本文主要是介绍生存分析KM简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
生存分析概念及示例代码
- 1. 以图为例介绍概念
- 1.1 基础概念
- 1.2 实际案例
- 1.3 KM曲线与临床试验关系
- 2. 学习代码
- 3. 绘制生存曲线示例
1. 以图为例介绍概念
1.1 基础概念
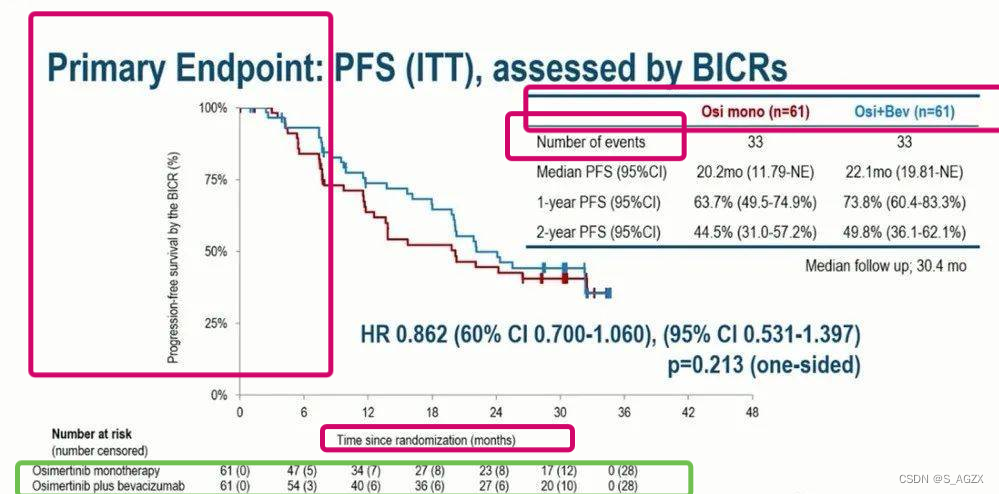
① 纵坐标(PFS)
含义:即试验的患者发生死亡/疾病进展时,认为发生了终点事件(event)。
数字:假设100个人在用药组,过了一段时间后总共有30人死亡/疾病进展,则PFS为70%
其他指标:另一个最常用的是OS,终点事件为死亡。
② 横坐标(time)
含义:随机化时间,一般指月份。
③ 图像
两个试验组,谁在上面,说明谁的疗法有效性会更好,说明病人越少、越晚发生了终点事件。
④ 主要结论—右上表
中位PFS:指某条曲线降低突破50%的时候对应的月份。
一年、二年PFS:在1年、2年这些时间节点,PFS的值。
95%CI、数据后的括号:95%的置信区间指在100次重复临床试验中,有95次结果的PFS会落在括号的区间内。更方便估测真实世界的可能结果。
⑤ 主要结论—HR及P值
HR:全称Hazard Ratio,是两个试验组风险率的比值,这个数值与时间无关,是根据一整个试验数据得出的结果。目的是,尽量客观的描述整体的生存曲线位置,而不是仅以单个时间点的PFS决定
默认情况下,HR是试验组风险/对照组风险,因此HR<1,那么就说明试验组能降低风险(试验组药效更好);HR>1,试验组提升了风险。
P值:根据回归方程(常用log-rank),通过一系列HR值,得到一个p值。p值衡大于0,p值小于0.05的时候,说明试验组药效有用。
⑥ at risk人数
在这个时间节点,未删失、未发生终点事件的人群,因为受试者尚且有发生事件的risk,因此被记录为 at risk的人数。
0(28)代表,未发生终点事件人数=0,发生删失的人数=28,发生终点事件的人数=33。
1.2 实际案例
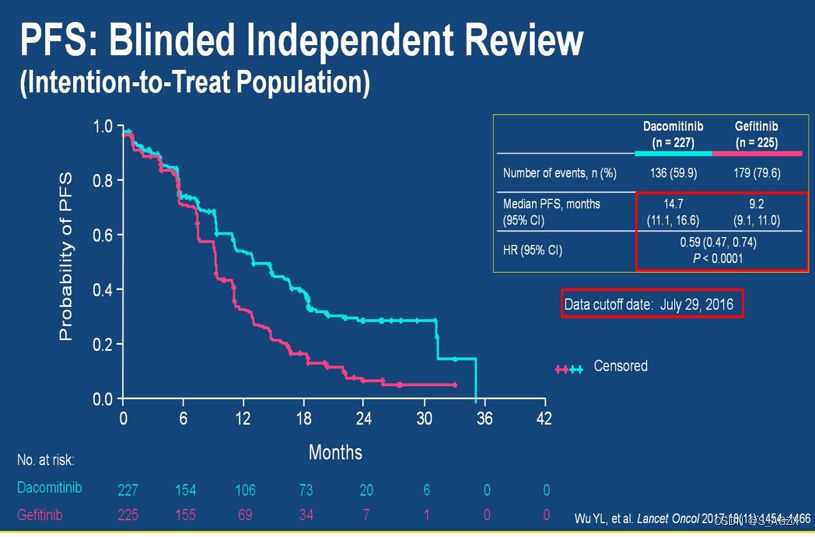
① 试验组相对于对照组的药效有极显著性差异(p<0.0001)
② 风险比(0.59)<1,95%置信区间也都<1,试验组风险率是对照组风险率的一半,说明试验组能降低终点事件发生的风险。
