签约作者、产品软文专业写手、技术文章评审老师、问卷调查设计师、个人社区创始人、开源项目贡献者。🌎跑过十五公里、🚀徒步爬过衡山、🔥有过三个月减肥20斤的经历、是个喜欢躺平的狠人。
📕拥有多年一线研发和团队管理经验,研究过主流框架的底层源码(Spring、SpringBoot、Spring MVC、SpringCould、Mybatis、Dubbo、Zookeeper),消息中间件底层架构原理(RabbitMQ、RockerMQ、Kafka)、Redis缓存、MySQL关系型数据库、 ElasticSearch全文搜索、MongoDB非关系型数据库、Apache ShardingSphere分库分表读写分离、设计模式、领域驱动DDD、Kubernetes容器编排等。
📙有过从0到1的项目高并发项目开发与管理经验,对JVM调优、MySQL调优、Redis调优 、ElasticSearch调优、消息中间件调优、系统架构调优都有着比较全面的实战经验。
📘有过云端搭建服务器环境,自动化部署CI/CD,弹性伸缩扩容服务器(最高200台),了解过秒级部署(阿里云的ACK和华为云的云容器引擎CCE)流程,能独立开发和部署整个后端服务,有过分库分表的实战经验。
🎥经过多年在CSDN创作上千篇文章的经验积累,我已经拥有了不错的写作技巧,与清华大学出版社签下了四本书籍的合约,并将陆续在明年出版。这些书籍包括了基础篇、进阶篇、架构篇的📌《Java项目实战—深入理解大型互联网企业通用技术》📌,以及📚《解密程序员的思维密码–沟通、演讲、思考的实践》📚。具体出版计划会根据实际情况进行调整,希望各位读者朋友能够多多支持!
文章目录
- 🔊博主介绍
- 🥤本文内容
- 起因
- 代码
- 资源情况
- 改造
- 📢文章总结
- 📥博主目标
🌾阅读前,快速浏览目录和章节概览可帮助了解文章结构、内容和作者的重点。了解自己希望从中获得什么样的知识或经验是非常重要的。建议在阅读时做笔记、思考问题、自我提问,以加深理解和吸收知识。
💡在这个美好的时刻,本人不再啰嗦废话,现在毫不拖延地进入文章所要讨论的主题。接下来,我将为大家呈现正文内容。
🥤本文内容

起因
我在一台阿里云服务器部署了一主二从的MySQL集群,然后通过程序,控制每秒写入一万条数据入库,想看看消耗的资源情况
我本地跑的机器如下:
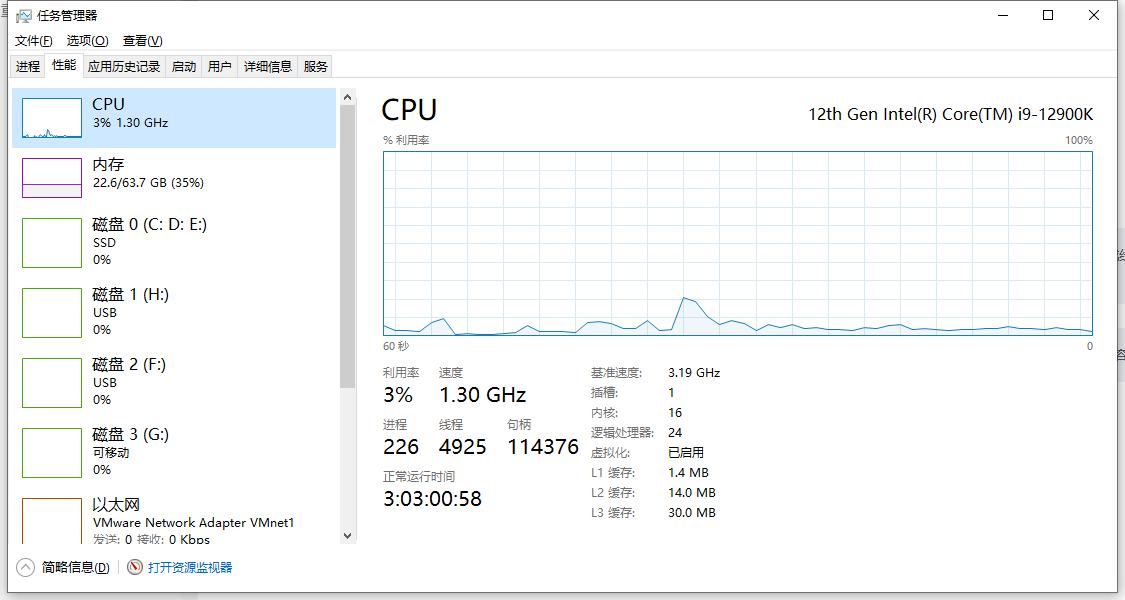 网络用的是手机开的热点,使用的是5G网络
