本文主要是介绍Redis持久化机制与位图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、持久化机制
1.概述:
client redis[内存] -----> 内存数据---数据持久化-->磁盘
Redis官方提供了两种不同的持久化方法来将内存的数据存储到硬盘里面分别是:
-
快照(Snapshot)
-
AOF (Append Only File) 只追加日志文件
-
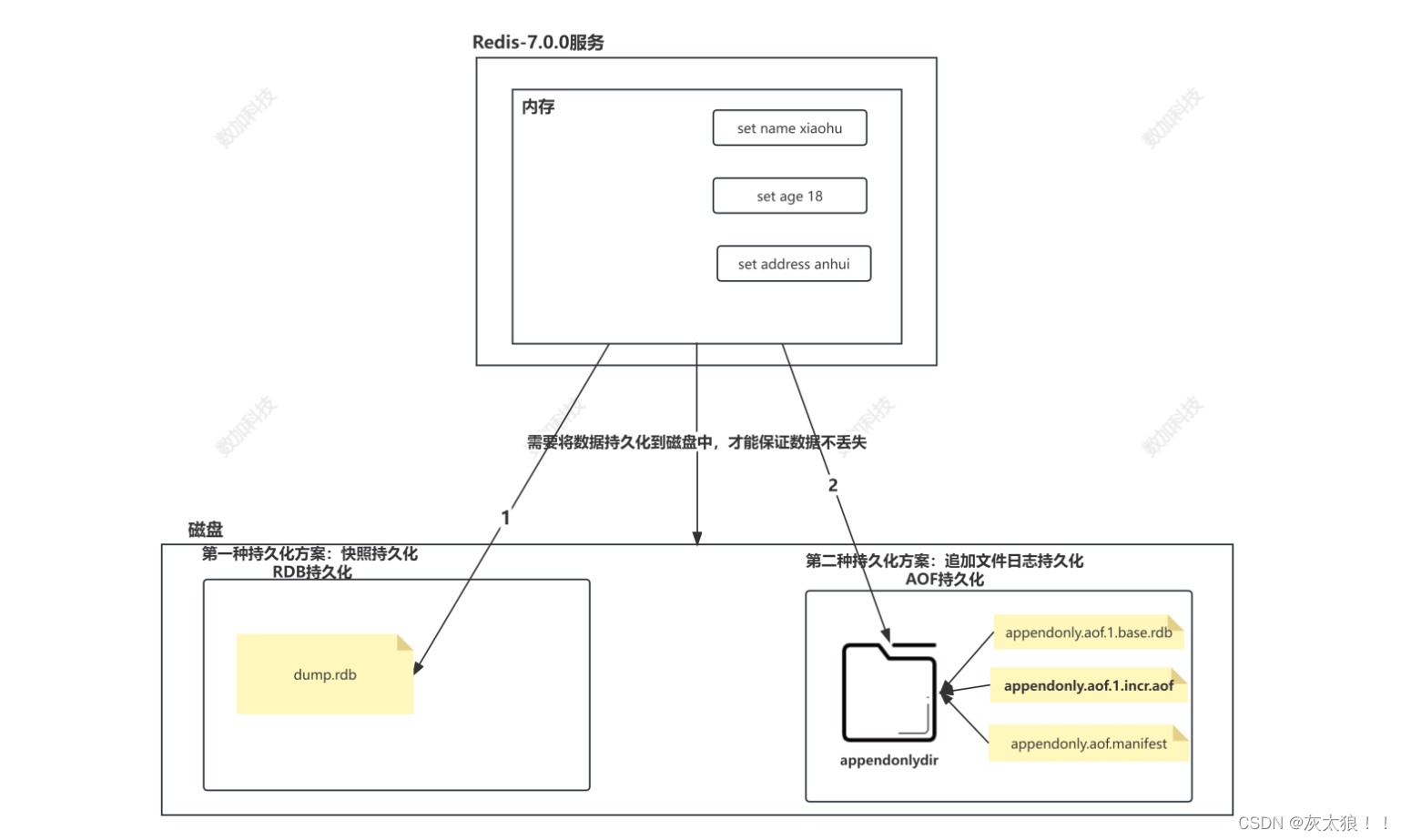
2.快照(Snapshot)
这种方式可以将某一时刻的所有数据都写入硬盘中,当然这也是redis的默认开启持久化方式,保存的文件是以.rdb形式结尾的文件因此这种方式也称之为RDB方式,官方说法叫快照持久化。
注意:默认情况下,redis服务在哪个目录下启动,哪个目录就是工作目录,后面的rdb持久化或者AOF持久化,产生的文件都存在于redis的当前工作目录下。在哪里启动就会读取哪里的快照文件
2.1.快照生成方式
(1)客户端方式: BGSAVE 和 SAVE指令
BGSAVE :客户端可以使用BGSAVE命令来创建一个快照,当接收到客户端的BGSAVE命令时,redis会调用fork来创建一个子进程,然后子进程负责将快照写入磁盘中,而父进程则继续处理命令请求

