本文主要是介绍Golang Gorm 自动分批查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
场景:
目标查询全量数据,但需要每次Limit分批查询,保护数据库
文档:
https://gorm.io/zh_CN/docs/advanced_query.html
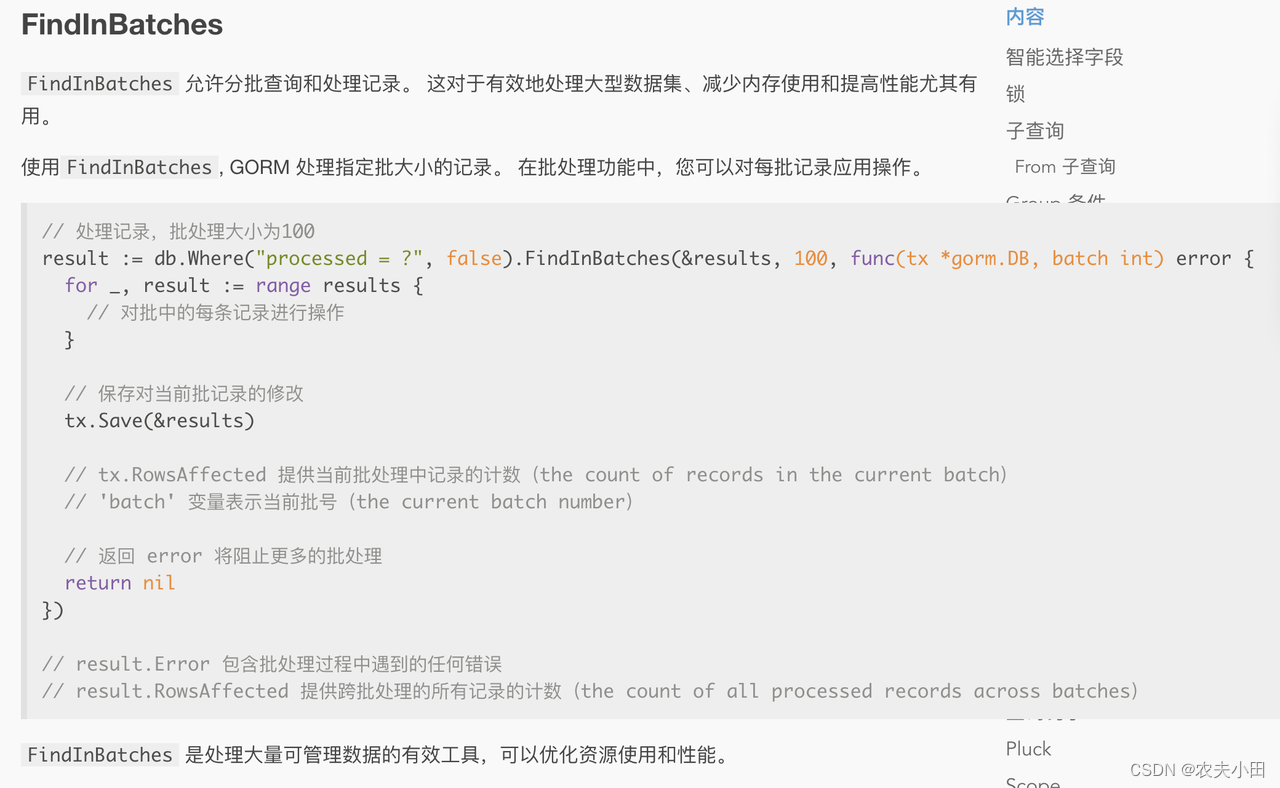
// Param:
// dest 目标地址
// batchSize 大小
// fc 处理函数func (db *DB) FindInBatches(dest interface{}, batchSize int, fc func(tx *DB, batch int) error) *DB {...}
特点:
- 按照主键ID做offset,效率高。
- 写法简单
- 可以支持对每一批查询到的记录处理
注意点:
如果目标是查询到所有结果。由于该方法每次查询到的结果会丢弃,需要手动将查询到的结果补充到外部大列表中。
records := make([]*model.Record, 0)
tempRecord := make([]*model.Record, 0)
db := client.DB(ctx).Model(&model.Record{}).Where("valid_month = ?", month)
// 每次查询500,结果拼接到records大列表
err := db.FindInBatches(&tempRecord, 500,func(tx *gorm.DB, batch int) error {records = append(records, tempRecord...)return nil}).Error
if err != nil{...}
实际执行显示:
总共1408条数据,每一批查询500个,查询三次,最后将结果拼接到大列表中。
GORM LOG SQL:SELECT* FROM record WHERE valid month=202401 ORDER BY record.id LIMIT 500 Rows:500 Cost:17.45msGORM LOG SOL:SELECT* FROM record WHERE valid month=202401 AND ban_record.id> 123123 ORDER BY record.id LIMIT 500 ROWS: 500 Cost:12.88msGORM LOG SOL:SELECT* FROM record WHERE valid month=202401 AND ban_record.id> 456456 ORDER BY record.id LIMIT 500 ROWS: 408 Cost:15.08ms这篇关于Golang Gorm 自动分批查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