网络用的是手机开的热点,使用的是5G网络
代码
private ScheduledExecutorService poolExecutor;private ScheduledFuture<?> scheduledFuture;public void startCreateUserTask() {// 初始化线程池poolExecutor = new ScheduledThreadPoolExecutor(Runtime.getRuntime().availableProcessors() * 2);// 提交定时任务,并保存返回的ScheduledFuture对象scheduledFuture = poolExecutor.scheduleAtFixedRate(() -> {List<TbUser> userList = new ArrayList<>(10000);for (int i = 0; i < 10000; i++) {TbUser tbUser = new TbUser();tbUser.setIsDelete(0);tbUser.setUserStatus(1);String uid = UUID.randomUUID().toString();tbUser.setNickename("liaozhiwei" + uid);tbUser.setUsername("liaozhiwei" + uid);tbUser.setPassword("liao" + uid);userList.add(tbUser);}Integer usersave = tbUserMapper.batchInsert(userList);log.info("批量保存用户数量:" + usersave);},0, //这是首次执行任务前的延迟时间。它表示从当前时间开始到首次执行任务所需的等待时间。配置为0,表示无需等待1, TimeUnit.SECONDS);//这是任务执行的周期时间。每次任务执行完毕后,都会等待这个时间段后再次执行任务。}public void stopCreateUserTask() {// 如果scheduledFuture不为null,则取消定时任务if (scheduledFuture != null && !scheduledFuture.isCancelled()) {scheduledFuture.cancel(true); // 传入true表示如果任务正在执行,则中断它}// 关闭线程池if (poolExecutor != null && !poolExecutor.isShutdown()) {poolExecutor.shutdown(); // 这不会立即停止所有任务,而是启动关闭过程}}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.yunxi.user.mapper.TbUserMapper" ><resultMap id="BaseResultMap" type="com.yunxi.user.model.po.TbUser" ><id column="id" property="id" jdbcType="INTEGER" /><result column="username" property="username" jdbcType="VARCHAR" /><result column="password" property="password" jdbcType="VARCHAR" /><result column="Is_Delete" property="isDelete" jdbcType="INTEGER" /><result column="user_status" property="userStatus" jdbcType="INTEGER" /><result column="nickename" property="nickename" jdbcType="VARCHAR" /></resultMap><!-- 用于select查询公用抽取的列 --><sql id="Base_Column_List">t.id,t.username,t.password,t.Is_Delete,t.user_status,t.nickename</sql><!