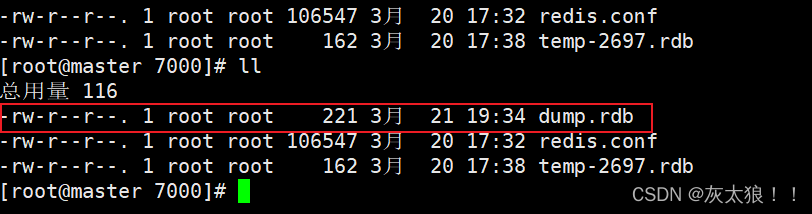
SAVE:客户端使用SAVE命令来创建一个快照,接收到SAVE命令的redis服务器在快照创建完毕之前将不再响应任何其他的命令

注意: SAVE命令并不常用,使用SAVE命令在快照创建完毕之前,redis处于阻塞状态,无法对外服务
(2)服务器配置自动触发
如果用户在redis.conf中设置了save配置选项,redis会在save选项条件满足之后自动触发一次BGSAVE命令,如果设置多个save配置选项,当任意一个save配置选项条件满足,redis也会触发一次BGSAVE命令

(3)shutdown指令
当redis通过shutdown指令接收到关闭服务器的请求时,会执行一个save命令,阻塞所有的客户端,不再执行客户端执行发送的任何命令,并且在save命令执行完毕之后关闭服务器 。
3.AOF 只追加日志文件
3.1.特点
这种方式可以将所有客户端执行的写命令记录到日志文件中,AOF持久化会将被执行的写命令写到AOF的文件末尾,以此来记录数据发生的变化,因此只要redis从头到尾执行一次AOF文件所包含的所有写命令,就可以恢复AOF文件的记录的数据集.
3.2开启AOF持久化
注意:在redis的默认配置中AOF持久化机制是没有开启的,需要在配置中开启

一旦开启AOF持久化,就会多出下图圈出的文件夹用来存放数据(redis7.0之后)
appendonlydir文件夹下有三个文件

第一个是基本的快照文件
第二个文件为增量文件,存储的是当前写操作的所有命令
第三个为校验文件,主要是校验第一个快照文件是否完整
在配置文件中我们可以看到我们在写入数据redis后台的日志追加频率

日志追加频率说明:

3.3AOF文件的重写
(1)AOF带来的问题
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。例如我们调用incr test命令100次,文件中必须保存全部的100条命令,其实有99条都是多余的。因为要恢复数据库的状态其实文件中保存一条set test 100就够了。为了压缩aof的持久化文件Redis提供了AOF重写(ReWriter)机制。
(2)AOF重写
用来在一定程度上减小AOF文件的体积,加快启动速度,并且还能保证数据不丢失
(3)重写的方式
1.客户端方式触发重写
执行BGREWRITEAOF命令,不会阻塞redis的服务
2.服务器配置方式自动触发
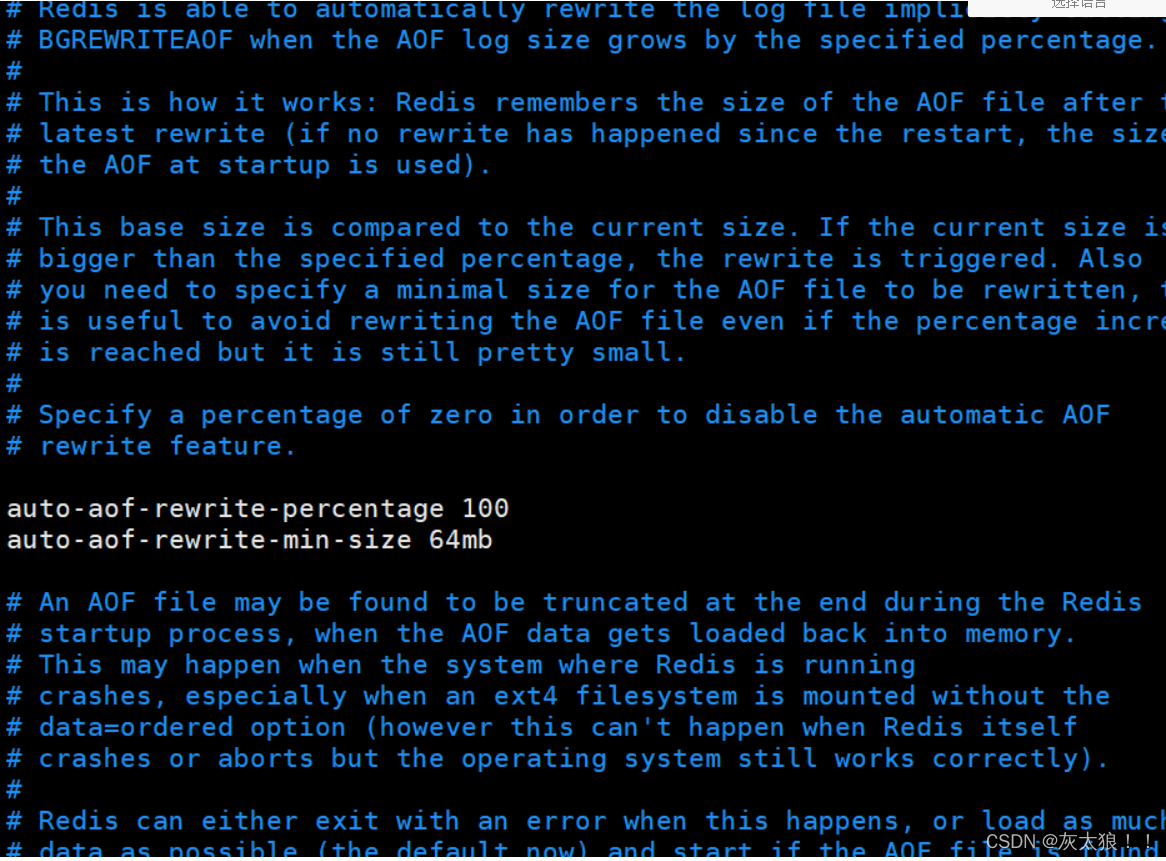
- 配置redis.conf中的auto-aof-rewrite-percentage选项
- 如果设置auto-aof-rewrite-percentage值为100和auto-aof-rewrite-min-size 64mb,并且启用的AOF持久化时,那么当AOF文件体积大于64M,并且AOF文件的体积比上一次重写之后体积大了至少一倍(100%)时,会自动触发,如果重写过于频繁,用户可以考虑将auto-aof-rewrite-percentage设置为更大
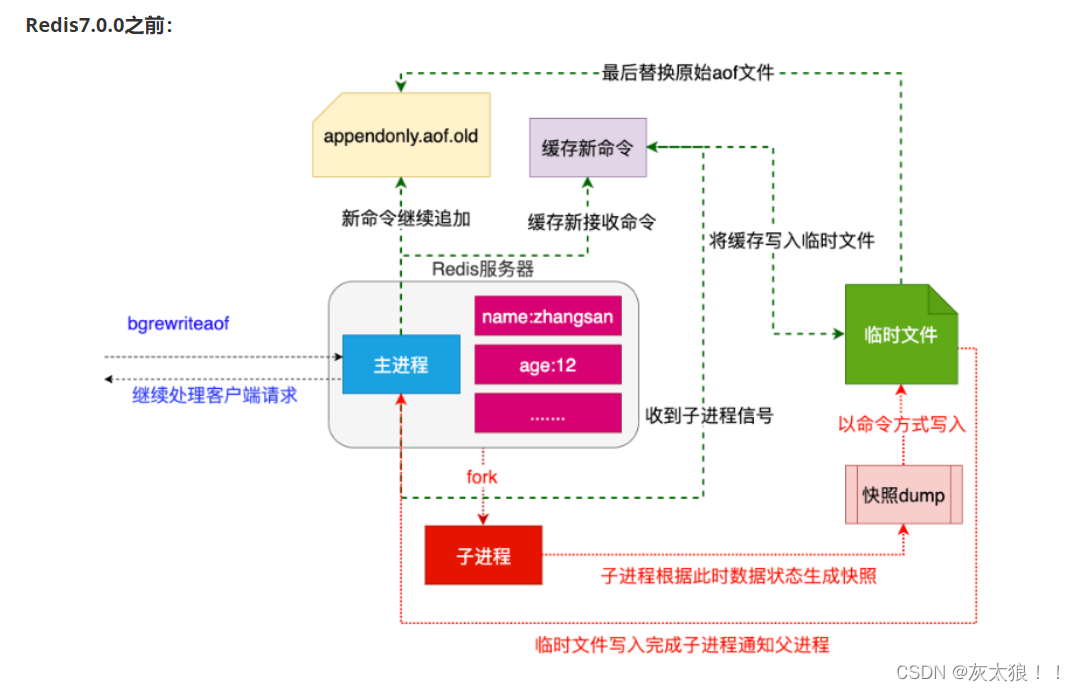
(4)日志重写
重写流程
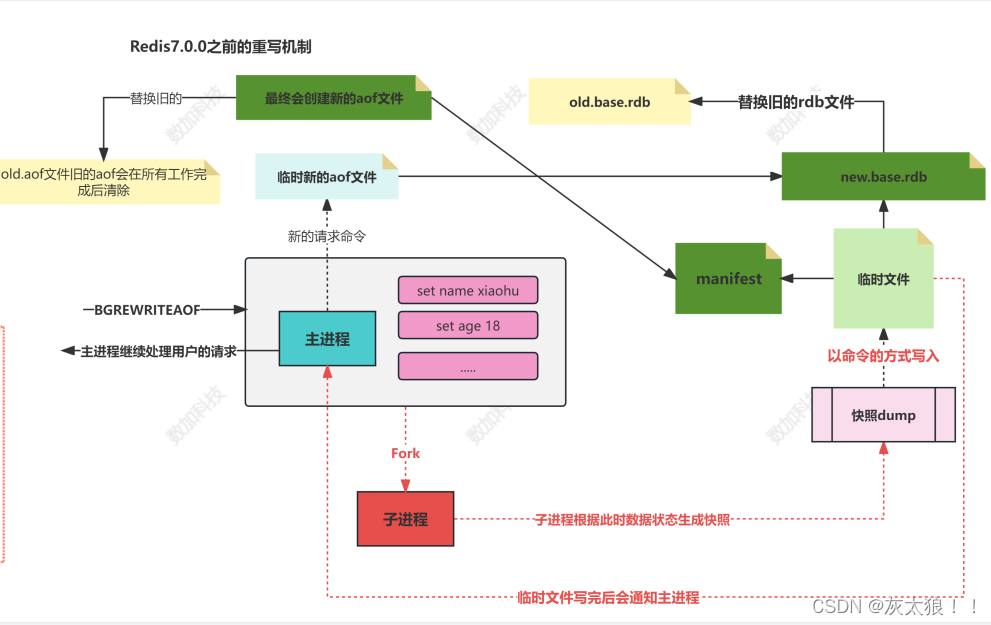
1. redis调用fork ,现在有父子两个进程 ,子进程根据内存中的数据库快照,往临时文件中写入重建数据库状态的命令
2. 父进程继续处理client请求,除了把写命令写入到原来的aof文件中。同时把收到的写命令缓存起来。这样就能保证如果子进程重写失败的话并不会出问题。
3. 当子进程把快照内容写入已命令方式写到临时文件中后,子进程发信号通知父进程。然后父进程把缓存的写命令也写入到临时文件。
4. 现在父进程可以使用临时文件替换老的aof文件,并重命名,后面收到的写命令也开始往新的aof文件中追加。
b redis7.0之后:
总结:
在7.0之前,redis使用fork生成一个父子进程,会生成一个新的AOF文件和一个临时文件,aof文件经过重写之后, 在将临时文件中的请求加入到重写后的aof文件中,最后替换原来老的aof文件。