③ 中位PFS结果、at risk人数结果展示。
1.3 KM曲线与临床试验关系
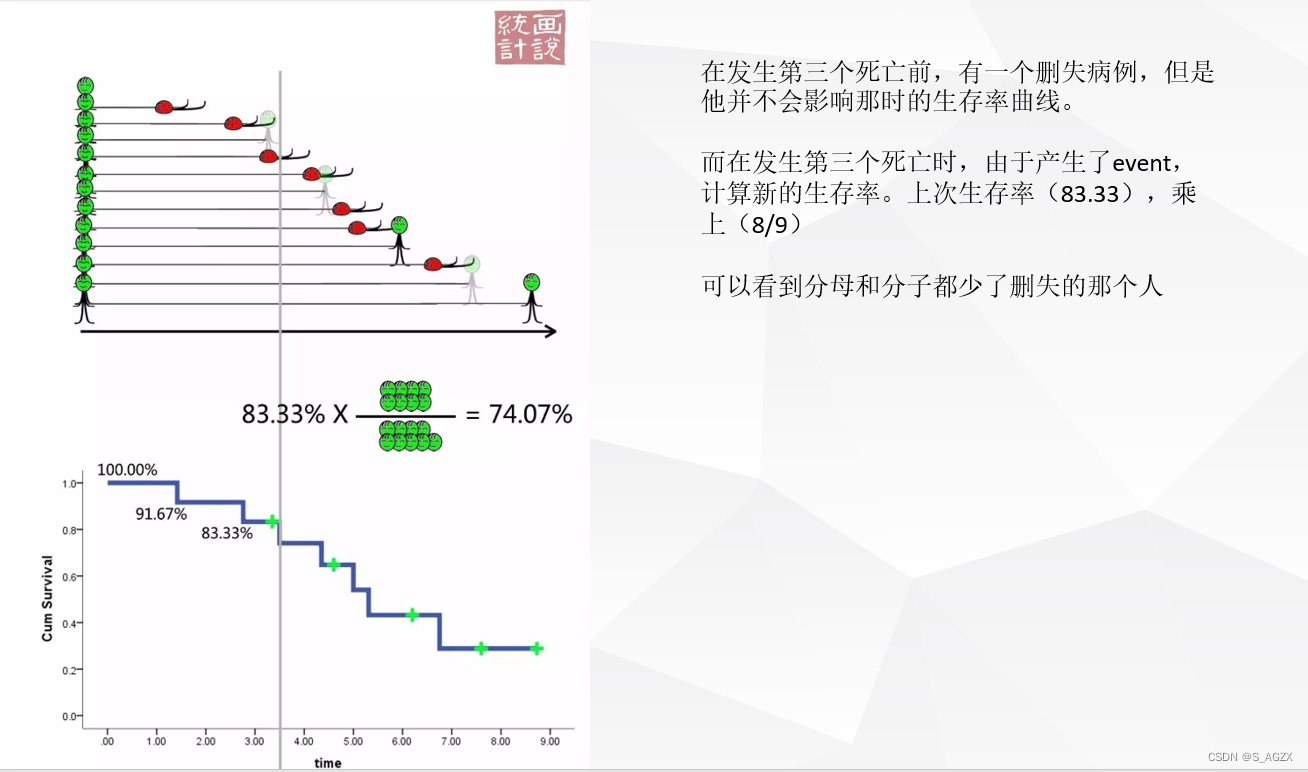
① 临床试验开展过程中,部分患者无法记录终点事件

② 临床试验以时间维度,每个患者的状态
红色死亡、+号删失、绿色代表尚未发生终点事件

③ 临床试验结果与KM曲线的对应关系
2. 学习代码
具体可按照 R语言生存曲线的可视化(超详细) 复现。
3. 绘制生存曲线示例
library("survival")
library("survminer")survival <- read.csv("survival.xls", sep = "\t", fileEncoding = "GBK")# survival示例
baseline_ddr_sample Progression=1 PFS(months) Death=1 OS(months)
1 1 8.37 1 9.57## 3.1 OS ------------------------------------------------------------------
# 创建生存对象 OS是time, progressin是event
surv_obj <- Surv(time = survival$OS.months., event = survival$Death.1)# 拟合生存曲线
fit <- survfit(surv_obj ~ baseline_ddr_sample, data = survival)
print(fit)# 查看看完整的生存表格
summary(fit)
summary(fit)$tabled <- data.frame(time = fit$time,n.risk = fit$n.risk,n.event = fit$n.event,n.censor = fit$n.censor,surv = fit$surv,upper = fit$upper,lower = fit$lower
)
head(d)#按分层更改图形颜色,线型等