-- batch insert --><insert id="batchInsert" parameterType="java.util.List">INSERT INTO tb_user (username,password,Is_Delete,user_status,nickename)VALUES<foreach collection="userList" item="item" index="index" separator="," >(#{item.username},#{item.password},#{item.isDelete},#{item.userStatus},#{item.nickename})</foreach></insert>
spring:datasource:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://8.138.100.27:33061/user?characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=GMT%2B8username: rootpassword: node1master1rootdruid:filters: stat,wall,slf4jinitial-size: 50min-idle: 100max-active: 20000max-wait: 60000time-between-eviction-runs-millis: 60000min-evictable-idle-time-millis: 300000test-while-idle: truetest-on-borrow: falsetest-on-return: falseweb-stat-filter:enabled: trueurl-pattern: /*session-stat-enable: truesession-stat-max-count: 1000stat-view-servlet:enabled: trueurl-pattern: /druid/*reset-enable: truelogin-username: adminlogin-password: admin123
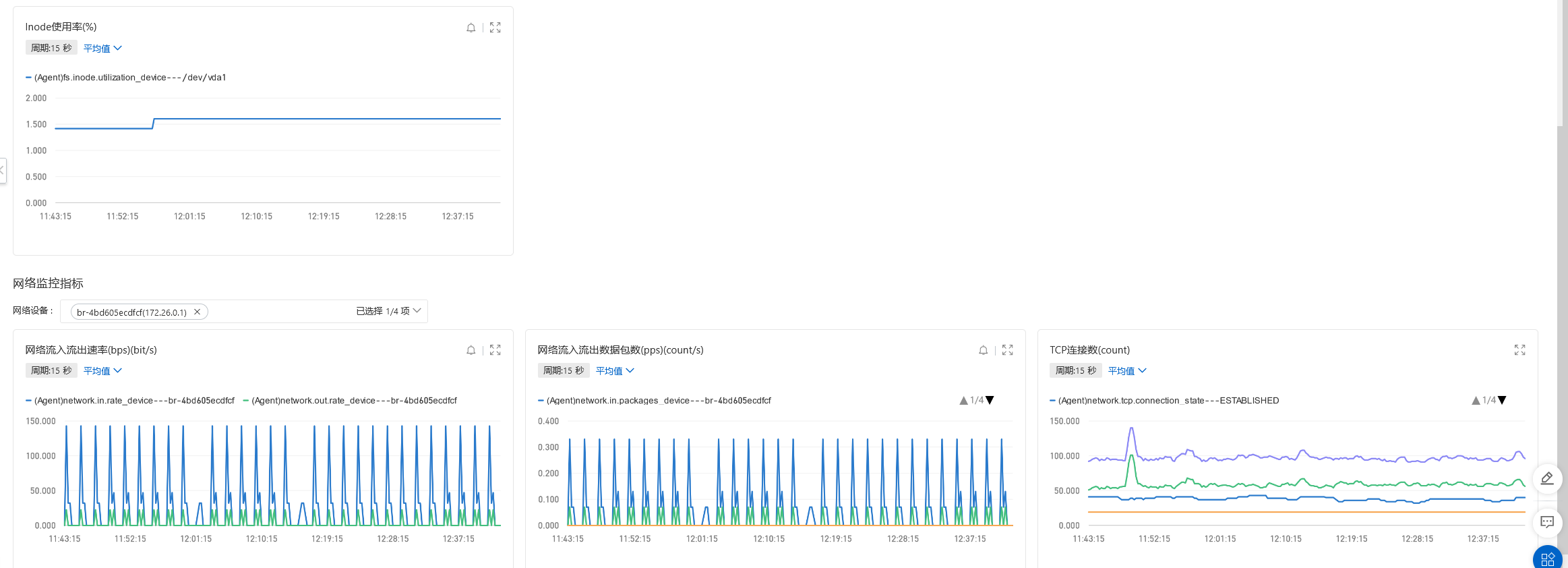
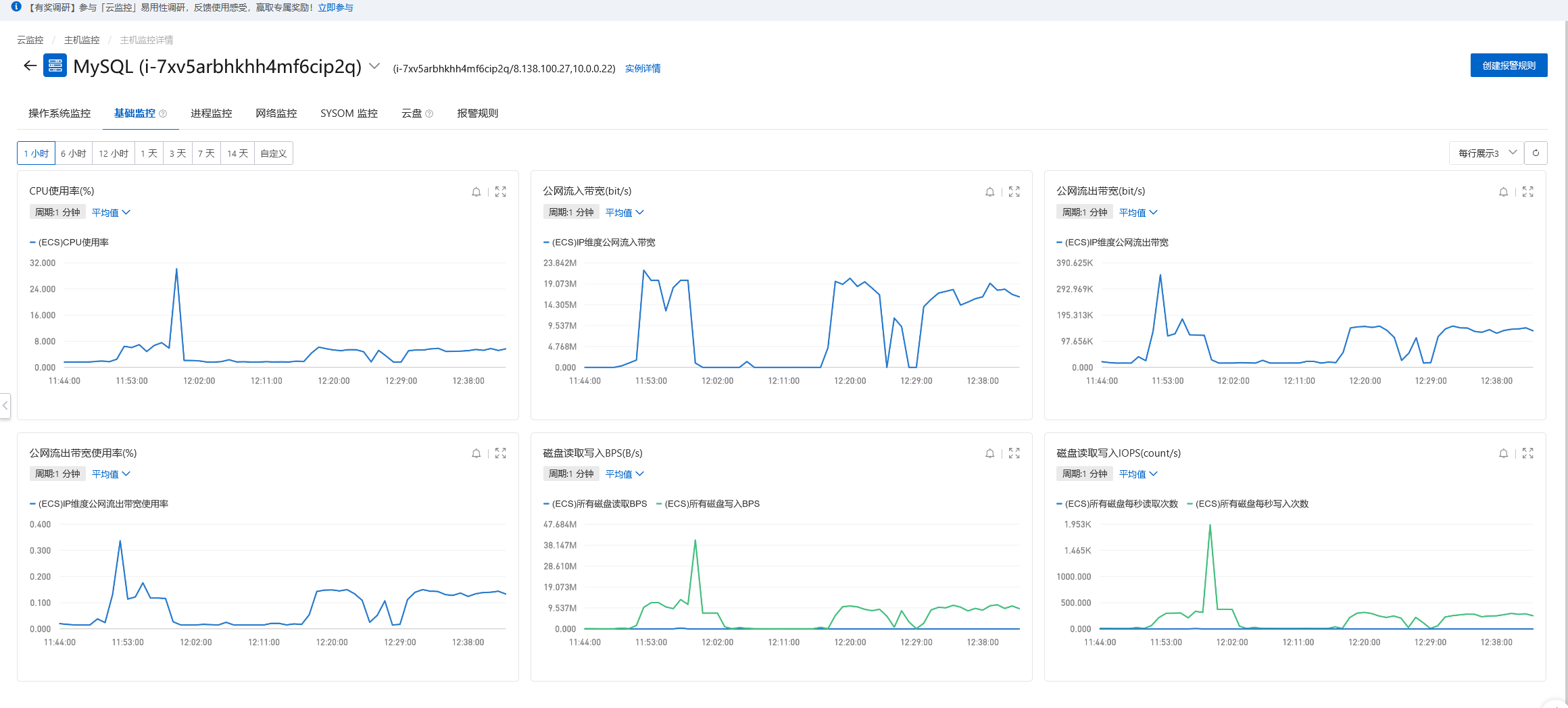
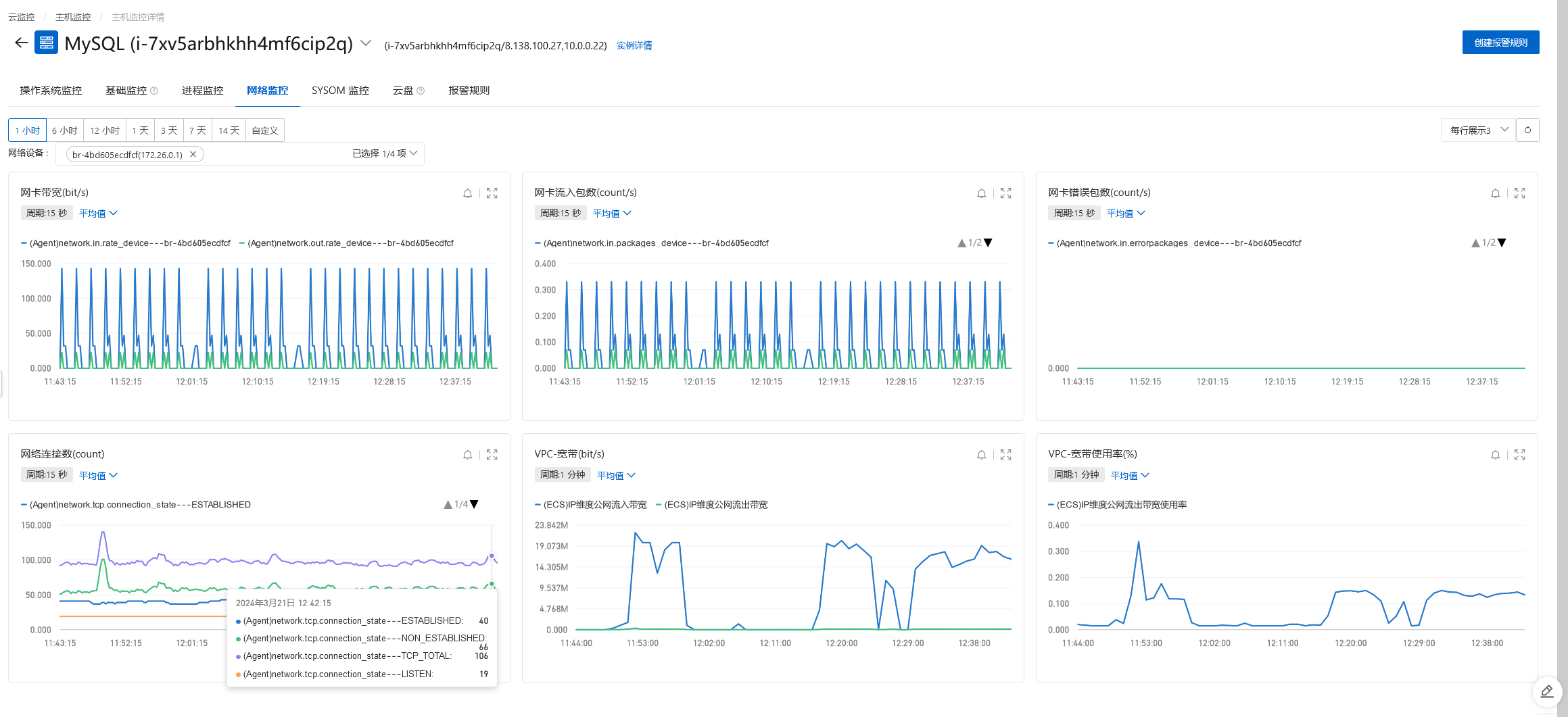
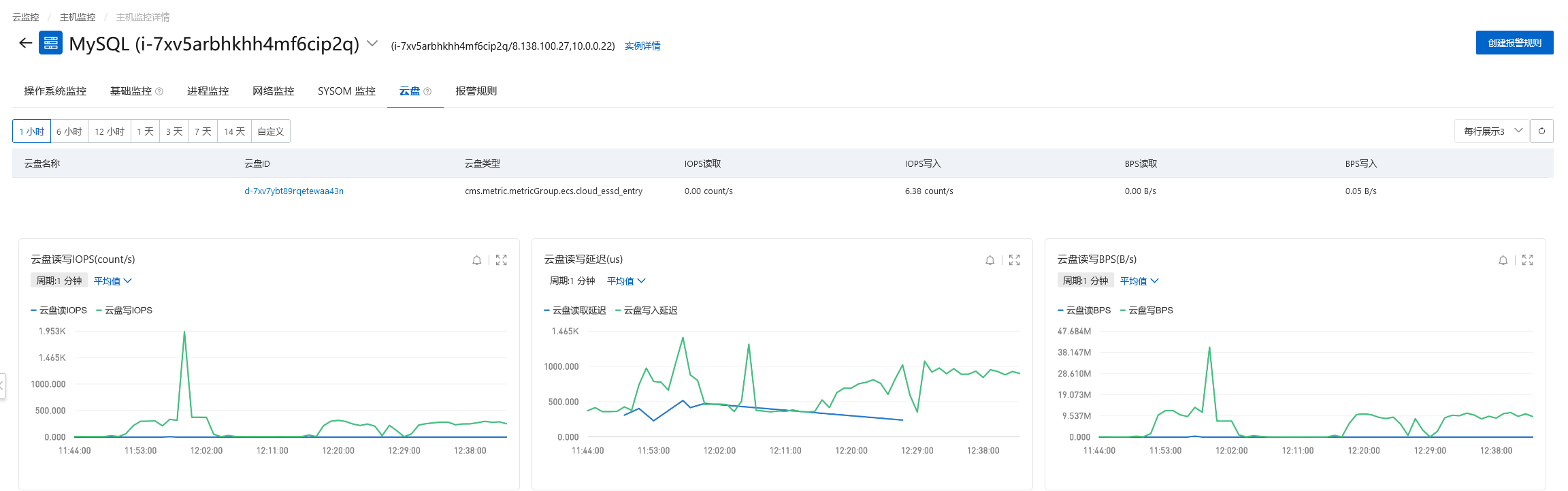
资源情况
