本文主要是介绍亮数据代理IP轻松解决爬虫数据采集痛点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、爬虫数据采集痛点
- 二、为什么使用代理IP可以解决?
- 2.1 爬虫和代理IP的关系
- 2.2 使用代理IP的好处
- 三、亮数据代理IP的优势
- 3.1 IP种类丰富
- 3.1.1 动态住宅代理IP
- 3.1.2 静态住宅代理IP
- 3.1.3 机房代理IP
- 3.1.4 移动代理IP
- 3.2 高质量IP全球覆盖
- 3.3 超级代理服务器加速网络
- 四、不会写爬虫代码怎么获取数据?
- 4.1 亮数据浏览器自动抓取数据
- 4.2 获取免费数据集
- 4.3 定制数据
- 五、总结
一、爬虫数据采集痛点
爬虫数据采集可能会面临一些挑战和痛点,其中包括:
-
爬虫代码维护难:网站的结构可能会经常变化,导致之前编写的爬虫无法正常工作,需要及时更新和调整爬虫代码。
-
数据量大:有些网站的数据量非常庞大,需要花费大量时间和资源来完整采集数据,同时还需要考虑数据存储和处理的问题。
-
爬虫难度大:很多网站会设置各种机制,如验证码、User-Agent检测、IP检测等,这些机制会增加爬虫的难度。
-
频率限制: 无法高效采集公开数据
二、为什么使用代理IP可以解决?
2.1 爬虫和代理IP的关系
爬虫和代理IP之间的关系密切,代理IP可以安全采集公开数据信息,保证爬虫的持续运行和数据采集。
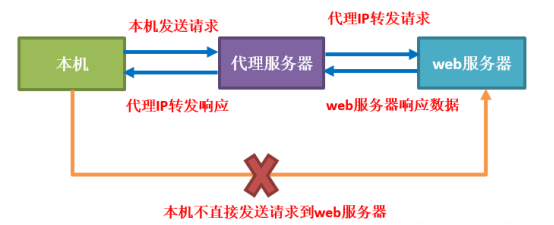
2.2 使用代理IP的好处
使用代理IP可以带来以下好处:
- 匿名保护,保护隐私安全
- 安全采集公开数据信息
- 分散访问压力,提高爬取效率和稳定性。
- 收集不同地区或代理服务器上的数据,用于数据分析和对比。
然而,使用代理IP也存在一些挑战和注意事项:
-
IP安全性低,无法高效采集公开数据。
-
使用代理IP可能增加网络请求的延迟和复杂性,需要合理配置和调整爬虫程序。
-
使用代理IP需要遵守相关法律法规和目标网站的使用规则,不得进行非法活动或滥用代理IP服务。
博主最近使用的是亮数据家的代理IP,IP质量很高个人感觉还不错:亮数据官网
三、亮数据代理IP的优势
3.1 IP种类丰富
亮数据代理IP有四种不同的代理IP套餐可以满足不同的代理需求:亮数据官网

3.1.1 动态住宅代理IP
优点:
- 隐匿性强:因为是住宅网络的IP地址,难以被识别为代理IP,有利于匿名保护隐私安全。
- 定时更新:动态IP会定期或在连接重新建立时更换,高效采集公开数据。

3.1.2 静态住宅代理IP
优点:
- 稳定性高:与动态IP相比,静态IP地址不会经常变动,因此更稳定,适用于需要持续稳定连接的应用场景。
- 隐私安全:静态IP通常更难被目标网站或服务商识别为代理IP,匿名保护隐私安全。

3.1.3 机房代理IP
优点:
- 高速稳定:机房代理IP通常来自于数据中心或服务器托管商,具有高速稳定的网络连接,适用于对速度和稳定性有较高要求的应用场景。
- 多样化选择:机房代理IP的来源多样,可以选择适合需求的地理位置和网络服务商。

3.1.4 移动代理IP
优点:
- 覆盖广泛:移动代理IP来源于移动运营商,覆盖范围广泛,适用于需要涉及多个地理位置的应用场景。
- 动态性强:类似于动态住宅代理IP,移动代理IP通常具有动态分配的特点,IP地址会定期变更,有助于匿名保护隐私安全。