ggsurvplot(fit,pval = TRUE, conf.int = TRUE,risk.table = TRUE, # 添加风险表risk.table.col = "strata", # 根据分层更改风险表颜色linetype = "strata", # 根据分层更改线型surv.median.line = "hv", # 同时显示垂直和水平参考线ggtheme = theme_bw(), # 更改ggplot2的主题palette = c("#E7B800", "#2E9FDF"), #定义颜色title = "OS of Survival Curve",xlab = "Time(Months)")## 3.2 PFS -----------------------------------------------------------------
surv_obj <- Surv(time = survival$PFS.months., event = survival$Progression.1)
fit <- survfit(surv_obj ~ baseline_ddr_sample, data = survival)d <- data.frame(time = fit$time,n.risk = fit$n.risk,n.event = fit$n.event,n.censor = fit$n.censor,surv = fit$surv,upper = fit$upper,lower = fit$lower
)
head(d)#按分层更改图形颜色,线型等
ggsurvplot(fit,pval = TRUE, conf.int = TRUE,risk.table = TRUE, # 添加风险表risk.table.col = "strata", # 根据分层更改风险表颜色linetype = "strata", # 根据分层更改线型surv.median.line = "hv", # 同时显示垂直和水平参考线ggtheme = theme_bw(), # 更改ggplot2的主题palette = c("#E7B800", "#2E9FDF"), #定义颜色title = "PFS of Survival Curve",xlab = "Time(Months)")参考文件:
(1)R语言生存曲线的可视化(超详细)
(2)一文快速看懂生存曲线(KM曲线)
这篇关于生存分析KM简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