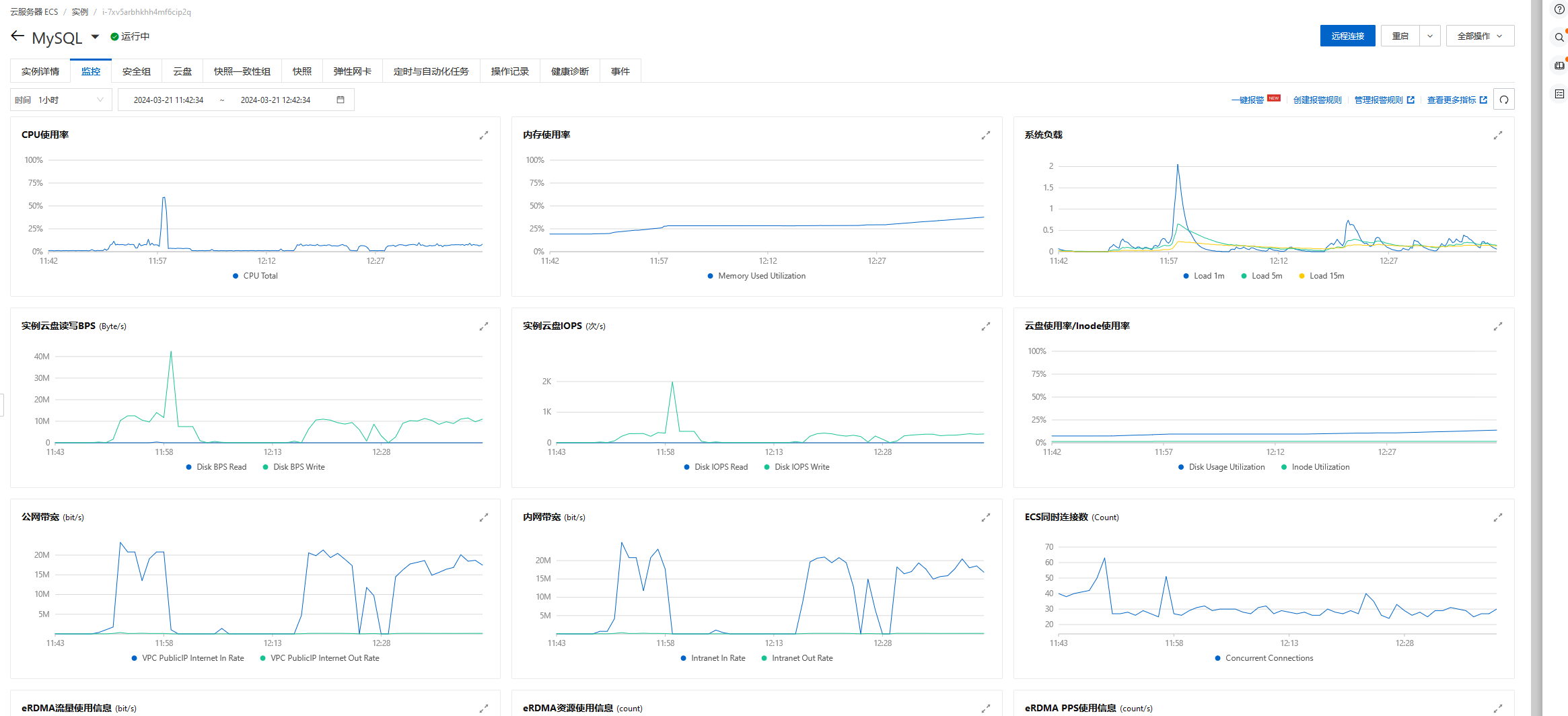
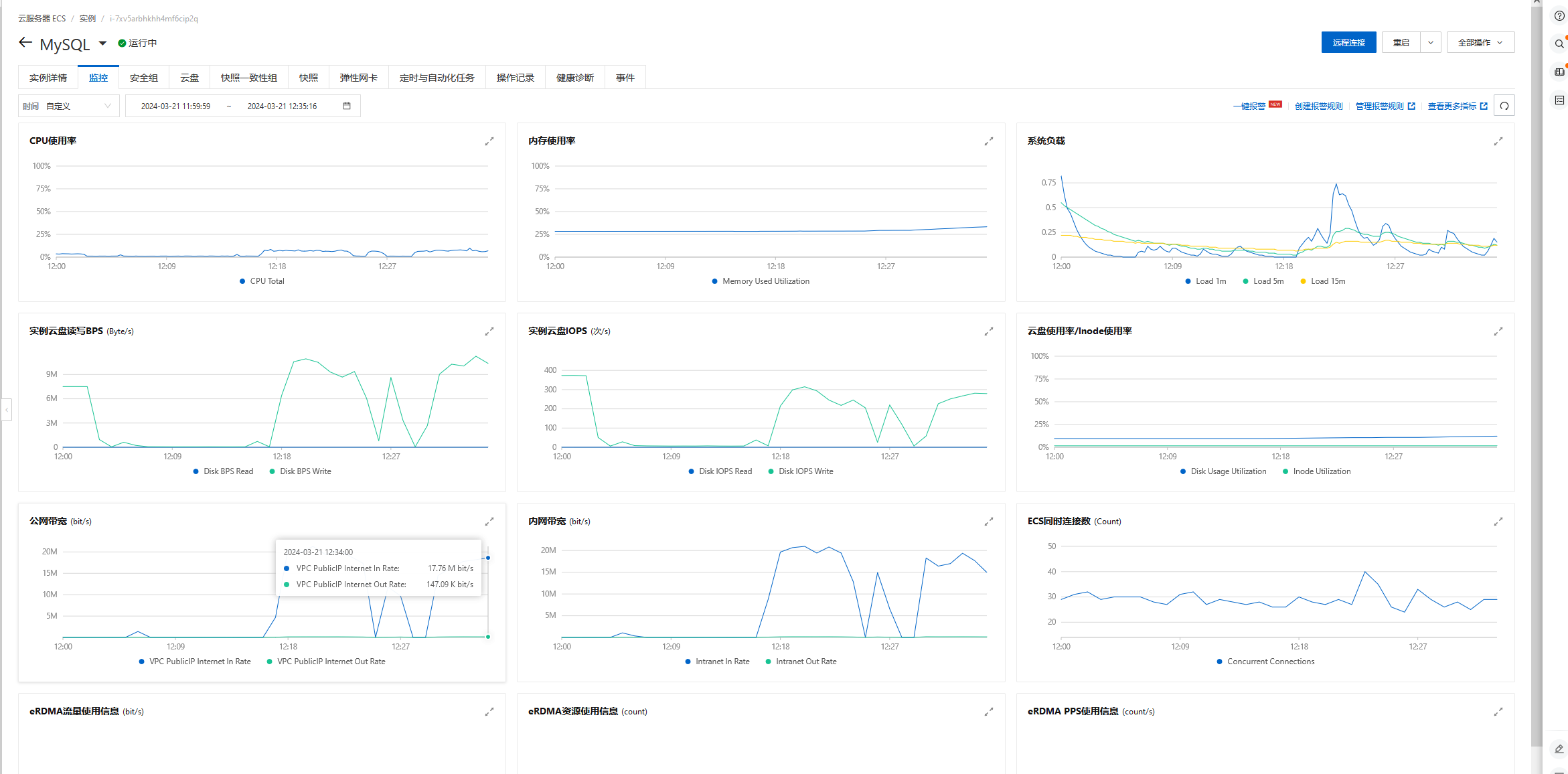
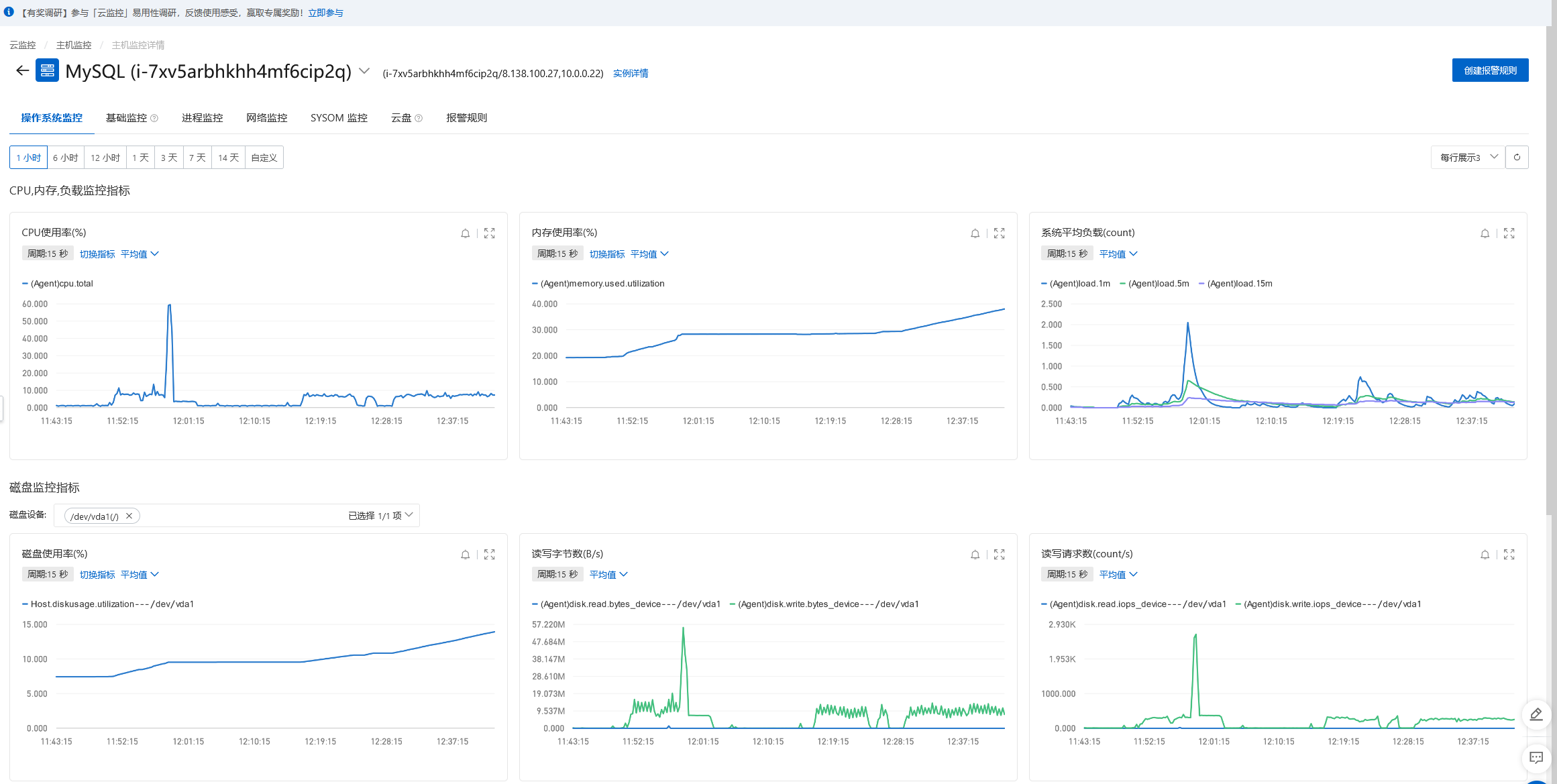
网络带宽低于每秒20M,实例云盘IOPS(次/s)低于400,连接数、CPU使用率、内存使用率、负载情况都比较低,我的服务器配置如下:

4核(vCPU),16 GiB经济型的服务器配置。只对主库进行插入。
在没有什么并发量的场景下,批量插入的数据十几分钟就可以到一千万,虽然不是很快,毕竟控制了插入的量和频率,插入的数据比较稳定,没有数据丢失的情况。


改造
private ScheduledExecutorService poolExecutor;private ScheduledFuture<?> scheduledFuture;public void startCreateUserTask(){Map<Integer, String> hashMap = new ConcurrentHashMap<>(10000);Map<Integer, String> map = new ConcurrentHashMap<>(1000);// CPU100%的使用率ThreadPoolExecutor executor = new ThreadPoolExecutor(Runtime.getRuntime().availableProcessors() * 2, // 核心线程数: IO类型的任务通常建议设置为CPU核心数的两倍左右Runtime.getRuntime().availableProcessors() * 4, // 最大线程数:IO类型的任务建议设置为核心线程数的2-4倍60, // 空闲线程存活时间TimeUnit.SECONDS, // 时间单位new LinkedBlockingQueue<>(10000));executor.execute(() -> {for (int i = 0; i < 10000; i++) {String uid = UUID.randomUUID().toString();hashMap.put(i,uid);}// 使用 Stream API 对 HashMap 中的值(密码)进行编码,并创建一个新的 Map 