选择何种代理IP取决于具体的使用场景和需求,例如,对于需要稳定性的任务可能更适合静态住宅代理IP或机房代理IP,而对于需要隐匿性和灵活性的任务可能更适合动态住宅代理IP或移动代理IP。
3.2 高质量IP全球覆盖
亮数据在全球超过7200万的动态和静态IP,自创系统内嵌精准算法,设置IP平衡加载功能,保证IP数量充足的同时,确保IP高匿性和优质性。这些IP经过精心选择和合理布局,涵盖了全球各个地区和网络运营商,能够满足用户在不同地域和网络环境下的需求。每月IP更新量高达百万,保证了IP库的时效性和多样性,用户可以始终获取到最新、最稳定的IP资源。此外,系统采用先进的技术手段,确保IP的高度匿名性,用户的真实身份和位置得到有效保护,同时提供稳定、高速的网络连接,为用户的网络活动提供可靠支持。

3.3 超级代理服务器加速网络
亮数据在全球各国精心布局超过2600个超级代理服务器,这些服务器组成了覆盖全网的智能交通枢纽。这些枢纽不仅仅是简单的中转站,而是配备了先进的智能算法和强大的处理能力,能够根据代理请求的位置、类型、大小以及目标网站等多种要素,实现快速而精准的分流。这意味着无论用户身处何地,无论访问何种类型的网站,都能够快速连接到最近的IP,并享受稳定、高速的网络体验。这种智能化的代理网络极大地提升了用户的访问效率,同时也保证了网络连接的稳定性和安全性,为用户提供了一个强大而可信赖的代理服务平台。

四、不会写爬虫代码怎么获取数据?
4.1 亮数据浏览器自动抓取数据
亮数据浏览器是一款强大的自动化爬虫工具,可以实现自动解锁网站,为不会写代码的用户提供便捷的操作。
1、点击免费试用:

2、点击开始使用:

3、自定义通道:
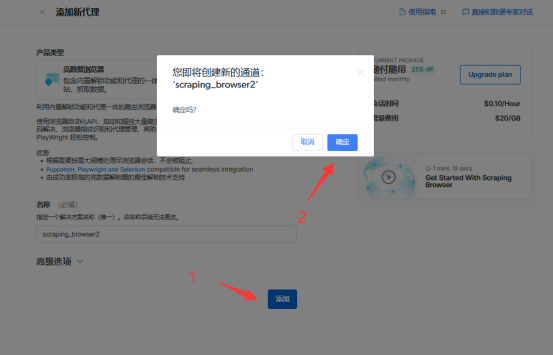
4、点击查看代码集成示例:

5、输入目标网站和选择国家:

6、安装亮数据的第三方Python模块:
pip3 install playwright

7、复制案例代码去Python编辑器中运行

运行成功:
4.2 获取免费数据集
1、进入亮数据官网,点击网络数据,然后点击获取获取免费样本:https://www.bright.cn

2、输入好个人信息和需要的数据集名称后,点击提交:
然后等着客服免费送数据集就可以了。
4.3 定制数据
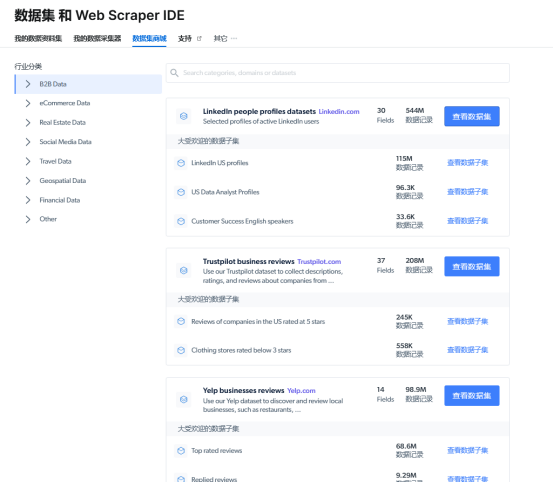
在亮数据数据商城中有各种数据集供大家下载使用,并且可以定制数据集:
五、总结
代理IP对于爬虫是密不可分的,但使用代理IP需要遵守相关法律法规和目标网站的使用规则,不得进行非法活动或滥用代理IP服务,亮数据家的高质量代理IP可以帮助爬虫安全采集公开数据信息,有需要代理IP的小伙伴可以试试。
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
-
折扣代码:yuanman
-
访问页面:https://www.bright.cn/proxy-types/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_yuanman&promo=yuanman
如有问题,可以关“Bright_Data”注亮数据官微,联系后台客服。
这篇关于亮数据代理IP轻松解决爬虫数据采集痛点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!