在7.0及7.0之后,redis使用fork生成一个父子进程,会生成一个AOF的文件夹和一个临时文件,然后将旧的快照文件和旧的增量文件一起写入到临时文件中之后进行重写,同时创建一个新的容量为0的aof文件去替换老的aof文件,父进程在重写期间的请求则会被写入到这个新的aof文件中。
二.位图
1.bitmap介绍
位图不是真正的数据类型,它是定义在字符串类型中,一个字符串类型的值最多能存储512M字节的内容
2.方法:
(1)setbit 设置某一位上的值
语法:SETBIT key offset value (offset位偏移量,从0开始)
(2)getbit 获取某一位上的值
语法:GETBIT key offset
(3)bitpos 返回指定值0或者1在指定区间上首次出现的下标
语法1:BITPOS key bit [start] [end](字节索引,0表示第一个字节)
语法2 : BITPOS key bit (不指定查找范围,表示从全部内容中查找 )
语法3 : BITPOS key bit start (从start+1个字节开始查找,直到尾部)
(4)bitop位操作
语法:BITOP operation destkey key [key ...]
对一个或多个保存二进制位的字符串 key 进行位操作,并将结果保存到 destkey 上。operation 可以是 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种
BITOP AND destkey key [key ...] ,对一个或多个 key 求逻辑与,并将结果保存到 destkey
BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey
BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey
BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey
(5)bitcount统计指定位区间上值为1的个数
语法:BITCOUNT key [start] [end] start end
3.Bitmap应用场景
a.网站用户签到的天数统计
b.按天统计网站活跃用户
c.用户在线状态、在线人数统计
这篇关于Redis持久化机制与位图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