来存储编码后的密码Map<Integer, String> encodedPasswordsMap = hashMap.entrySet().parallelStream().map(entry -> new AbstractMap.SimpleEntry<>(entry.getKey(), passwordEncoder.encode(entry.getValue()))).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> newValue, ConcurrentHashMap::new));map.putAll(encodedPasswordsMap);});// 关闭线程池,不再接受新任务,但等待已提交的任务完成executor.shutdown();try {// 等待所有任务在60秒内完成,或者超时if (!executor.awaitTermination(60, TimeUnit.SECONDS)) {// 如果超时,可以选择取消所有未完成的任务System.out.println("Not all tasks finished within the timeout period. Cancelling remaining tasks.");executor.shutdownNow();// 可能需要处理任务被取消的情况} else {System.out.println("All tasks have completed.");}} catch (InterruptedException ie) {// 如果等待期间线程被中断,重新中断当前线程executor.shutdownNow();Thread.currentThread().interrupt();}if (map.size() == 10000) {// 初始化线程池poolExecutor = new ScheduledThreadPoolExecutor(Runtime.getRuntime().availableProcessors() * 2);// 提交定时任务,并保存返回的ScheduledFuture对象scheduledFuture = poolExecutor.scheduleAtFixedRate(() -> {List<TbUser> userList = new ArrayList<>(10000);for (int i = 0; i < 10000; i++) {TbUser tbUser = new TbUser();tbUser.setIsDelete(0);tbUser.setUserStatus(1);String uid = UUID.randomUUID().toString();tbUser.setNickename("liaozhiwei" + uid);tbUser.setUsername("liaozhiwei" + uid);tbUser.setPassword(map.get(i));userList.add(tbUser);}Integer usersave = tbUserMapper.batchInsert(userList);log.info("批量保存用户数量:" + usersave);},0, //这是首次执行任务前的延迟时间。它表示从当前时间开始到首次执行任务所需的等待时间。配置为0,表示无需等待1, TimeUnit.SECONDS);//这是任务执行的周期时间。每次任务执行完毕后,都会等待这个时间段后再次执行任务。}}public void stopCreateUserTask() {// 如果scheduledFuture不为null,则取消定时任务if (scheduledFuture != null && !scheduledFuture.isCancelled()) {scheduledFuture.cancel(true); // 传入true表示如果任务正在执行,则中断它}// 关闭线程池if (poolExecutor != null && !poolExecutor.isShutdown()) {poolExecutor.shutdown(); // 这不会立即停止所有任务,而是启动关闭过程}}
将代码调整后,一次插入100000,多了十倍,但是执行的时间也是多了十倍多,时间会多一丢丢,推断可能和我的网络有关,手机热点传输低于服务器带宽,传输有限,所以本机测试,一秒一万是最合适的。如果上服务器,执行效率应该会更高一点。
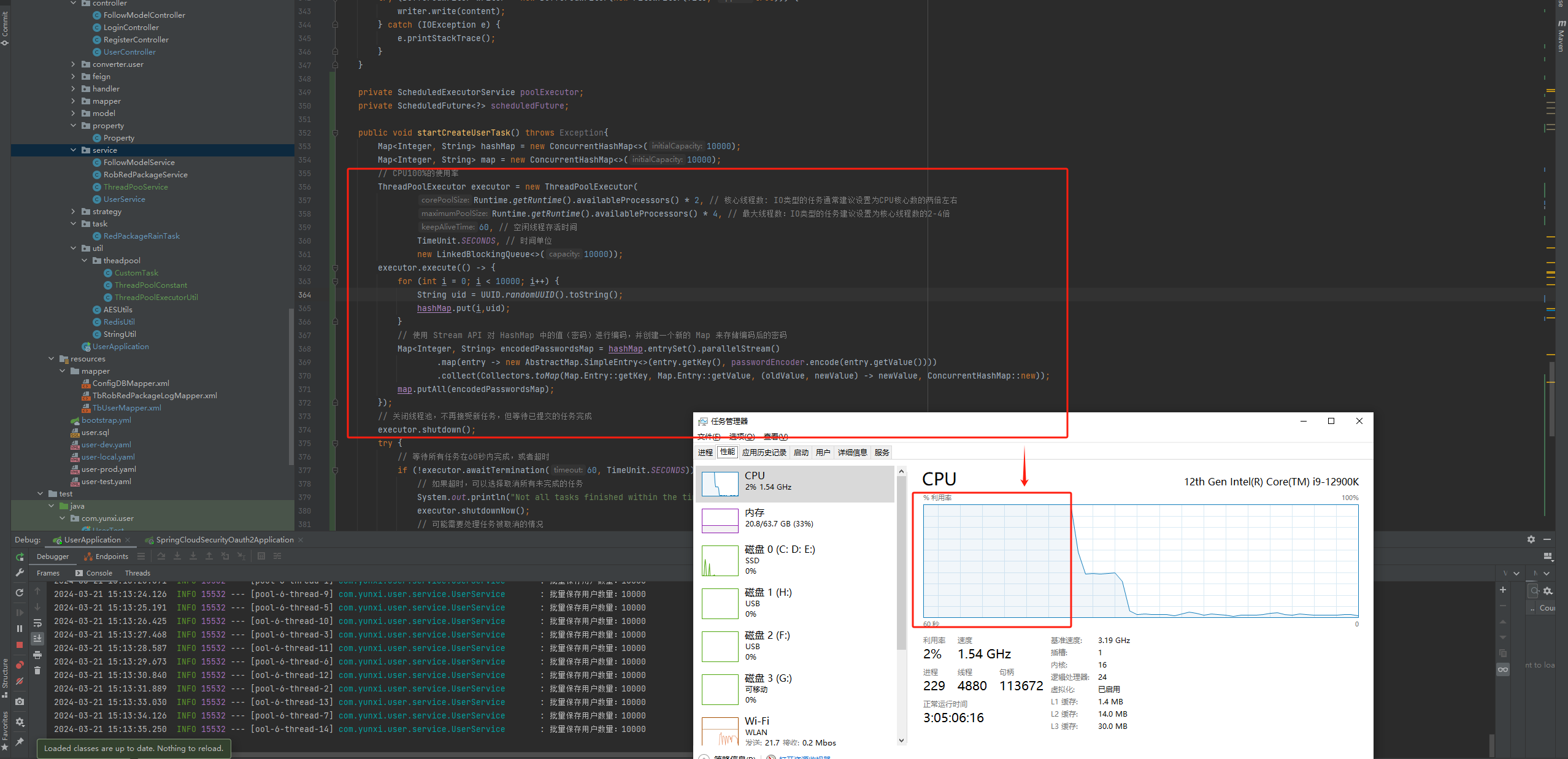 线程资源使用率100%,最大程度对密码进行加密计算,缩短计算时长。
线程资源使用率100%,最大程度对密码进行加密计算,缩短计算时长。
📢文章总结
对本篇文章进行总结:
🔔以上就是今天要讲的内容,阅读结束后,反思和总结所学内容,并尝试应用到现实中,有助于深化理解和应用知识。与朋友或同事分享所读内容,讨论细节并获得反馈,也有助于加深对知识的理解和吸收。

🔔如果您需要转载或者搬运这篇文章的话,非常欢迎您私信我哦~
🚀🎉希望各位读者大大多多支持用心写文章的博主,现在时代变了,🚀🎉 信息爆炸,酒香也怕巷子深🔥,博主真的需要大家的帮助才能在这片海洋中继续发光发热🎨,所以,🏃💨赶紧动动你的小手,点波关注❤️,点波赞👍,点波收藏⭐,甚至点波评论✍️,都是对博主最好的支持和鼓励!
- 💂 博客主页: 我是廖志伟
- 👉开源项目:java_wxid
- 🌥 哔哩哔哩:我是廖志伟
- 🎏个人社区:幕后大佬
- 🔖个人微信号:
SeniorRD - 🎉微信号二维码:

📥博主目标

- 🍋程序开发这条路不能停,停下来容易被淘汰掉,吃不了自律的苦,就要受平庸的罪,持续的能力才能带来持续的自信。我本是一个很普通的程序员,放在人堆里,除了与生俱来的盛世美颜,就剩180的大高个了,就是我这样的一个人,默默写博文也有好多年了。
- 📺有句老话说的好,牛逼之前都是傻逼式的坚持,希望自己可以通过大量的作品、时间的积累、个人魅力、运气、时机,可以打造属于自己的技术影响力。
- 💥内心起伏不定,我时而激动,时而沉思。我希望自己能成为一个综合性人才,具备技术、业务和管理方面的精湛技能。我想成为产品架构路线的总设计师,团队的指挥者,技术团队的中流砥柱,企业战略和资本规划的实战专家。
- 🎉这个目标的实现需要不懈的努力和持续的成长,但我必须努力追求。因为我知道,只有成为这样的人才,我才能在职业生涯中不断前进并为企业的发展带来真正的价值。在这个不断变化的时代,我们必须随时准备好迎接挑战,不断学习和探索新的领域,才能不断地向前推进。我坚信,只要我不断努力,我一定会达到自己的目标。
🔔有需要对自己进行综合性评估,进行职业方向规划,我可以让技术大牛帮你模拟面试、针对性的指导、传授面试技巧、简历优化、进行技术问题答疑等服务。
可访问:https://java_wxid.gitee.io/tojson/

这篇关于每秒批量插入10000条数据到MySQL中,资源消耗(带宽、IOPS)有多少?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








